В этом примере показано, как создать классификаторы машины опорных векторов (SVM) в приложении Classification Learner, с помощью ionosphere набор данных, который содержит два класса. Можно использовать машину опорных векторов (SVM) с двумя или больше классами в Classification Learner. SVM классифицирует данные путем нахождения лучшей гиперплоскости, которая разделяет все точки данных одного класса от тех из другого класса. В ionosphere данные, переменная отклика является категориальной с двумя уровнями: g представляет хороший радар, возвращается, и b представляет плохой радар, возвращается.
В MATLAB®, загрузите ionosphere набор данных и задает некоторые переменные из набора данных, чтобы использовать для классификации.
load ionosphere
ionosphere = array2table(X);
ionosphere.Group = Y;В качестве альтернативы можно загрузить ionosphere набор данных и сохраняет X и Y данные как отдельные переменные.
На вкладке Apps, в группе Machine Learning and Deep Learning, нажимают Classification Learner.
На вкладке Classification Learner, в разделе File, нажимают New Session > From Workspace.

В диалоговом окне New Session from Workspace выберите таблицу ionosphere из списка Data Set Variable. Заметьте, что приложение выбрало ответ и переменные предикторы на основе их типа данных. Переменная отклика Group имеет два уровня. Все другие переменные являются предикторами.
В качестве альтернативы, если вы сохранили свои данные о предикторе X и переменная отклика Y как две отдельные переменные, можно сначала выбрать матричный X из списка Data Set Variable. Затем под Response кликните по переключателю From workspace и выберите Y из списка. Y переменная совпадает с Group переменная.
Нажмите Start Session.
Classification Learner создает график рассеивания данных.
Используйте график рассеивания, чтобы визуализировать, какие переменные полезны для предсказания ответа. Выберите различные переменные в средствах управления X-и Осью Y. Наблюдайте, какие переменные разделяют цвета класса наиболее ясно.
Чтобы создать выбор моделей SVM, на вкладке Classification Learner, в разделе Model Type, кликают по стрелке вниз, чтобы расширить список классификаторов, и под Support Vector Machines, нажать All SVMs.
 Затем нажмите Train.
Затем нажмите Train. ![]()
Совет
Если у вас есть Parallel Computing Toolbox™, можно обучить все модели (All SVMs) одновременно путем нажатия кнопки Use Parallel в разделе Training перед нажатием Train. После того, как вы нажимаете Train, диалоговое окно Opening Parallel Pool открывается и остается открытым, в то время как приложение открывает параллельный пул рабочих. В это время вы не можете взаимодействовать с программным обеспечением. После того, как пул открывается, приложение обучает модели одновременно.
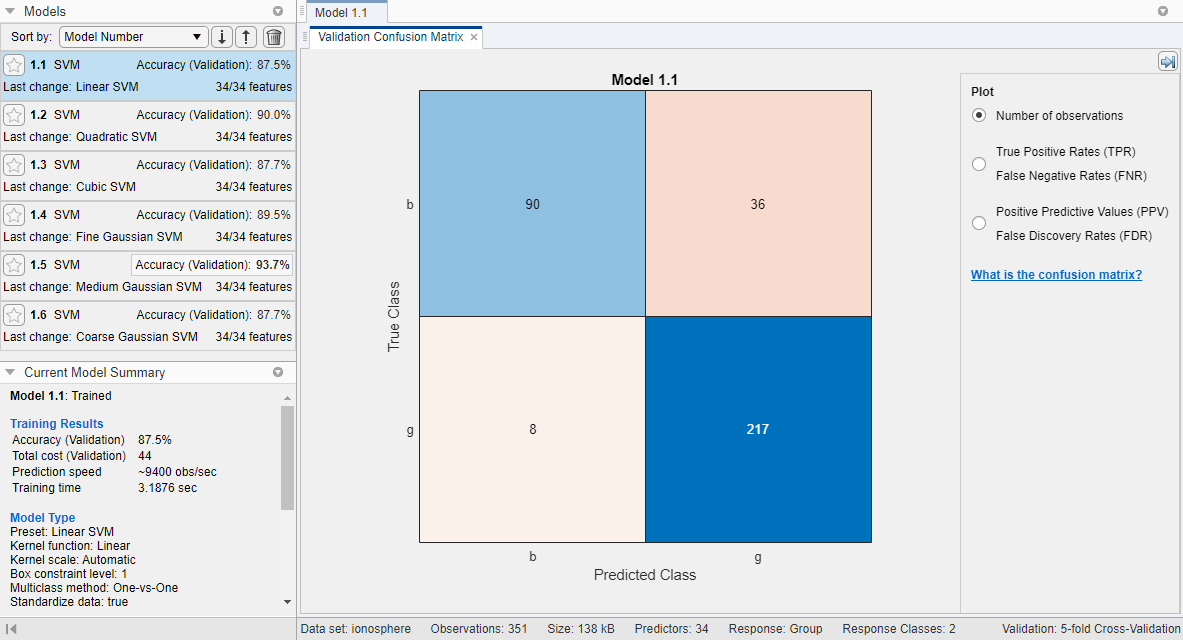
Classification Learner обучает одну из каждой nonoptimizable опции классификации SVM в галерее и подсвечивает лучший счет. Приложение обрисовывает в общих чертах в поле счет Accuracy (Validation) лучшей модели. Classification Learner также отображает матрицу беспорядка валидации для первой модели SVM (Linear SVM).
Примечание
Валидация вводит некоторую случайность в результаты. Ваши результаты проверки допустимости модели могут варьироваться от результатов, показанных в этом примере.
Чтобы просмотреть результаты для модели, выберите модель в панели Models и смотрите панель Current Model Summary. Панель Current Model Summary отображает метрики Training Results, вычисленные на набор валидации.
Для выбранной модели смотрите точность предсказаний в каждом классе. На вкладке Classification Learner, в разделе Plots, кликают по стреле, чтобы открыть галерею, и затем нажать Confusion Matrix (Validation) в группе Validation Results. Просмотрите матрицу истинного класса и предсказанных результатов класса.
Выберите другие модели в панели Models, откройте матрицу беспорядка валидации для каждой из моделей, и затем сравните результаты.
Выберите лучшую модель (лучший счет подсвечен в поле). Чтобы улучшить модель, попробуйте включая различные функции в модели. Смотрите, можно ли улучшить модель путем удаления функций с низкой предсказательной силой.
На вкладке Classification Learner, в разделе Features, нажимают Feature Selection. В диалоговом окне Feature Selection задайте предикторы, чтобы удалить из модели и нажать OK. В разделе Training нажмите Train, чтобы обучить новую модель с помощью новых опций. Сравните результаты среди классификаторов в панели Models.
Чтобы исследовать функции, чтобы включать или исключить, используйте параллельный график координат. На вкладке Classification Learner, в разделе Plots, кликают по стреле, чтобы открыть галерею и нажать Parallel Coordinates в группе Validation Results.
Выберите лучшую модель в панели Models. Чтобы попытаться улучшить модель далее, попытайтесь изменить настройки SVM. На вкладке Classification Learner, в разделе Model Type, нажимают Advanced. В Усовершенствованном Окне параметров SVM попытайтесь изменить настройки и нажмите OK. Обучите новую модель путем нажатия на Train в разделе Training. Для получения информации о настройках смотрите Машины опорных векторов.
Можно экспортировать полную или компактную версию обученной модели к рабочей области. На вкладке Classification Learner, в разделе Export, нажимают Export Model и выбирают Export Model или Export Compact Model. См. Модель Классификации Экспорта, чтобы Предсказать Новые Данные.
Чтобы исследовать код на обучение этот классификатор, нажмите Generate Function. Для моделей SVM см., также Генерируют код С для Предсказания.
Используйте тот же рабочий процесс, чтобы оценить и сравнить другие типы классификатора, которые можно обучить в Classification Learner.
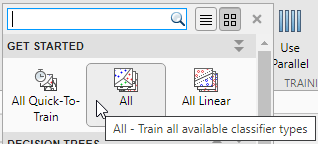
Попробовать все nonoptimizable предварительные установки модели классификатора, доступные для вашего набора данных:
Кликните по стреле на ультраправом из раздела Model Type, чтобы расширить список классификаторов.
Нажмите All, затем нажмите Train.
Чтобы узнать о других типах классификатора, смотрите, Обучают Модели Классификации в Приложении Classification Learner.
