Можно использовать функцию Statistics and Machine Learning Toolbox™ anova1 выполнять односторонний дисперсионный анализ (Дисперсионный Анализ). Цель одностороннего Дисперсионного Анализа состоит в том, чтобы определить, имеют ли данные из нескольких групп (уровни) фактора общее среднее значение. Таким образом, односторонний Дисперсионный Анализ позволяет вам узнать, оказывают ли различные группы независимой переменной различные влияния на переменную отклика y. Предположим, больница хочет определить, предложили ли новые два планировать методы, уменьшают терпеливое время ожидания больше, чем старый способ запланировать назначения. В этом случае независимая переменная является методом планирования, и переменная отклика является временем ожидания пациентов.
Односторонний Дисперсионный Анализ является простым особым случаем линейной модели. Односторонняя форма Дисперсионного Анализа модели
со следующими предположениями:
y i, j является наблюдением, в котором i представляет номер наблюдения и j, представляет другую группу (уровень) переменного предиктора y. Весь i y j независим.
α j представляет среднее значение населения для j th группа (уровень или обработка).
ε i j является случайной ошибкой, независимой и нормально распределенной, с нулевым средним и постоянным отклонением, т.е. ε i j ~ N (0, σ 2).
Эта модель также называется средней моделью. В модели принимается, что столбцами y является постоянный α j плюс ошибочный компонент ε i j. Дисперсионный Анализ помогает определить, являются ли константы всеми одинаковыми.
Дисперсионный Анализ тестирует гипотезу, что все средние значения группы равны по сравнению с альтернативной гипотезой в наименьшем количестве одной группы, отличается от других.
anova1(y) тестирует равенство средних значений столбца для данных в матричном y, где каждый столбец является другой группой и имеет то же количество наблюдений (т.е. сбалансированный план). anova1(y,group) тестирует равенство средних значений группы, заданных в group, для данных в векторном или матричном y. В этом случае у каждой группы или столбца может быть различное количество наблюдений (т.е. несбалансированный проект).
Дисперсионный Анализ основан на предположении, что все демонстрационные популяции нормально распределены. Это, как известно, устойчиво к скромным нарушениям этого предположения. Можно проверять предположение нормальности визуально при помощи графика нормальности (normplot). В качестве альтернативы можно использовать одну из функций Statistics and Machine Learning Toolbox, которая проверяет на нормальность: Критерий Андерсона-Дарлинга (adtest), тест качества подгонки в квадрате хи (chi2gof), тест Jarque-Bera (jbtest), или тест Lilliefors (lillietest).
Можно обеспечить выборочные данные как вектор или матрицу.
Если выборочные данные находятся в векторе, y, затем необходимо предоставить группирующуюся информацию с помощью group входная переменная: anova1(y,group).
group должен быть числовой вектор, логический вектор, категориальный вектор, символьный массив, массив строк или массив ячеек из символьных векторов, с одним именем для каждого элемента y. anova1 функционируйте обрабатывает y значения, соответствующие тому же значению group как часть той же группы. Например,

Используйте этот проект, когда у групп есть различные числа элементов (разбалансировал Дисперсионный Анализ).
Если выборочные данные находятся в матрице, y, предоставление информации о группе является дополнительным.
Если вы не задаете входную переменную group, затем anova1 обработки каждый столбец y как отдельная группа, и оценивает, равны ли средние значения населения столбцов. Например,

Используйте эту форму проекта, когда у каждой группы есть то же число элементов (сбалансировал Дисперсионный Анализ).
Если вы задаете входную переменную group, затем каждый элемент в group представляет название группы для соответствующего столбца в y. anova1 функционируйте обрабатывает столбцы с тем же названием группы как часть той же группы. Например,

anova1 игнорирует любой NaN значения в y. Кроме того, если group содержит пустой или NaN значения, anova1 игнорирует соответствующие наблюдения в y. anova1 функция выполняет, сбалансировал Дисперсионный Анализ, если у каждой группы есть то же количество наблюдений после того, как функция игнорирует пустой или NaN значения. В противном случае, anova1 выполняет разбалансировал Дисперсионный Анализ.
В этом примере показано, как выполнить односторонний Дисперсионный Анализ, чтобы определить, имеют ли данные из нескольких групп общее среднее значение.
Загрузите и отобразите выборочные данные.
load hogg
hogghogg = 6×5
24 14 11 7 19
15 7 9 7 24
21 12 7 4 19
27 17 13 7 15
33 14 12 12 10
23 16 18 18 20
Данные прибывают от Хогга и Ледолтера (1987) исследование количеств бактерий в поставках молока. Столбцы матричного hogg представляйте различные поставки. Строки являются количествами бактерий от коробок молока, выбранного случайным образом из каждой отгрузки.
Протестируйте, если некоторые поставки имеют более высокие количества, чем другие. По умолчанию, anova1 возвращает две фигуры. Каждый - стандартная таблица ANOVA, и другой является диаграммами данных группой.
[p,tbl,stats] = anova1(hogg);


p
p = 1.1971e-04
Маленькое p-значение приблизительно 0,0001 указывает, что количества бактерий от различных поставок не являются тем же самым.
Можно получить некоторое графическое обеспечение, что средние значения отличаются путем рассмотрения диаграмм. Метки, однако, сравнивают медианы, не средние значения. Для получения дополнительной информации об этом отображении смотрите boxplot.
Просмотрите стандартную таблицу ANOVA. anova1 сохранил стандартную таблицу ANOVA как массив ячеек в выходном аргументе tbl.
tbl
tbl=4×6 cell array
Columns 1 through 5
{'Source' } {'SS' } {'df'} {'MS' } {'F' }
{'Columns'} {[ 803.0000]} {[ 4]} {[200.7500]} {[ 9.0076]}
{'Error' } {[ 557.1667]} {[25]} {[ 22.2867]} {0x0 double}
{'Total' } {[1.3602e+03]} {[29]} {0x0 double} {0x0 double}
Column 6
{'Prob>F' }
{[1.1971e-04]}
{0x0 double }
{0x0 double }
Сохраните значение F-статистической-величины в переменной Fstat.
Fstat = tbl{2,5}Fstat = 9.0076
Просмотрите статистику, необходимую, чтобы сделать кратное попарным сравнением средних значений группы. anova1 сохраняет эти статистические данные в структуре stats.
stats
stats = struct with fields:
gnames: [5x1 char]
n: [6 6 6 6 6]
source: 'anova1'
means: [23.8333 13.3333 11.6667 9.1667 17.8333]
df: 25
s: 4.7209
Дисперсионный Анализ отклоняет нулевую гипотезу, что все средние значения группы равны, таким образом, можно использовать несколько сравнений, чтобы определить, какие средние значения группы отличаются от других. Чтобы провести несколько тестов сравнения, используйте функциональный multcompare, который принимает stats как входной параметр. В этом примере, anova1 отклоняет нулевую гипотезу, что средние количества бактерий от всех четырех поставок равны друг другу, т.е. .
Выполните тест сравнения кратного, чтобы определить, какие поставки отличаются, чем другие в терминах средних количеств бактерий.
multcompare(stats)

ans = 10×6
1.0000 2.0000 2.4953 10.5000 18.5047 0.0059
1.0000 3.0000 4.1619 12.1667 20.1714 0.0013
1.0000 4.0000 6.6619 14.6667 22.6714 0.0001
1.0000 5.0000 -2.0047 6.0000 14.0047 0.2119
2.0000 3.0000 -6.3381 1.6667 9.6714 0.9719
2.0000 4.0000 -3.8381 4.1667 12.1714 0.5544
2.0000 5.0000 -12.5047 -4.5000 3.5047 0.4806
3.0000 4.0000 -5.5047 2.5000 10.5047 0.8876
3.0000 5.0000 -14.1714 -6.1667 1.8381 0.1905
4.0000 5.0000 -16.6714 -8.6667 -0.6619 0.0292
Первые два столбца показывают, какие средние значения группы друг по сравнению с другом. Например, первая строка сравнивает средние значения для групп 1 и 2. Последний столбец показывает p-значения для тестов. P-значения 0.0059, 0.0013, и 0.0001 указывают, что средние количества бактерий в молоке от первой отгрузки отличаются от тех от вторых, третьих, и четвертых поставок. P-значение 0,0292 указывает, что средние количества бактерий в молоке от четвертой отгрузки отличаются от тех от пятого. Процедуре не удается отклонить гипотезы, что другие средние значения группы отличаются друг от друга.
Фигура также иллюстрирует тот же результат. Синяя панель показывает интервал сравнения для первого среднего значения группы, которое не перекрывается с интервалами сравнения для вторых, третьих, и четвертых средних значений группы, отображенных красным. Интервал сравнения для среднего значения пятой группы, отображенной серым, перекрывается с интервалом сравнения для первого среднего значения группы. Следовательно, средние значения группы для первых и пятых групп не существенно отличаются друг от друга.
Тесты Дисперсионного Анализа для различия в группе подразумевают под разделением общего изменения данных на два компонента:
Изменение группы означает от полного среднего значения, т.е. (изменение между группами), где демонстрационное среднее значение группы j, и полное демонстрационное среднее значение.
Изменение наблюдений в каждой группе от их группы означает оценки, (изменение в группе).
Другими словами, Дисперсионный Анализ делит полную сумму квадратов (SST) в сумму квадратов из-за эффекта между группами (SSR) и суммы квадратичных невязок (SSE).
где nj является объемом выборки для j th группа, j = 1, 2..., k.
Затем Дисперсионный Анализ сравнивает изменение между группами к изменению в группах. Если отношение изменения в группе к изменению между группами значительно высоко, то можно прийти к заключению, что средние значения группы существенно отличаются друг от друга. Можно измерить это использование тестовой статистической величины, которая имеет F - распределение с (k – 1, N – k) степени свободы:
где MSR является среднеквадратической обработкой, MSE является среднеквадратической ошибкой, k является количеством групп, и N является общим количеством наблюдений. Если p - значение для F - статистическая величина меньше, чем уровень значения, то тест отклоняет нулевую гипотезу, что все средние значения группы равны, и завершает в наименьшем количестве одном из средних значений группы, отличается от других. Наиболее распространенные уровни значения 0.05 и 0.01.
Таблица ANOVA получает изменчивость в модели с разбивкой по источникам, F - статистической величине для тестирования значения этой изменчивости и p - значение для выбора значения этой изменчивости. p - значение, возвращенное anova1 зависит от предположений о случайных воздействиях ε i j в уравнении модели. Для p - значение, чтобы быть правильными, эти воздействия должны быть независимы, нормально распределены, и иметь постоянное отклонение. Стандартная таблица ANOVA имеет эту форму:
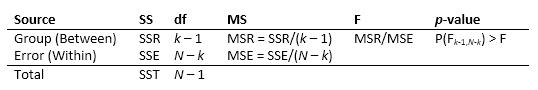
anova1 возвращает стандартную таблицу ANOVA как массив ячеек с шестью столбцами.
| Столбец | Определение |
|---|---|
Source | Источник изменчивости. |
SS | Сумма квадратов из-за каждого источника. |
df | Степени свободы сопоставлены с каждым источником. Предположим, что N является общим количеством наблюдений, и k является количеством групп. Затем N – k является степенями свободы в группах (Error), k – 1 является степенями свободы между группами (Columns), и N – 1 является общими степенями свободы: N – 1 = (N – k) + (k – 1). |
MS | Средние квадратичные для каждого источника, который является отношением SS/df. |
F | F-, которая является отношением средних квадратичных. |
Prob>F | p - значение, которое является вероятностью, что F - статистическая величина может принять значение, больше, чем вычисленное статистическое тестом значение. anova1 выводит эту вероятность из cdf F - распределение. |
Строки таблицы ANOVA показывают изменчивость в данных, разделенных на источник.
| Строка (Источник) | Определение |
|---|---|
Groups или Columns | Изменчивость из-за различий среди средних значений группы (изменчивость между группами) |
Error | Изменчивость из-за различий между данными в каждой группе и средним значением группы (изменчивость в группах) |
Total | Общая изменчивость |
[1] Ву, C. F. J. и М. Амада. Эксперименты: планирование, анализ и оптимизация проекта параметра, 2000.
[2] Neter, J., М. Х. Катнер, К. Дж. Нахцхайм и В. Вассерман. 4-й редактор Прикладные Линейные Статистические модели. Ирвин Пресс, 1996.
anova1 | kruskalwallis | multcompare
