Сравните точность двух моделей классификации с помощью новых данных
compareHoldout статистически оценивает точность двух моделей классификации. Функция сначала сравнивает их предсказанные метки с истинными метками, и затем она обнаруживает, является ли различие между misclassification уровнями статистически значительным.
Можно определить, отличается ли точность моделей классификации или выполняет ли одна модель лучше, чем другой. compareHoldout может провести несколько тестовых изменений Макнемэра, включая асимптотический тест, точно-условный тест и тест mid-p-value. Для чувствительной к стоимости оценки доступные тесты включают тест хи-квадрата (требует Optimization Toolbox™), и тест отношения правдоподобия.
h = compareHoldout(C1,C2,T1,T2,ResponseVarName)C1 классификации и C2 имейте равную точность для предсказания истинных меток класса в ResponseVarName переменная. Альтернативная гипотеза - то, что метки имеют неравную точность.
Первая модель C1 классификации использует данные о предикторе в T1, и вторая модель C2 классификации использует данные о предикторе в T2. Таблицы T1 и T2 должен содержать ту же переменную отклика, но может содержать различные наборы предикторов. По умолчанию программное обеспечение проводит mid-p-value тест Макнемэра, чтобы сравнить точность.
h= 1 указывает на отклонение нулевой гипотезы на 5%-м уровне значения. h= 0 указывает на не отклонение нулевой гипотезы на 5%-м уровне.
Следующее является примерами тестов, которые можно провести:
Сравните точность простой модели классификации и модели, которая является более комплексной путем передачи того же набора данных о предикторе (то есть, T1 = T2).
Сравните точность двух потенциально различных моделей с помощью двух потенциально различных наборов предикторов.
Выполните различные типы Выбора признаков. Например, можно сравнить точность модели, обученной с помощью набора предикторов с точностью одного обученного на подмножестве или различного набора тех предикторов. Можно выбрать набор предикторов произвольно или использовать метод выбора признаков, такой как PCA или последовательный выбор признаков (см. pca и sequentialfs).
h = compareHoldout(C1,C2,T1,T2,Y)C1 классификации и C2 имейте равную точность для предсказания, что истинный класс маркирует Y. Альтернативная гипотеза - то, что метки имеют неравную точность.
Первая модель C1 классификации использует данные о предикторе T1, и вторая модель C2 классификации использует данные о предикторе T2. По умолчанию программное обеспечение проводит mid-p-value тест Макнемэра, чтобы сравнить точность.
h = compareHoldout(C1,C2,X1,X2,Y)C1 классификации и C2 имейте равную точность для предсказания, что истинный класс маркирует Y. Альтернативная гипотеза - то, что метки имеют неравную точность.
Первая модель C1 классификации использует данные о предикторе X1, и вторая модель C2 классификации использует данные о предикторе X2. По умолчанию программное обеспечение проводит mid-p-value тест Макнемэра, чтобы сравнить точность.
h = compareHoldout(___,Name,Value)
Обучите два классификатора k - ближайших соседей, одно использование подмножества предикторов, используемых для другого. Проведите статистический тест, сравнивающий точность этих двух моделей на наборе тестов.
Загрузите carsmall набор данных.
load carsmallСоставьте две таблицы входных данных, где вторая таблица исключает предиктор Acceleration. Задайте Model_Year как переменная отклика.
T1 = table(Acceleration,Displacement,Horsepower,MPG,Model_Year); T2 = T1(:,2:end);
Создайте раздел, который разделяет данные в наборы обучающих данных и наборы тестов. Сохраните 30% данных для тестирования.
rng(1) % For reproducibility CVP = cvpartition(Model_Year,'holdout',0.3); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP объект раздела перекрестной проверки, который задает наборы обучающих данных и наборы тестов.
Обучите ClassificationKNN модели с помощью T1 и T2 данные.
C1 = fitcknn(T1(idxTrain,:),'Model_Year'); C2 = fitcknn(T2(idxTrain,:),'Model_Year');
C1 и C2 обученный ClassificationKNN модели.
Протестируйте, имеют ли эти две модели равную прогнозирующую точность на наборе тестов.
h = compareHoldout(C1,C2,T1(idxTest,:),T2(idxTest,:),'Model_Year')h = logical
0
h = 0 указывает, чтобы не отклонить нулевую гипотезу, что эти две модели имеют равную прогнозирующую точность.
Обучайтесь две классификации моделируют использующие различные алгоритмы. Проведите статистический тест, сравнивающий misclassification уровни этих двух моделей на наборе тестов.
Загрузите ionosphere набор данных.
load ionosphereСоздайте раздел, который равномерно разделяет данные в наборы обучающих данных и наборы тестов.
rng(1) % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP объект раздела перекрестной проверки, который задает наборы обучающих данных и наборы тестов.
Обучите модель SVM и ансамбль 100 сложенных в мешок деревьев классификации. Для модели SVM задайте, чтобы использовать радиальное ядро основной функции и эвристическую процедуру, чтобы определить шкалу ядра.
C1 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true, ... 'KernelFunction','RBF','KernelScale','auto'); t = templateTree('Reproducible',true); % For reproducibility of random predictor selections C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','Bag', ... 'Learners',t);
C1 обученный ClassificationSVM модель. C2 обученный ClassificationBaggedEnsemble модель.
Протестируйте, имеют ли эти две модели равную прогнозирующую точность. Используйте те же данные о предикторе набора тестов для каждой модели.
h = compareHoldout(C1,C2,X(idxTest,:),X(idxTest,:),Y(idxTest))
h = logical
0
h = 0 указывает, чтобы не отклонить нулевую гипотезу, что эти две модели имеют равную прогнозирующую точность.
Обучите две модели классификации с помощью того же алгоритма, но настройте гиперпараметр, чтобы сделать алгоритм более комплексным. Проведите статистический тест, чтобы оценить, имеет ли более простая модель лучшую точность на тестовых данных, чем более сложная модель.
Загрузите ionosphere набор данных.
load ionosphere;Создайте раздел, который равномерно разделяет данные в наборы обучающих данных и наборы тестов.
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP объект раздела перекрестной проверки, который задает наборы обучающих данных и наборы тестов.
Обучите две модели SVM: тот, который использует линейное ядро (значение по умолчанию для бинарной классификации) и та, которая использует радиальное ядро основной функции. Используйте шкалу ядра по умолчанию 1.
C1 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true); C2 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true,... 'KernelFunction','RBF');
C1 и C2 обученный ClassificationSVM модели.
Протестируйте нулевую гипотезу что более простая модель (C1) самое большее так же точно как более сложная модель (C2). Поскольку размер набора тестов является большим, проведите асимптотический тест Макнемэра и сравните результаты с тестом mid-p-value (нечувствительное к стоимости значение по умолчанию тестирования). Запросите возвратить p-значения и misclassification уровни.
Asymp = zeros(4,1); % Preallocation MidP = zeros(4,1); [Asymp(1),Asymp(2),Asymp(3),Asymp(4)] = compareHoldout(C1,C2,... X(idxTest,:),X(idxTest,:),Y(idxTest),'Alternative','greater',... 'Test','asymptotic'); [MidP(1),MidP(2),MidP(3),MidP(4)] = compareHoldout(C1,C2,... X(idxTest,:),X(idxTest,:),Y(idxTest),'Alternative','greater'); table(Asymp,MidP,'RowNames',{'h' 'p' 'e1' 'e2'})
ans=4×2 table
Asymp MidP
__________ __________
h 1 1
p 7.2801e-09 2.7649e-10
e1 0.13714 0.13714
e2 0.33143 0.33143
P-значение близко к нулю для обоих тестов, представляя убедительные свидетельства, чтобы отклонить нулевую гипотезу, что более простая модель менее точна, чем более сложная модель. Неважно, что тестирует вас, задают, compareHoldout возвращает тот же тип меры по misclassification для обеих моделей.
Для наборов данных с неустойчивыми представлениями класса, или для наборов данных с неустойчивыми ложно-положительными и ложно-отрицательными затратами, можно статистически сравнить прогнозирующую эффективность двух моделей классификации включением матрицы стоимости в анализе.
Загрузите arrhythmia набор данных. Определите представления класса в данных.
load arrhythmia;
Y = categorical(Y);
tabulate(Y); Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
Существует 16 классов, однако некоторые не представлены в наборе данных (например, класс 13). Большинство наблюдений классифицируется как не наличие аритмии (класс 1). Набор данных очень дискретен с неустойчивыми классами.
Объедините все наблюдения с аритмией (классы 2 - 15) в один класс. Удалите те наблюдения с неизвестным состоянием аритмии (класс 16) от набора данных.
idx = (Y ~= '16'); Y = Y(idx); X = X(idx,:); Y(Y ~= '1') = 'WithArrhythmia'; Y(Y == '1') = 'NoArrhythmia'; Y = removecats(Y);
Создайте раздел, который равномерно разделяет данные в наборы обучающих данных и наборы тестов.
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP объект раздела перекрестной проверки, который задает наборы обучающих данных и наборы тестов.
Создайте стоимость, матрицируют таким образом, что, неправильно классифицируя пациента с аритмией в "никакую аритмию" класс в пять раз хуже, чем неправильная классификация пациента без аритмии в класс аритмии. Классификация правильно не несет расходов. Строки указывают на истинный класс, и столбцы указывают на предсказанный класс. Когда вы проводите чувствительный к стоимости анализ, хорошая практика должна задать порядок классов.
cost = [0 1;5 0];
ClassNames = {'NoArrhythmia','WithArrhythmia'};Обучите два повышающих ансамбля 50 деревьев классификации, то, которое использует AdaBoostM1 и другого, который использует LogitBoost. Поскольку набор данных содержит отсутствующие значения, задайте, чтобы использовать суррогатные разделения. Обучите модели с помощью матрицы стоимости.
t = templateTree('Surrogate','on'); numTrees = 50; C1 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','AdaBoostM1', ... 'NumLearningCycles',numTrees,'Learners',t, ... 'Cost',cost,'ClassNames',ClassNames); C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','LogitBoost', ... 'NumLearningCycles',numTrees,'Learners',t, ... 'Cost',cost,'ClassNames',ClassNames);
C1 и C2 обученный ClassificationEnsemble модели.
Протестируйте ли ансамбль AdaBoostM1 (C1) и ансамбль LogitBoost (C2) имейте равную прогнозирующую точность. Предоставьте матрицу стоимости. Проведите асимптотическое, отношение правдоподобия, чувствительный к стоимости тест (значение по умолчанию, когда вы передадите в матрице стоимости). Запросите возвратить затраты misclassification и p-значения.
[h,p,e1,e2] = compareHoldout(C1,C2,X(idxTest,:),X(idxTest,:),Y(idxTest),... 'Cost',cost)
h = logical
0
p = 0.3334
e1 = 0.5581
e2 = 0.4698
h = 0 указывает, чтобы не отклонить нулевую гипотезу, что эти две модели имеют равную прогнозирующую точность.
Уменьшайте сложность модели классификации путем выбора подмножества переменных предикторов (функции) от большего набора. Затем статистически сравните точность из выборки между этими двумя моделями.
Загрузите ionosphere набор данных.
load ionosphere;Создайте раздел, который равномерно разделяет данные в наборы обучающих данных и наборы тестов.
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP объект раздела перекрестной проверки, который задает наборы обучающих данных и наборы тестов.
Обучите ансамбль 100 повышенных деревьев классификации с помощью AdaBoostM1 и целого набора предикторов. Смотрите меру по важности для каждого предиктора.
t = templateTree('MaxNumSplits',1); % Weak-learner template tree object C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','AdaBoostM1',... 'Learners',t); predImp = predictorImportance(C2); figure; bar(predImp); h = gca; h.XTick = 1:2:h.XLim(2)
h =
Axes with properties:
XLim: [-0.2000 35.2000]
YLim: [0 0.0090]
XScale: 'linear'
YScale: 'linear'
GridLineStyle: '-'
Position: [0.1300 0.1100 0.7750 0.8150]
Units: 'normalized'
Show all properties
title('Predictor Importance'); xlabel('Predictor'); ylabel('Importance measure');

Идентифицируйте лучшие пять предикторов в терминах их важности.
[~,idxSort] = sort(predImp,'descend');
idx5 = idxSort(1:5);Обучите другой ансамбль 100 повышенных деревьев классификации с помощью AdaBoostM1 и этих пяти предикторов с самой большой важностью.
C1 = fitcensemble(X(idxTrain,idx5),Y(idxTrain),'Method','AdaBoostM1',... 'Learners',t);
Протестируйте, имеют ли эти две модели равную прогнозирующую точность. Задайте уменьшаемые данные о предикторе набора тестов для C1 и полные данные о предикторе набора тестов для C2.
[h,p,e1,e2] = compareHoldout(C1,C2,X(idxTest,idx5),X(idxTest,:),Y(idxTest))
h = logical
0
p = 0.7744
e1 = 0.0914
e2 = 0.0857
h = 0 указывает, чтобы не отклонить нулевую гипотезу, что эти две модели имеют равную прогнозирующую точность. Этот результат способствует более простому ансамблю, C1.
compareHoldout не сравнивает модели ECOC, состоявшие из линейных или моделей классификации ядер (то есть, ClassificationLinear или ClassificationKernel объекты модели). Сравнить ClassificationECOC модели, состоявшие из линейных или моделей классификации ядер, использовать testcholdout вместо этого.
Точно так же compareHoldout не сравнивает ClassificationLinear или ClassificationKernel объекты модели. Чтобы сравнить эти модели, использовать testcholdout вместо этого.
McNemar Tests является тестами гипотезы, которые сравнивают две пропорции населения при решении проблем, следующих из двух зависимых, совпадающих парных выборок.
Один способ сравнить прогнозирующую точность двух моделей классификации:
Разделите данные в наборы обучающих данных и наборы тестов.
Обучите обе модели классификации с помощью набора обучающих данных.
Предскажите метки класса с помощью набора тестов.
Обобщите результаты в two-two таблице, похожей на этот рисунок.
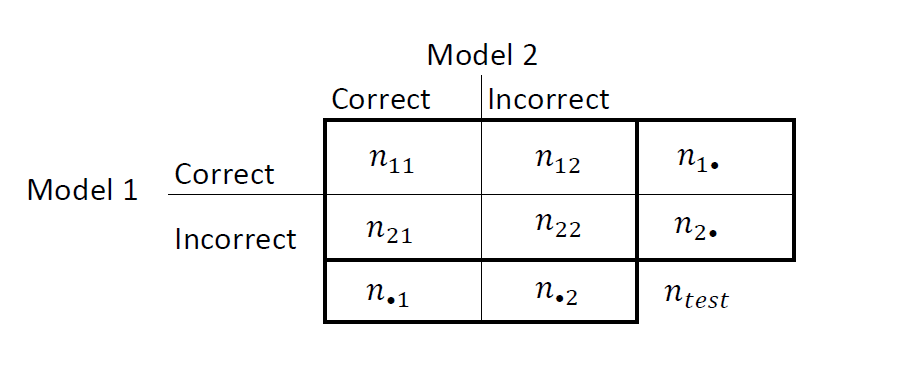
nii является количеством согласующихся пар, то есть, количеством наблюдений, что обе модели классифицируют тот же путь (правильно или неправильно). nij, i ≠ j, является количеством противоречащих пар, то есть, количеством наблюдений, что модели классифицируют по-другому (правильно или неправильно).
misclassification уровни для Моделей 1 и 2 и , соответственно. Двухсторонний тест для сравнения точности этих двух моделей
Нулевая гипотеза предполагает, что население показывает крайнюю однородность, которая уменьшает нулевую гипотезу до Кроме того, по нулевой гипотезе, N 12 ~ Биномов (n 12 + n 21 0.5) [1].
Эти факты являются базисом для доступных тестовых вариантов Макнемэра: asymptotic, exact-conditional и mid-p-value тесты Макнемэра. Определения, которые следуют, обобщают доступные варианты.
Асимптотический — асимптотическая тестовая статистика Макнемэра и области отклонения (для уровня значения α):
Для односторонних тестов тестовая статистическая величина
Если где Φ является стандартным Гауссовым cdf, затем отклоните H 0.
Для двухсторонних тестов тестовая статистическая величина
Если , где χm, 2 cdf, оцененные в x, затем отклоняют H 0.
Асимптотический тест требует теории большой выборки, а именно, Гауссова приближения к биномиальному распределению.
Общее количество противоречащих пар, , должен быть больше 10 ([1], Ch. 10.1.4).
В общем случае асимптотические тесты не гарантируют номинальное покрытие. Наблюдаемая вероятность ложного отклонения нулевой гипотезы может превысить α, как предложено в исследованиях симуляции в [18]. Однако асимптотический тест Макнемэра выполняет хорошо в терминах статистической степени.
Точное условное выражение — точное условное выражение тестовая статистика Макнемэра и области отклонения (для уровня значения α) ([36], [38]):
Для односторонних тестов тестовая статистическая величина
Если , где бином cdf с объемом выборки n и вероятность успеха, p, оцененный в x, затем отклоняет H 0.
Для двухсторонних тестов тестовая статистическая величина
Если , затем отклоните H 0.
Точно-условный тест всегда достигает номинального покрытия. Исследования симуляции в [18] предполагают, что тест консервативен, и затем покажите, что тест испытывает недостаток в статистической степени по сравнению с другими вариантами. Для маленьких или очень дискретных тестовых выборок рассмотрите использование теста mid-p-value ([1], Ch. 3.6.3).
Тест Mid-p-value — mid-p-value тестовая статистика Макнемэра и области отклонения (для уровня значения α) ([32]):
Для односторонних тестов тестовая статистическая величина
Если , где и бином cdf и PDF, соответственно, с объемом выборки n и вероятность успеха p, оцененный в x, затем отклоняет H 0.
Для двухсторонних тестов тестовая статистическая величина
Если , затем отклоните H 0.
Тест mid-p-value обращается к сверхконсервативному поведению точно-условного теста. Исследования симуляции в [18] демонстрируют, что этот тест достигает номинального покрытия и имеет хорошую статистическую силу.
Один способ выполнить нечувствительный к стоимости выбор признаков:
Обучите первую модель классификации (C1) использование полного предиктора установлено.
Обучите вторую модель классификации (C2) использование уменьшаемого предиктора установлено.
Задайте X1 как полные данные о предикторе набора тестов и X2 как уменьшаемые данные о предикторе набора тестов.
Введите compareHoldout(C1,C2,X1,X2,Y,'Alternative','less'). Если compareHoldout возвращает 1, затем существует достаточно доказательства, чтобы предположить, что модель классификации, которая использует меньше предикторов, выполняет лучше, чем модель, которая использует полный набор предиктора.
В качестве альтернативы можно оценить, существует ли значительная разница между точностью этих двух моделей. Чтобы выполнить эту оценку, удалите 'Alternative','less' спецификация на шаге 4. compareHoldout проводит двухсторонний тест и h = 0 указывает, что существует недостаточно доказательства, чтобы предложить различие в точности этих двух моделей.
Чувствительные к стоимости тесты выполняют числовую оптимизацию, которая требует дополнительных вычислительных ресурсов. Тест отношения правдоподобия проводит числовую оптимизацию косвенно путем нахождения корня множителя Лагранжа в интервале. Для некоторых наборов данных, если корень находится близко к контурам интервала, то метод может перестать работать. Поэтому, если вы имеете лицензию Optimization Toolbox, рассматриваете проведение чувствительного к стоимости теста хи-квадрата вместо этого. Для получения дополнительной информации смотрите CostTest и чувствительное к стоимости тестирование.
Чтобы непосредственно сравнить точность двух наборов меток класса в предсказании набора истинных меток класса, использовать testcholdout.
[1] Agresti, A. Анализ категориальных данных, 2-й Эд. John Wiley & Sons, Inc.: Хобокен, NJ, 2002.
[2] Fagerlan, M.W., С. Лидерсен и П. Лаак. “Тест Макнемэра для Бинарных Данных Совпадающих Пар: середина p и Асимптотический Лучше, Чем Точное Условное выражение”. BMC Медицинская Методология Исследования. Издание 13, 2013, стр 1–8.
[3] Ланкастер, H.O. “Тесты значения в Дискретных распределениях”. JASA, Издание 56, Номер 294, 1961, стр 223–234.
[4] Макнемэр, Q. “Примечание по Ошибке Выборки Различия Между Коррелироваными Пропорциями или Процентами”. Psychometrika, Издание 12, Номер 2, 1947, стр 153–157.
[5] Mosteller, F. “Некоторые Статистические проблемы в Измерении Субъективного Ответа на Наркотики”. Биометрика, Издание 8, Номер 3, 1952, стр 220–226.
