Распределенная конвейеризация или повторная синхронизация регистра, является оптимизацией скорости, которая перемещает существующие задержки проекта, чтобы уменьшать критический путь при сохранении функционального поведения.
Программное обеспечение HDL Coder™ использует адаптацию Leiserson-Saxe повторно синхронизирующийся алгоритм.
Например, в следующей модели, существует задержка 2 при выводе.
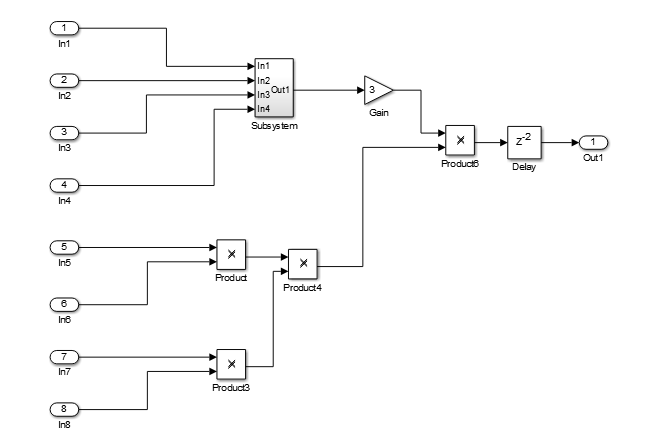
Следующая схема показывает сгенерированную модель, после того, как распределено, конвейеризация перераспределяет задержку, чтобы уменьшать критический путь.

Распределенная конвейеризация может уменьшать критический путь вашего проекта, позволяя вам использовать более высокую тактовую частоту и пропускную способность увеличения.
Однако распределенная конвейеризация требует, чтобы ваш проект содержал много задержек. Если необходимо вставить дополнительные задержки проекта, чтобы включить распределенную конвейеризацию, это увеличивает область и начальную задержку проекта.
Распределенная конвейеризация требует, чтобы ваш проект содержал задержки или регистры, которые могут быть перераспределены. Можно использовать входную конвейеризацию или вывести конвейеризацию, чтобы вставить больше регистров.
Если ваш проект не удовлетворяет ваши требования синхронизации сначала, попытайтесь добавить больше задержек или регистров, чтобы улучшить ваши результаты.
Можно задать распределенную конвейеризацию для a:
Подсистема.
Блок MATLAB function в подсистеме. Для получения дополнительной информации смотрите Распределенную Конвейерную Вставку для блоков MATLAB function.
График Stateflow® в подсистеме.
Задавать распределенную конвейеризацию с помощью пользовательского интерфейса:
Щелкните правой кнопкой по блоку и выберите HDL Code> HDL Block Properties.
Установите DistributedPipelining на on и нажмите OK.
Включить распределенную конвейеризацию, на командной строке, введите:
hdlset_param('path/to/block', 'DistributedPipelining', 'on')Отключить распределенную конвейеризацию, на командной строке, введите:
hdlset_param('path/to/block', 'DistributedPipelining', 'off')Выходные данные могли быть в недопустимом состоянии первоначально, если вы вставляете конвейерные регистры. Чтобы избежать ошибок испытательного стенда, следующих из начальных недопустимых выборок, отключите выходную проверку те выборки. Для получения дополнительной информации см.:
Распределенная оптимизация конвейеризации имеет следующие ограничения:
Ваши результаты конвейеризации не могут быть оптимальными в оборудовании, потому что задержки оператора в вашем целевом компьютере могут отличаться от предполагаемых задержек оператора, используемых распределенным алгоритмом конвейеризации.
Программное обеспечение HDL Coder генерирует конвейерные регистры при выходных параметрах в следующих ситуациях вместо того, чтобы распределить регистры, чтобы уменьшать критический путь:
Блок MATLAB function или диаграмма Stateflow содержат матрицу со статически неразрешимым индексом.
Диаграмма Stateflow содержит переменную состояния или локальную переменную.
HDL Coder распределяет конвейерные регистры вокруг следующих блоков вместо в них:
Модель
Сумма (реализация Cascade)
Продукт (реализация Cascade)
MinMax
Сверхдискретизировать
Субдискретизировать
Переход уровня
Нулевой порядок содержит
Взаимный Sqrt (реализация RecipSqrtNewton)
Тригонометрическая функция (приближение CORDIC)
Один порт RAM
Двухпортовый RAM
Простой двухпортовый RAM
Если вы включаете распределенную конвейеризацию для подсистемы, которая содержит эти блоки, HDL Coder генерирует сообщение во время генерации кода. Чтобы зафиксировать это сообщение, поместите эти блоки в одной или нескольких подсистемах в исходной подсистеме и отключите иерархическую распределенную конвейеризацию. HDL Coder распределяет конвейерные регистры вокруг вложенных подсистем.
Основная полоса демодулятора M-PSK
Основная полоса модулятора M-PSK
Основная полоса демодулятора QPSK
Основная полоса модулятора QPSK
Основная полоса демодулятора BPSK
Основная полоса модулятора BPSK
Генератор последовательности PN
Повторение
Счетчик HDL
Фильтр LMS
Синусоида
Декодер Витерби
Инициированная подсистема
Counter Limited
Счетчик, свободного доступа
Структурируйте преобразование
Чтобы видеть, что распределенный конвейерно обрабатывает информацию в отчете, прежде чем вы сгенерируете код для каждой подсистемы или модели - ссылки, включают отчет Генерации кода. Чтобы включить отчет Генерации кода, в диалоговом окне Configuration Parameters, на панели HDL Code Generation, включают Generate optimization report.
Когда вы генерируете отчет генерации кода в разделе Distributed Pipelining Optimization Report, вы видите эффект распределенной оптимизации конвейеризации. Если распределено конвейеризация неудачна, отчет показывает диагностические сообщения и нарушающие блоки, которые заставили распределенную конвейеризацию перестать работать.
Если распределено конвейеризация успешна, отчет отображается, сравнительные списки регистров до и после вас применяются, распределенная конвейеризация преобразовывают.
Лейсерсон, C.E и Джеймс Б. Сэйкс. “Повторно синхронизируя Синхронную Схему”. Algorithmica. Издание 6, Номер 1, 1991, стр 5-35.
