Первый шаг создания и обучения новой сверточной нейронной сети (ConvNet) должен задать сетевую архитектуру. Эта тема объясняет детали слоев ConvNet и порядок, они появляются в ConvNet. Для полного списка слоев глубокого обучения и как создать их, смотрите Список слоев глубокого обучения. Чтобы узнать о сетях LSTM для классификации последовательностей и регрессии, смотрите Длинные Краткосрочные Сети Памяти. Чтобы изучить, как создать ваши собственные слои, смотрите, Задают Пользовательские Слои Глубокого обучения.
Сетевая архитектура может отличаться в зависимости от типов и количеств включенных слоев. Типы и количество включенных слоев зависят от конкретного приложения или данных. Например, если у вас есть категориальные ответы, у вас должны быть softmax слой и слой классификации, тогда как, если ваш ответ непрерывен, у вас должен быть слой регрессии в конце сети. Меньшая сеть только с одним или двумя сверточными слоями может быть достаточной, чтобы учиться на небольшом количестве данных о полутоновом изображении. С другой стороны, для более комплексных данных с миллионами цветных изображений, вам может быть нужна более сложная сеть с несколькими сверточными и полносвязные слоя.
Чтобы задать архитектуру глубокой сети со всеми слоями, соединенными последовательно, создайте массив слоев непосредственно. Например, чтобы создать глубокую сеть, которая классифицирует 28 28 полутоновые изображения в 10 классов, задайте массив слоя
layers = [
imageInputLayer([28 28 1])
convolution2dLayer(3,16,'Padding',1)
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,'Stride',2)
convolution2dLayer(3,32,'Padding',1)
batchNormalizationLayer
reluLayer
fullyConnectedLayer(10)
softmaxLayer
classificationLayer];layers является массивом объектов Layer. Можно затем использовать layers в качестве входа к учебному функциональному trainNetwork.Чтобы задать архитектуру нейронной сети со всеми слоями, соединенными последовательно, создайте массив слоев непосредственно. Чтобы задать архитектуру сети, где слои могут иметь несколько вводов или выводов, используйте объект LayerGraph.
Создайте входной слой изображений с помощью imageInputLayer.
Изображение ввело входные изображения слоя к сети, и применяет нормализацию данных.
Задайте размер изображения с помощью аргумента inputSize. Размер изображения соответствует высоте, ширине и количеству цветовых каналов того изображения. Например, для полутонового изображения, количество каналов равняется 1, и для цветного изображения это 3.
2D сверточный слой применяет скользящие сверточные фильтры к входу. Создайте 2D сверточный слой с помощью convolution2dLayer.
Сверточный слой состоит из различных компонентов. [1]
Сверточный слой состоит из нейронов, которые соединяются с подобластями входных изображений или выходными параметрами предыдущего слоя. Слой изучает функции, локализованные этими областями при сканировании через изображение. При создании слоя с помощью функции convolution2dLayer можно задать размер этих областей с помощью входного параметра filterSize.
Для каждой области функция trainNetwork вычисляет скалярное произведение весов и входа, и затем добавляет срок смещения. Набор весов, который применяется к области в изображении, называется фильтром. Фильтр проходит входное изображение вертикально и горизонтально, повторяя то же вычисление для каждой области. Другими словами, фильтр применяет операцию свертки к входу.
Это изображение показывает 3х3 сканирование фильтра через вход. Более низкая карта представляет вход, и верхняя карта представляет вывод.
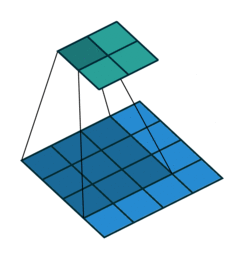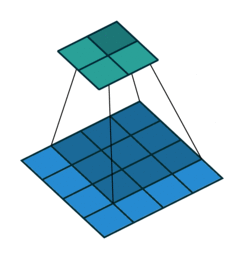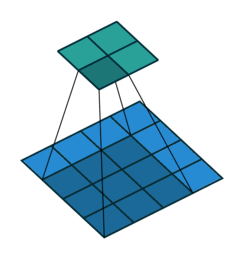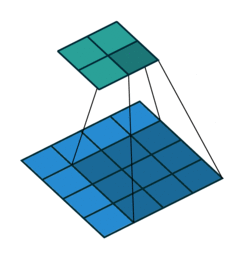
Размер шага, с которым перемещается фильтр, называется шагом. Можно задать размер шага с аргументом пары "имя-значение" Stride. Локальные области, с которыми соединяются нейроны, могут наложиться в зависимости от значений 'Stride' и filterSize.
Это изображение показывает 3х3 сканирование фильтра через вход шагом 2. Более низкая карта представляет вход, и верхняя карта представляет вывод.
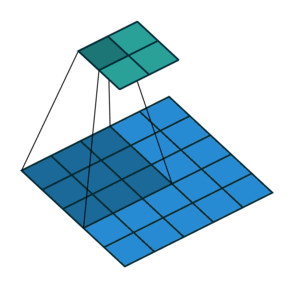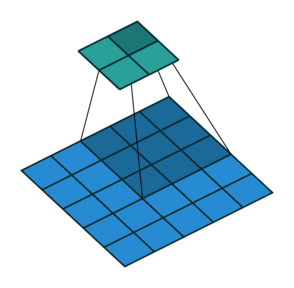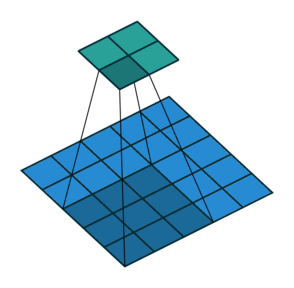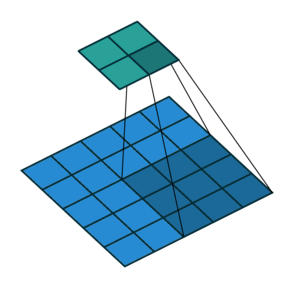
Количеством весов в фильтре является h * w * c, где h является высотой, и w является шириной фильтра, соответственно, и c является количеством каналов во входе. Например, если вход является цветным изображением, количество цветовых каналов равняется 3. Количество фильтров определяет количество каналов в выводе сверточного слоя. Задайте количество фильтров с помощью аргумента numFilters с функцией convolution2dLayer.
Расширенная свертка является сверткой, в которой фильтры расширены пробелами, вставленными между элементами фильтра. Задайте фактор расширения использование свойства 'DilationFactor'.
Используйте расширенные свертки, чтобы увеличить восприимчивое поле (область входа, который слой видит) слоя, не увеличивая число параметров или вычисления.
Слой расширяет фильтры путем вставки нулей между каждым элементом фильтра. Фактор расширения определяет размер шага для выборки входа или эквивалентно фактора повышающей дискретизации фильтра. Это соответствует эффективному размеру фильтра (Filter Size – 1).* Dilation Factor + 1. Например, 3х3 фильтр с фактором расширения [2 2] эквивалентен фильтру 5 на 5 с нулями между элементами.
Это изображение показывает 3х3 фильтр, расширенный фактором двух сканирований через вход. Более низкая карта представляет вход, и верхняя карта представляет вывод.
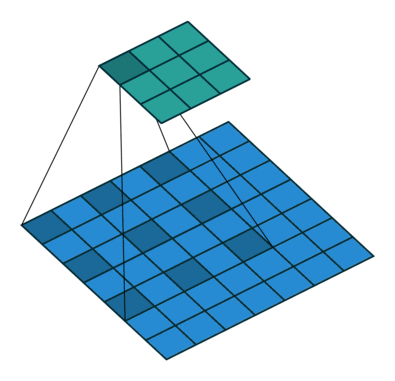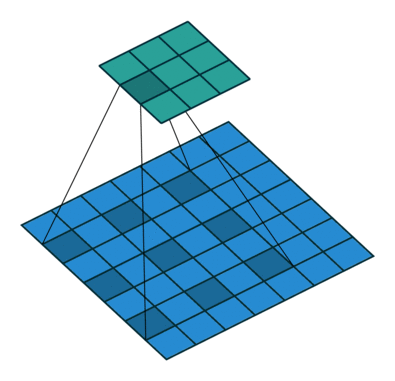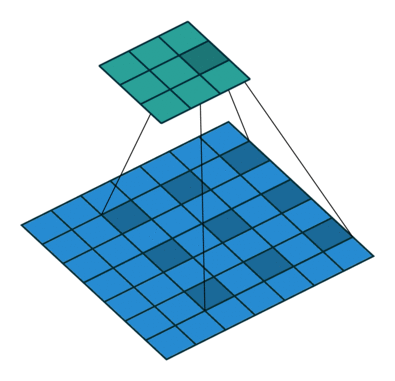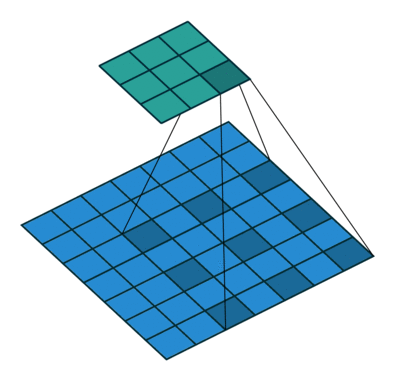
Когда фильтр проходит вход, он использует тот же набор весов и то же смещение для свертки, формируя карту функции. Каждая карта функции является результатом свертки с помощью различного набора весов и различного смещения. Следовательно, количество карт функции равно количеству фильтров. Общее количество параметров в сверточном слое ((h *w*c + 1) *Number of Filters), где 1 смещение.
Можно также применить нулевое дополнение, чтобы ввести цвета границы изображения вертикально и горизонтально использование аргумента пары "имя-значение" 'Padding'. Дополнение является строками или столбцами нулей, добавленных к границам входа изображений. Путем корректировки дополнения можно управлять выходным размером слоя.
Это изображение показывает 3х3 сканирование фильтра через вход с дополнением размера 1. Более низкая карта представляет вход, и верхняя карта представляет вывод.
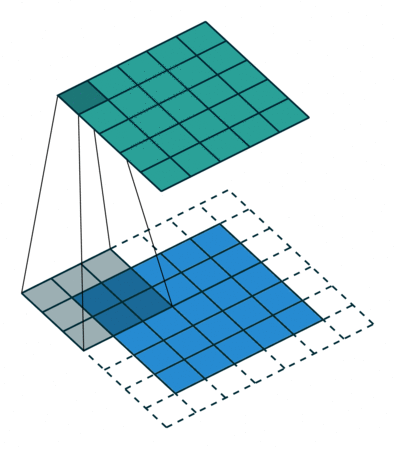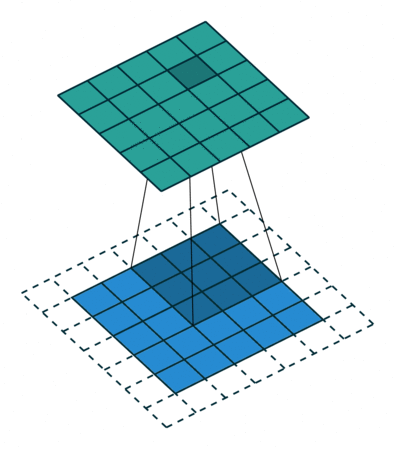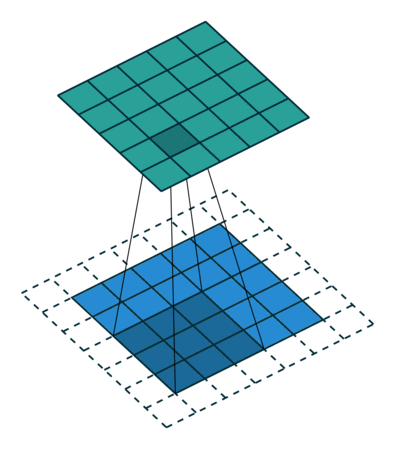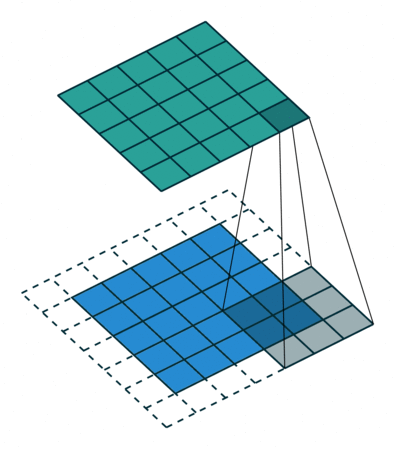
Выходная высота и ширина сверточного слоя (Input Size – ((Filter Size – 1) *Dilation Factor + 1) + 2*Padding)/Stride + 1. Это значение должно быть целым числом для целого изображения, которое будет полностью покрыто. Если комбинация этих опций не приводит изображение быть полностью покрытым, программное обеспечение по умолчанию игнорирует остающуюся часть изображения вдоль правых краев и базовых краев в свертке.
Продукт выходной высоты и ширины дает общее количество нейронов в карте функции, скажите Map Size. Общим количеством нейронов (выходной размер) в сверточном слое является Map Size *Number of Filters.
Например, предположите, что входное изображение является 32 32 3 цветными изображениями. Для сверточного слоя с восемью фильтрами и размером фильтра 5 на 5, количество весов на фильтр равняется 5 * 5 * 3 = 75, и общее количество параметров в слое (75 + 1) * 8 = 608. Если шаг 2 в каждом направлении, и дополнение размера 2 задано, то каждая карта функции 16 16. Это вызвано тем, что (32 – 5 + 2 * 2)/2 + 1 = 16.5, и часть наиболее удаленного нулевого дополнения направо и нижней части изображения отбрасывается. Наконец, общее количество нейронов в слое равняется 16 * 16 * 8 = 2048.
Обычно, результаты этих нейронов проходят через некоторую форму нелинейности, такой как исправленные линейные модули (ReLU).
Можно настроить темпы обучения и опции регуляризации для аргументов пары "имя-значение" использования слоя при определении сверточного слоя. Если вы принимаете решение не задать эти опции, то trainNetwork использует глобальные опции обучения, заданные с функцией trainingOptions. Для получения дополнительной информации на глобальной переменной и опциях обучения слоя, смотрите Настроенные Параметры и Обучите Сверточную Нейронную сеть.
Сверточная нейронная сеть может состоять из один или несколько сверточных слоев. Количество сверточных слоев зависит от суммы и сложности данных.
Создайте пакетный слой нормализации с помощью batchNormalizationLayer.
Пакетный слой нормализации нормирует каждый входной канал через мини-пакет. Чтобы ускорить обучение сверточных нейронных сетей и уменьшать чувствительность к сетевой инициализации, используйте пакетные слои нормализации между сверточными слоями и нелинейностью, такой как слои ReLU.
Слой сначала нормирует активации каждого канала путем вычитания мини-пакетного среднего значения и деления на мини-пакетное стандартное отклонение. Затем слой переключает вход learnable смещением β и масштабирует его learnable масштабным коэффициентом γ. β и γ являются самостоятельно learnable параметрами, которые обновляются во время сетевого обучения.
Пакетные слои нормализации нормируют распространение активаций и градиентов через нейронную сеть, делая сетевое обучение более легкой задачей оптимизации. Чтобы в полной мере воспользоваться этим фактом, можно попытаться увеличить темп обучения. Поскольку задача оптимизации легче, обновления параметра могут быть больше, и сеть может учиться быстрее. Можно также попытаться уменьшать регуляризация уволенного и L2. С пакетными слоями нормализации зависят активации определенного изображения во время обучения, на котором изображения, оказывается, появляются в том же мини-пакете. Чтобы в полной мере воспользоваться этим эффектом упорядочивания, попытайтесь переставить данные тренировки перед каждой учебной эпохой. Чтобы задать, как часто переставить данные во время обучения, используйте аргумент пары "имя-значение" 'Shuffle' trainingOptions.
Создайте слой ReLU с помощью reluLayer.
Слой ReLU выполняет пороговую операцию к каждому элементу входа, где любое значение меньше, чем нуль обнуляется.
Сверточные и пакетные слои нормализации обычно сопровождаются нелинейной функцией активации, такой как исправленный линейный модуль (ReLU), заданный слоем ReLU. Слой ReLU выполняет пороговую операцию к каждому элементу, где любое входное значение меньше, чем нуль обнуляется, то есть,
Слой ReLU не изменяет размер своего входа.
Существуют другие нелинейные слои активации, которые выполняют различные операции и могут улучшить сетевую точность для некоторых приложений. Для списка слоев активации смотрите Слои Активации.
Создайте межканальный слой нормализации с помощью crossChannelNormalizationLayer.
Мудрый каналом локальный ответ (межканальный) слой нормализации выполняет мудрую каналом нормализацию.
Этот слой выполняет мудрую каналом локальную нормализацию ответа. Это обычно следует за слоем активации ReLU. Этот слой заменяет каждый элемент на нормированное значение, это получает использование элементов из определенного числа соседних каналов (элементы в окне нормализации). Таким образом, для каждого элемента во входе trainNetwork вычисляет нормированное значение использование
где K, α и β являются гиперпараметрами в нормализации, и ss является суммой квадратов элементов в окне [2] нормализации. Необходимо задать размер окна нормализации с помощью аргумента windowChannelSize функции crossChannelNormalizationLayer. Можно также задать гиперпараметры с помощью Alpha, Beta и аргументов пары "имя-значение" K.
Предыдущая формула нормализации немного отличается, чем, что представлено в [2]. Можно получить эквивалентную формулу путем умножения значения alpha на windowChannelSize.
Макс. слой объединения выполняет субдискретизацию путем деления входа на прямоугольные области объединения и вычисления максимума каждой области. Создайте макс. слой объединения с помощью maxPooling2dLayer.
Средний слой объединения выполняет субдискретизацию путем деления входа на прямоугольные области объединения и вычисление средних значений каждой области. Создайте средний слой объединения с помощью averagePooling2dLayer.
Объединяющие слои следуют за сверточными слоями для субдискретизации, следовательно, сокращая количество связей со следующими слоями. Они не выполняют изучения себя, но сокращают количество параметров, которые будут изучены в следующих слоях. Они также помогают уменьшать сверхподбор кривой.
Макс. слой объединения возвращает максимальные значения прямоугольных областей его входа. Размер прямоугольных областей определяется аргументом poolSize maxPoolingLayer. Например, если poolSize равняется [2,3], то слой возвращает максимальное значение в областях высоты 2 и ширина 3.
Средний слой объединения выводит средние значения прямоугольных областей его входа. Размер прямоугольных областей определяется аргументом poolSize averagePoolingLayer. Например, если poolSize [2,3], то слой возвращает среднее значение областей высоты 2 и ширина 3.
Объединение слоев сканирует через вход горизонтально, и вертикально в размерах шага можно задать использование аргумента пары "имя-значение" 'Stride'. Если размер пула меньше, чем или равен шагу, то области объединения не накладываются.
Для неперекрывающихся областей (Pool Size и Stride равны), если входом к слою объединения является n-by-n, и размером области объединения является h-by-h, то слой объединения субдискретизирует области h [6]. Таким образом, выводом макс. или среднего слоя объединения для одного канала сверточного слоя является n/h-by-n/h. Для перекрывающихся областей вывод слоя объединения (Input Size – Pool Size + 2*Padding)/Stride + 1.
Создайте слой уволенного с помощью dropoutLayer.
Слой уволенного случайным образом обнуляет входные элементы с данной вероятностью.
В учебное время слой случайным образом обнуляет входные элементы, данные маской уволенного rand(size(X))<Probability, где X является входом слоя и затем масштабирует остающиеся элементы 1/(1-Probability). Эта операция эффективно изменяет базовую сетевую архитектуру между итерациями и помогает препятствовать тому, чтобы сеть сверхсоответствовала [7], [2]. Более высокий номер приводит к большему количеству элементов, уроненных во время обучения. Во время прогноза вывод слоя равен своему входу.
Подобно макс. или средним слоям объединения никакое изучение не происходит в этом слое.
Создайте полносвязный слой с помощью fullyConnectedLayer.
Полносвязный слой умножает вход на матрицу веса и затем добавляет вектор смещения.
Сверточные (и субдискретизирующий) слои сопровождаются одним или несколькими полносвязными слоями.
Как следует из названия, все нейроны в полносвязном слое соединяются со всеми нейронами в предыдущем слое. Этот слой сочетает все функции (локальная информация) изученный предыдущими слоями через изображение, чтобы идентифицировать большие шаблоны. Для проблем классификации последний полносвязный слой сочетает функции, чтобы классифицировать изображения. Это - причина, что аргумент outputSize последнего полносвязного слоя сети равен количеству классов набора данных. Для проблем регрессии выходной размер должен быть равен количеству переменных отклика.
Можно также настроить темп обучения и параметры регуляризации для этого слоя с помощью связанных аргументов пары "имя-значение" при создании полносвязного слоя. Если вы принимаете решение не настроить их, то trainNetwork использует глобальные учебные параметры, заданные функцией trainingOptions. Для получения дополнительной информации на глобальной переменной и опциях обучения слоя, смотрите Настроенные Параметры и Обучите Сверточную Нейронную сеть.
Полносвязный слой умножает вход на матрицу веса W и затем добавляет вектор смещения b.
Если вход к слою является последовательностью (например, в сети LSTM), то полносвязный слой действует независимо на каждый временной шаг. Например, если слой перед полносвязным слоем выводит массив X размера D-by-N-by-S, то полносвязный слой выводит массив Z размера outputSize-by-N-by-S. На временном шаге t соответствующая запись Z , где обозначает временной шаг t X.
softmax слой применяет функцию softmax к входу. Создайте softmax слой с помощью softmaxLayer.
Слой классификации вычисляет перекрестную энтропийную потерю для проблем классификации мультиклассов со взаимоисключающими классами. Создайте слой классификации с помощью classificationLayer.
Для проблем классификации softmax слоя и затем слой классификации должен следовать за итоговым полносвязным слоем.
Функция активации устройства вывода является функцией softmax:
где и .
Функция softmax является функцией активации устройства вывода после последнего полносвязного слоя для проблем классификации мультиклассов:
где и . Кроме того, , условная вероятность выборки, данной класс r, и априорная вероятность класса.
Функция softmax также известна как нормированный экспоненциал и может быть рассмотрена обобщением мультикласса логистической сигмоидальной функции [8].
Для типичных сетей классификации слой классификации должен следовать за softmax слоем. В слое классификации trainNetwork принимает значения от функции softmax и присваивает каждый вход одному из K взаимоисключающие классы с помощью перекрестной энтропийной функции для 1 из K кодирование схемы [8]:
где N является количеством выборок, K является количеством классов, индикатор, что i th выборка принадлежит j th класс, и вывод для демонстрационного i для класса j, который в этом случае, значение от функции softmax. Таким образом, это - вероятность, что сеть сопоставляет i th вход с классом j.
Создайте слой регрессии с помощью regressionLayer.
Слой регрессии вычисляет половину потери среднеквадратической ошибки для проблем регрессии. Для типичных проблем регрессии слой регрессии должен следовать за итоговым полносвязным слоем.
Для одного наблюдения среднеквадратической ошибкой дают:
где R является количеством ответов, ti является целевой вывод, и yi является прогнозом сети для ответа i.
Для изображения и sequence-one сетей регрессии, функция потерь слоя регрессии является половиной среднеквадратической ошибки предсказанных ответов, не нормированных R:
Для сетей регрессии от изображения к изображению функция потерь слоя регрессии является половиной среднеквадратической ошибки предсказанных ответов для каждого пикселя, не нормированного R:
где H, W и C обозначают высоту, ширину, и количество каналов вывода соответственно и индексы p в каждый элемент (пиксель) t и y линейно.
Для сетей регрессии от последовательности к последовательности функция потерь слоя регрессии является половиной среднеквадратической ошибки предсказанных ответов для каждого временного шага, не нормированного R:
где S является длиной последовательности.
Когда обучение, программное обеспечение вычисляет среднюю потерю по наблюдениям в мини-пакете.
[1] Мерфи, K. P. Машинное обучение: вероятностная перспектива. Кембридж, Массачусетс: нажатие MIT, 2012.
[2] Krizhevsky, A. i. Sutskever и Г. Э. Хинтон. "Классификация ImageNet с глубокими сверточными нейронными сетями". Усовершенствования в нейронных системах обработки информации. Vol 25, 2012.
[3] LeCun, Y., Boser, B., Denker, J.S., Хендерсон, D., Говард, R.E., Хаббард, W., Jackel, L.D., и др. ''Рукописное Распознавание Цифры с Сетью Обратной связи''. В Усовершенствованиях Нейронных Систем обработки информации, 1990.
[4] LeCun, Y., Л. Боттоу, И. Бенхио и П. Хэффнер. ''Основанное на градиенте Изучение Примененного Распознавание Документа''. Продолжения IEEE. Vol 86, стр 2278–2324, 1998.
[5] Nair, V. и Г. Э. Хинтон. "Исправленные линейные модули улучшают ограниченные машины Больцмана". В материалах 27-я Международная конференция по вопросам Машинного обучения, 2010.
[6] Наги, J., Ф. Дукэтелл, Г. А. Ди Каро, Д. Сиресан, У. Мейер, А. Джусти, Ф. Наги, Дж. Шмидхубер, Л. М. Гэмбарделла. ''Объединяющие Max Сверточные Нейронные сети для Основанного на видении Ручного Распознавания Жеста''. Международная конференция IEEE по вопросам и Приложений для обработки изображений (ICSIPA2011), 2011 Сигнала.
[7] Srivastava, N., Г. Хинтон, А. Крижевский, я. Sutskever, Р. Салахутдинов. "Уволенный: Простой Способ Препятствовать тому, чтобы Нейронные сети Сверхсоответствовали". Журнал Исследования Машинного обучения. Издание 15, стр 1929-1958, 2014.
[8] Епископ, C. M. Распознавание образов и машинное обучение. Спрингер, Нью-Йорк, Нью-Йорк, 2006.
[9] Иоффе, Сергей и Кристиан Сзеджеди. "Пакетная нормализация: Ускорение глубокого сетевого обучения путем сокращения внутреннего ковариационного сдвига". предварительно распечатайте, arXiv:1502.03167 (2015).
averagePooling2dLayer | batchNormalizationLayer | classificationLayer | clippedReluLayer | convolution2dLayer | crossChannelNormalizationLayer | dropoutLayer | fullyConnectedLayer | imageInputLayer | leakyReluLayer | maxPooling2dLayer | regressionLayer | reluLayer | softmaxLayer | trainNetwork | trainingOptions
[1] Кредит изображений: арифметика Свертки (Лицензия)
