Предскажите одномерные авторегрессивные интегрированные ответы модели (ARIMA) скользящего среднего значения или условные отклонения
[ возвращает Y,YMSE]
= forecast(Mdl,numperiods,Y0)numperiods последовательные предсказанные ответы Y и соответствующие среднеквадратичные погрешности (MSE) YMSE из полностью заданной, одномерной модели ARIMA Mdl. Преддемонстрационные данные об ответе Y0 инициализирует модель, чтобы сгенерировать прогнозы.
[ дополнительные опции использования заданы одним или несколькими аргументами значения имени. Например, для модели с компонентом регрессии (то есть, модели ARIMAX), Y,YMSE] = forecast(Mdl,numperiods,Y0,Name,Value)'X0',X0,'XF',XF задает преддемонстрационные и предсказанные данные о предикторе X0 и XF, соответственно.
Предскажите условный средний ответ симулированных данных по горизонту с 30 периодами.
Симулируйте 130 наблюдений из мультипликативной сезонной модели скользящего среднего значения (MA) с известными значениями параметров.
Mdl = arima('MA',{0.5,-0.3},'SMA',0.4,'SMALags',12,... 'Constant',0.04,'Variance',0.2); rng(200); Y = simulate(Mdl,130);
Подбирайте сезонную модель MA к первым 100 наблюдениям и зарезервируйте остающиеся 30 наблюдений, чтобы оценить эффективность прогноза.
MdlTemplate = arima('MALags',1:2,'SMALags',12); EstMdl = estimate(MdlTemplate,Y(1:100));
ARIMA(0,0,2) Model with Seasonal MA(12) (Gaussian Distribution):
Value StandardError TStatistic PValue
________ _____________ __________ __________
Constant 0.20403 0.069064 2.9542 0.0031344
MA{1} 0.50212 0.097298 5.1606 2.4619e-07
MA{2} -0.20174 0.10447 -1.9312 0.053464
SMA{12} 0.27028 0.10907 2.478 0.013211
Variance 0.18681 0.032732 5.7073 1.148e-08
EstMdl новый arima модель, которая содержит предполагаемые параметры (то есть, полностью заданная модель).
Предскажите подобранную модель в горизонт с 30 периодами. Задайте данные о периоде оценки как предварительную выборку.
[YF,YMSE] = forecast(EstMdl,30,Y(1:100)); YF(15)
ans = 0.2040
YMSE(15)
ans = 0.2592
YF 30 1 вектор из предсказанных ответов и YMSE 30 1 вектор из соответствующего MSEs. 15 периодов вперед предсказали, 0.2040, и его MSE 0.2592.
Визуально сравните прогнозы с данными о затяжке.
figure h1 = plot(Y,'Color',[.7,.7,.7]); hold on h2 = plot(101:130,YF,'b','LineWidth',2); h3 = plot(101:130,YF + 1.96*sqrt(YMSE),'r:',... 'LineWidth',2); plot(101:130,YF - 1.96*sqrt(YMSE),'r:','LineWidth',2); legend([h1 h2 h3],'Observed','Forecast',... '95% Confidence Interval','Location','NorthWest'); title(['30-Period Forecasts and Approximate 95% '... 'Confidence Intervals']) hold off

Предскажите ежедневный Сводный индекс NASDAQ по 500-дневному горизонту.
Загрузите набор данных NASDAQ и извлеките первые 1 500 наблюдений.
load Data_EquityIdx
nasdaq = DataTable.NASDAQ(1:1500);Подбирайте модель ARIMA (1,1,1) к данным.
nasdaqModel = arima(1,1,1); nasdaqFit = estimate(nasdaqModel,nasdaq);
ARIMA(1,1,1) Model (Gaussian Distribution):
Value StandardError TStatistic PValue
_________ _____________ __________ __________
Constant 0.43031 0.18555 2.3191 0.020391
AR{1} -0.074389 0.081985 -0.90735 0.36422
MA{1} 0.31126 0.077266 4.0284 5.6166e-05
Variance 27.826 0.63625 43.735 0
Предскажите Сводный индекс в течение 500 дней с помощью подобранной модели. Используйте наблюдаемые данные в качестве преддемонстрационных данных.
[Y,YMSE] = forecast(nasdaqFit,500,nasdaq);
Постройте прогнозы и 95%-е интервалы прогноза.
lower = Y - 1.96*sqrt(YMSE); upper = Y + 1.96*sqrt(YMSE); figure plot(nasdaq,'Color',[.7,.7,.7]); hold on h1 = plot(1501:2000,lower,'r:','LineWidth',2); plot(1501:2000,upper,'r:','LineWidth',2) h2 = plot(1501:2000,Y,'k','LineWidth',2); legend([h1 h2],'95% Interval','Forecast',... 'Location','NorthWest') title('NASDAQ Composite Index Forecast') hold off

Процесс является неустановившимся, таким образом, ширина каждого интервала прогноза растет со временем.
Предскажите следующую известную авторегрессивную модель с одной задержкой и внешнюю модель (ARX(1)) предиктора в горизонт прогноза с 10 периодами:
где стандартная Гауссова случайная переменная, и внешняя Гауссова случайная переменная со средним значением 1 и стандартным отклонением 0,5.
Создайте arima объект модели, который представляет модель ARX (1).
Mdl = arima('Constant',1,'AR',0.3,'Beta',2,'Variance',1);
Предсказывать ответы из модели ARX (1), forecast функция требует:
Один преддемонстрационный ответ инициализировать авторегрессивный термин
Будущие внешние данные, чтобы включать эффекты внешней переменной на предсказанных ответах
Установите преддемонстрационный ответ на безусловное среднее значение стационарного процесса:
Для будущих внешних данных чертите 10 значений от распределения внешней переменной.
rng(1); y0 = (1 + 2)/(1 - 0.3); xf = 1 + 0.5*randn(10,1);
Предскажите модель ARX (1) в горизонт прогноза с 10 периодами. Задайте преддемонстрационный ответ и будущие внешние данные.
fh = 10;
yf = forecast(Mdl,fh,y0,'XF',xf)yf = 10×1
3.6367
5.2722
3.8232
3.0373
3.0657
3.3470
3.4454
4.2120
4.0667
4.8065
yf(3)= 3.8232 3 периода вперед прогноз модели ARX (1).
Предскажите пути ко множественному ответу от известного SAR модель путем определения нескольких преддемонстрационных путей к ответу.
Создайте arima объект модели, который представляет этот ежеквартальный SAR модель:
где стандартная Гауссова случайная переменная.
Mdl = arima('Constant',1,'AR',0.5,'Variance',1,... 'Seasonality',4,'SARLags',4,'SAR',0.2)
Mdl =
arima with properties:
Description: "ARIMA(1,0,0) Model Seasonally Integrated with Seasonal AR(4) (Gaussian Distribution)"
Distribution: Name = "Gaussian"
P: 9
D: 0
Q: 0
Constant: 1
AR: {0.5} at lag [1]
SAR: {0.2} at lag [4]
MA: {}
SMA: {}
Seasonality: 4
Beta: [1×0]
Variance: 1
Поскольку Mdl содержит авторегрессивные динамические условия, forecast требует предыдущего Mdl.P ответы, чтобы сгенерировать a - период вперед предсказан из модели. Поэтому предварительная выборка должна содержать по крайней мере девять значений.
Сгенерируйте случайное 9 10 матрица, представляющая 10 преддемонстрационных путей длины 9.
rng(1); numpaths = 10; Y0 = rand(Mdl.P,numpaths);
Предскажите 10 путей из модели SAR в 12 горизонтов прогноза четверти. Задайте преддемонстрационные пути к наблюдению Y0.
fh = 12; YF = forecast(Mdl,fh,Y0);
YF 12 10 матрица независимых предсказанных путей. YF(j,k) j- прогноз периода вперед пути k. Путь YF(:,k) представляет продолжение преддемонстрационного пути Y0(:,k).
Постройте предварительную выборку и прогнозы.
Y = [Y0;... YF]; figure; plot(Y); hold on h = gca; px = [6.5 h.XLim([2 2]) 6.5]; py = h.YLim([1 1 2 2]); hp = patch(px,py,[0.9 0.9 0.9]); uistack(hp,"bottom"); axis tight legend("Forecast period") xlabel('Time (quarters)') ylabel('Response paths')

Рассмотрите следующий AR (1) условная средняя модель с GARCH (1,1) условная модель отклонения для ежедневного ряда уровня NASDAQ (как процент) с 2 января 1990 до 31 декабря 2001.
где серия независимых случайных переменных Gaussian со средним значением 0.
Создайте модель.
CondVarMdl = garch('Constant',0.022,'GARCH',0.873,'ARCH',0.119); Mdl = arima('Constant',0.073,'AR',0.138,'Variance',CondVarMdl);
Загрузите набор данных фондового индекса. Преобразуйте таблицу в расписание и преобразуйте ряд цены NASDAQ в ряд возврата. Поскольку ряд возврата имеет тот меньше наблюдения, чем ценовой ряд, предварительно заполните ряд возврата, чтобы синхронизировать его с переменными в расписании.
load Data_EquityIdx dates = datetime(dates,'ConvertFrom','datenum','Locale','en_US'); TT = table2timetable(DataTable,'RowTimes',dates); T = size(TT,1); y0 = 100*price2ret(DataTable.NASDAQ); [e0,v0] = infer(Mdl,y0); n = numel(y0); TT{:,["NASDAQRet" "Residuals" "CondVar"]} = [nan(T-n,3); y0 e0 v0];
Предскажите модель по 25-дневному горизонту. Предоставьте целый набор данных как предварительную выборку (forecast использование только последние необходимые наблюдения, которые инициализируют условное среднее значение и модели отклонения). Возвратите предсказанные ответы и условные отклонения.
fh = 25;
fhdates = TT.Time(end) + caldays(0:fh); % Forecast horizon dates
[y,~,v] = forecast(Mdl,fh,TT.NASDAQRet);Постройте предсказанные ответы и условные отклонения с наблюдаемым рядом с августа 2001.
pdates = TT.Time > datetime(2001,8,1); plot(TT.Time(pdates),TT.NASDAQRet(pdates)) hold on plot(fhdates,[TT.NASDAQRet(end); y]) hold off

plot(TT.Time(pdates),TT.CondVar(pdates)) hold on plot(fhdates,[TT.CondVar(end); v]); hold off

Time base partitions for forecasting является двумя непересекающимися, непрерывными интервалами основы времени; каждый интервал содержит данные временных рядов для прогнозирования динамической модели. forecast period (горизонт прогноза) является numperiods раздел длины в конце времени базируется во время который forecast функция генерирует прогнозы Y от динамической модели Mdl. presample period является целым разделом, происходящим перед периодом прогноза. forecast функция может потребовать наблюдаемых ответов Y0, инновации E0, или условные отклонения V0 в преддемонстрационный период, чтобы инициализировать динамическую модель для прогнозирования. Структура модели определяет типы и объемы необходимых преддемонстрационных наблюдений.
Установившаяся практика должна подбирать динамическую модель к фрагменту набора данных, и затем подтвердить предсказуемость модели путем сравнения ее прогнозов с наблюдаемыми ответами. Во время прогнозирования преддемонстрационный период содержит данные, к которым модель является подходящей, и период прогноза содержит выборку затяжки для валидации. Предположим, что yt является наблюдаемым рядом ответа; x 1, t, x 2, t и x 3, t наблюдается внешний ряд; и время t = 1, …, T. Рассмотрите ответы прогнозирования от динамической модели y t содержащий компонент регрессии с numperiods = периоды K. Предположим, что динамическая модель является подходящей к данным в интервале [1, T – K] (для получения дополнительной информации, смотрите estimate). Этот рисунок показывает базовые разделы времени для прогнозирования.
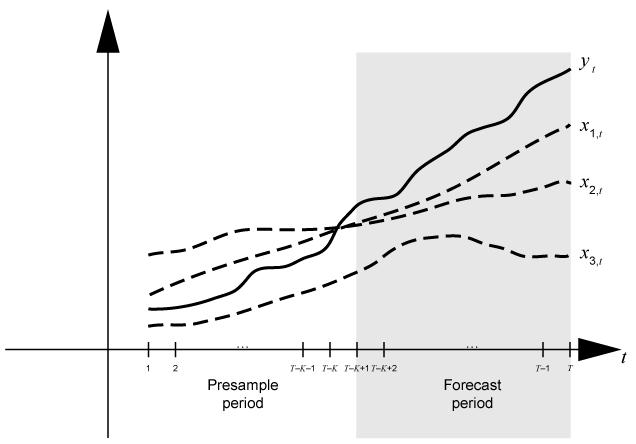
Например, чтобы сгенерировать прогнозы Y из модели ARX (2), forecast требует:
Преддемонстрационные ответы Y0 = инициализировать модель. 1 период вперед предсказал, требует обоих наблюдений, тогда как эти 2 периода вперед предсказывают, требует y T – K и 1 период вперед предсказывают Y(1). forecast функция генерирует все другие прогнозы путем заменения предыдущими прогнозами изолированных ответов в модели.
Будущие внешние данные XF = для компонента регрессии модели. Без заданных будущих внешних данных, forecast функция игнорирует компонент регрессии модели, который может дать к нереалистичным прогнозам.
Динамические модели, содержащие или компонент скользящего среднего значения или условную модель отклонения, могут потребовать преддемонстрационных инноваций или условных отклонений. Учитывая достаточные преддемонстрационные ответы, forecast выводит необходимые преддемонстрационные инновации и условные отклонения. Если такая модель также содержит компонент регрессии, то forecast должен иметь достаточно преддемонстрационных ответов и внешних данных, чтобы вывести необходимые преддемонстрационные инновации и условные отклонения. Этот рисунок показывает массивы необходимых наблюдений для этого случая с соответствующими аргументами ввода и вывода.
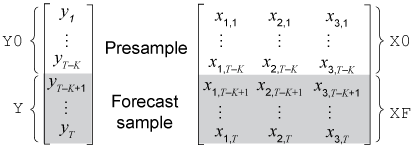
forecast функция определяет номер демонстрационных путей (numpaths) к максимальному количеству столбцов среди преддемонстрационных наборов данных E0, V0, и Y0. Все преддемонстрационные наборы данных должны иметь или один столбец или numpaths > 1 столбец. В противном случае, forecast выдает ошибку. Например, если вы предоставляете Y0 и E0, и Y0 имеет пять столбцов, представляющих пять путей, затем E0 может каждый иметь один столбец или пять столбцов. Если E0 имеет один столбец, forecast применяет E0 к каждому пути.
NaN значения в преддемонстрационных и будущих наборах данных указывают на недостающие данные. forecast удаляет недостающие данные из преддемонстрационных наборов данных, выполняющих эту процедуру:
forecast горизонтально конкатенирует заданные преддемонстрационные наборы данных Y0, E0, V0, и X0 так, чтобы последние наблюдения произошли одновременно. Результатом может быть зубчатый массив, потому что преддемонстрационные наборы данных могут иметь различное количество строк. В этом случае, forecast переменные перед клавиатурами с соответствующим количеством нулей, чтобы сформировать матрицу.
forecast применяет мудрое списком удаление к объединенной преддемонстрационной матрице путем удаления всех строк, содержащих по крайней мере один NaN.
forecast извлекает обработанные преддемонстрационные наборы данных из результата шага 2 и удаляет все предзаполненные нули.
forecast применяет подобную процедуру к предсказанным данным о предикторе XF. После forecast применяет мудрое списком удаление к XF, результат должен иметь, по крайней мере, numperiods 'Строки' . В противном случае, forecast выдает ошибку.
Мудрое списком удаление уменьшает объем выборки и может создать неправильные временные ряды.
Когда forecast оценивает YMSE MSEs из условного среднего значения предсказывает Y, функция обрабатывает заданные наборы данных предиктора X0 и XF как внешний, нестохастический, и статистически независимый от инноваций модели. Поэтому YMSE отражает только отклонение, сопоставленное с компонентом ARIMA входной модели Mdl.
[1] Baillie, Ричард Т. и Тим Боллерслев. “Предсказание в Динамических моделях с Зависящими от времени Условными Отклонениями”. Журнал Эконометрики 52, (апрель 1992): 91–113. https://doi.org/10.1016/0304-4076 (92) 90066-Z.
[2] Боллерслев, Тим. “Обобщенный Авторегрессивный Условный Heteroskedasticity”. Журнал Эконометрики 31 (апрель 1986): 307–27. https://doi.org/10.1016/0304-4076 (86) 90063-1.
[3] Боллерслев, Тим. “Условно Модель Временных рядов Heteroskedastic за Спекулятивные Цены и Нормы прибыли”. Анализ Экономики и Статистики 69 (август 1987): 542–47. https://doi.org/10.2307/1925546.
[4] Поле, Джордж Э. П., Гвилим М. Дженкинс и Грегори К. Рейнсель. Анализ Временных Рядов: Прогнозирование и Управление. 3-й редактор Englewood Cliffs, NJ: Prentice Hall, 1994.
[5] Enders, Уолтер. Прикладные эконометрические временные ряды. Хобокен, NJ: John Wiley & Sons, Inc., 1995.
[6] Энгл, Роберт. F. “Авторегрессивный Условный Heteroscedasticity с Оценками Отклонения Инфляции Соединенного Королевства”. (Июль 1982) Econometrica 50: 987–1007. https://doi.org/10.2307/1912773.
[7] Гамильтон, анализ временных рядов Джеймса Д. Принстон, NJ: Издательство Принстонского университета, 1994.
