Растяните аудио во времени
Читайте в звуковом сигнале. Слушайте звуковой сигнал и стройте его в зависимости от времени.
[audioIn,fs] = audioread("Counting-16-44p1-mono-15secs.wav"); t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on

sound(audioIn,fs)
Используйте stretchAudio применять 1,5 фактора ускорения. Слушайте модифицированный звуковой сигнал и стройте его в зависимости от времени. Частота дискретизации остается то же самое, но длительность сигнала уменьшилась.
audioOut = stretchAudio(audioIn,1.5); t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, Speedup Factor = 1.5') axis tight grid on

sound(audioOut,fs)
Замедлите исходный звуковой сигнал 0,75 факторами. Слушайте модифицированный звуковой сигнал и стройте его в зависимости от времени. Частота дискретизации остается то же самое как исходное аудио, но длительность сигнала увеличилась.
audioOut = stretchAudio(audioIn,0.75); t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, Speedup Factor = 0.75') axis tight grid on

sound(audioOut,fs)
stretchAudio поддержки TSM на аудио частотного диапазона при использовании метода вокодера по умолчанию. Применение TSM к аудио частотного диапазона позволяет вам снова использовать свой расчет STFT для нескольких факторов TSM.
Читайте в звуковом сигнале. Слушайте звуковой сигнал и стройте его в зависимости от времени.
[audioIn,fs] = audioread('FemaleSpeech-16-8-mono-3secs.wav'); sound(audioIn,fs) t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on

Преобразуйте звуковой сигнал в частотный диапазон.
win = sqrt(hann(256,'periodic')); ovrlp = 192; S = stft(audioIn,'Window',win,'OverlapLength',ovrlp,'Centered',false);
Ускорьте звуковой сигнал на коэффициент 1,4. Задайте окно, и длина перекрытия раньше создавала представление частотного диапазона.
alpha = 1.4; audioOut = stretchAudio(S,alpha,'Window',win,'OverlapLength',ovrlp); sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, TSM Factor = 1.4') axis tight grid on

Замедлите звуковой сигнал на коэффициент 0,8. Задайте окно, и длина перекрытия раньше создавала представление частотного диапазона.
alpha = 0.8; audioOut = stretchAudio(S,alpha,'Window',win,'OverlapLength',ovrlp); sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, TSM Factor = 0.8') axis tight grid on

Метод TSM по умолчанию (вокодер) позволяет вам дополнительно применить блокировку фазы, чтобы увеличить точность исходному аудио.
Читайте в звуковом сигнале. Слушайте звуковой сигнал и стройте его в зависимости от времени.
[audioIn,fs] = audioread("SpeechDFT-16-8-mono-5secs.wav"); sound(audioIn,fs) t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on

Блокировка фазы добавляет нетривиальную вычислительную загрузку в TSM и не всегда требуется. По умолчанию блокировка фазы отключена. Примените фактор ускорения 1,8 к входному звуковому сигналу. Слушайте звуковой сигнал и стройте его в зависимости от времени.
alpha = 1.8; tic audioOut = stretchAudio(audioIn,alpha); processingTimeWithoutPhaseLocking = toc
processingTimeWithoutPhaseLocking = 0.0798
sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, alpha = 1.8, LockPhase = false') axis tight grid on

Примените те же 1,8 фактора ускорения к входному звуковому сигналу, на этот раз включив блокировку фазы. Слушайте звуковой сигнал и стройте его в зависимости от времени.
tic
audioOut = stretchAudio(audioIn,alpha,"LockPhase",true);
processingTimeWithPhaseLocking = tocprocessingTimeWithPhaseLocking = 0.1154
sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, alpha = 1.8, LockPhase = true') axis tight grid on

Перекрытие подобия формы волны - добавляет (WSOLA) TSM, метод позволяет вам задать максимальное количество выборок, чтобы искать лучшее выравнивание сигнала. По умолчанию дельта WSOLA является количеством выборок в аналитическом окне минус количество выборок, перекрытых между смежными аналитическими окнами. Увеличение дельты WSOLA увеличивает вычислительную загрузку, но может также увеличить точность.
Читайте в звуковом сигнале. Слушайте первые 10 секунд звукового сигнала.
[audioIn,fs] = audioread('RockGuitar-16-96-stereo-72secs.flac');
sound(audioIn(1:10*fs,:),fs)Примените фактор TSM 0,75 к входному звуковому сигналу с помощью метода WSOLA. Слушайте первые 10 секунд получившегося звукового сигнала.
alpha = 0.75; tic audioOut = stretchAudio(audioIn,alpha,"Method","wsola"); processingTimeWithDefaultWSOLADelta = toc
processingTimeWithDefaultWSOLADelta = 19.4403
sound(audioOut(1:10*fs,:),fs)
Примените фактор TSM 0,75 к входному звуковому сигналу, на этот раз увеличив дельту WSOLA до 1 024. Слушайте первые 10 секунд получившегося звукового сигнала.
tic audioOut = stretchAudio(audioIn,alpha,"Method","wsola","WSOLADelta",1024); processingTimeWithIncreasedWSOLADelta = toc
processingTimeWithIncreasedWSOLADelta = 25.5306
sound(audioOut(1:10*fs,:),fs)
Алгоритм вокодера фазы является подходом частотного диапазона к TSM [1][2]. Основные шаги алгоритма вокодера фазы:
Окна алгоритма сигнал временной области в интервале η, где η = numel (. Окна затем преобразованы в частотный диапазон.Window) - OverlapLength
Чтобы сохранить горизонталь (через время) когерентность фазы, алгоритм обрабатывает каждый интервал как независимую синусоиду, фаза которой вычисляется путем накопления оценок ее мгновенной частоты.
Чтобы сохранить вертикальный (через отдельный спектр) когерентность фазы, алгоритм блокирует усовершенствование фазы групп интервалов к усовершенствованию фазы локального peaks. Этот шаг только применяется если LockPhase установлен в true.
Алгоритм возвращает модифицированную спектрограмму во временной интервал, с окнами, расположенными с интервалами с промежутками в δ, где δ ≈ η/α. α является фактором ускорения, заданным alpha входной параметр.
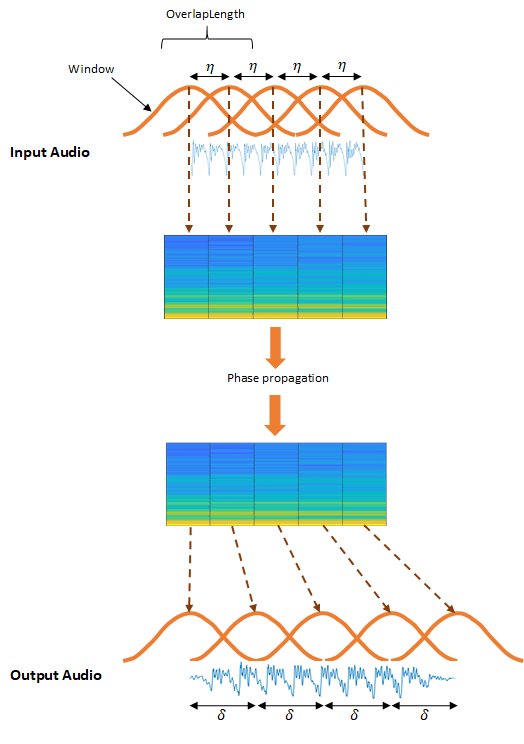
Алгоритм WSOLA является подходом временного интервала к TSM [1][2]. WSOLA является расширением перекрытия, и добавьте алгоритм (OLA). В алгоритме OLA сигнал временной области является оконным в интервале η, где η = numel (. Создать масштаб времени изменило выходное аудио, окна расположены с интервалами в интервале δ, где δ ≈ η/α. α является фактором TSM, заданным Window) - OverlapLengthalpha входной параметр.
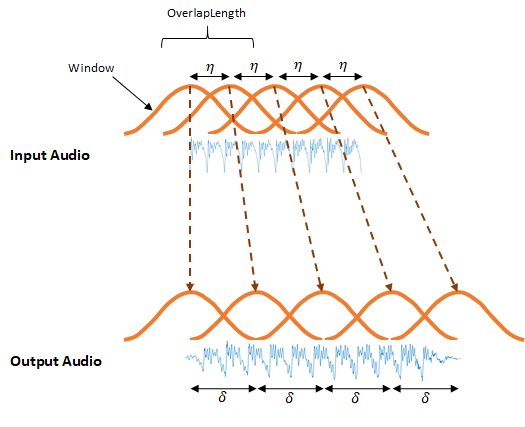
Алгоритм OLA делает хорошее задание воссоздания спектров величины, но может ввести скачки фазы между окнами. Алгоритм WSOLA пытается сглаживать скачки фазы путем поиска WSOLADelta производят вокруг η интервала для окна, которое минимизирует скачки фазы. Алгоритм ищет лучшее окно итеративно, так, чтобы каждое последовательное окно было выбрано относительно ранее выбранного окна.
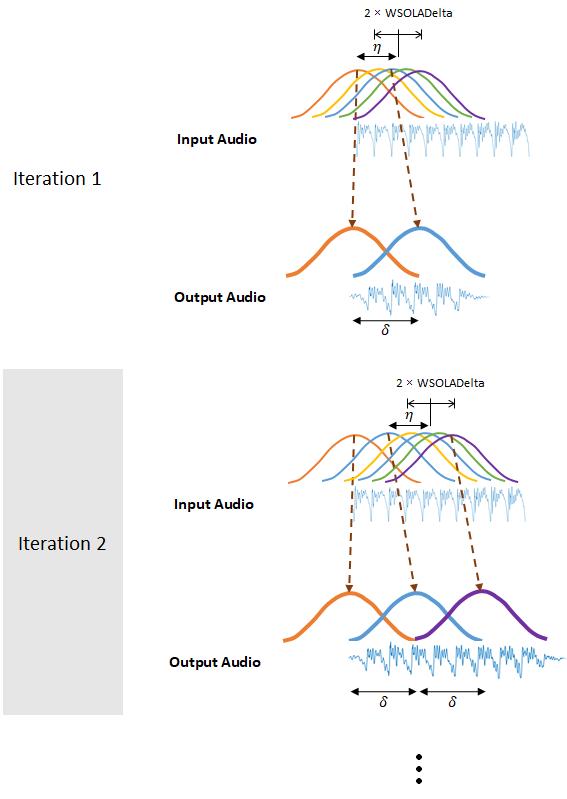
Если WSOLADelta установлен в 0, затем алгоритм уменьшает до OLA.
[1] Driedger, Джонатан и Майнард Мюллер. "Анализ модификации масштаба времени музыкальных сигналов". Прикладные науки. Издание 6, выпуск 2, 2016.
[2] Driedger, Джонатан. "Алгоритмы Модификации масштаба времени для Музыкальных Звуковых сигналов", Магистерская диссертация, Саарландский университет, Саарбрюккен, Германия, 2011.
audioDataAugmenter | audioTimeScaler | reverberator | shiftPitch
