Подбирайте модель Gaussian process regression (GPR)
gprMdl = fitrgp(Tbl,ResponseVarName)Tbl, где ResponseVarName имя переменной отклика в Tbl.
gprMdl = fitrgp(___,Name,Value)Name,Value парные аргументы.
Например, можно задать подходящий метод, метод предсказания, функцию ковариации или активный метод выбора набора. Можно также обучить перекрестную подтвержденную модель.
gprMdl RegressionGP объект. Для методов и свойств этого класса, смотрите RegressionGP страница класса.
Если вы обучаете перекрестную подтвержденную модель, то gprMdl RegressionPartitionedModel объект. Для последующего анализа на перекрестном подтвержденном объекте используйте методы RegressionPartitionedModel класс. Для методов этого класса смотрите RegressionPartitionedModel страница класса.
Этот пример использует данные о морском ушке [1], [2], от Репозитория Машинного обучения UCI [3]. Загрузите данные и сохраните их в вашей текущей папке с именем abalone.data.
Храните данные в таблицу. Отобразите первые семь строк.
tbl = readtable('abalone.data','Filetype','text',... 'ReadVariableNames',false); tbl.Properties.VariableNames = {'Sex','Length','Diameter','Height',... 'WWeight','SWeight','VWeight','ShWeight','NoShellRings'}; tbl(1:7,:)
ans =
Sex Length Diameter Height WWeight SWeight VWeight ShWeight NoShellRings
___ ______ ________ ______ _______ _______ _______ ________ ____________
'M' 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15
'M' 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7
'F' 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21 9
'M' 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10
'I' 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7
'I' 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8
'F' 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20Набор данных имеет 4 177 наблюдений. Цель состоит в том, чтобы предсказать возраст морского ушка от восьми физических измерений. Последняя переменная, количество звонков интерпретатора показывает возраст морского ушка. Первый предиктор является категориальной переменной. Последняя переменная в таблице является переменной отклика.
Подбирайте модель GPR с помощью подмножества метода регрессоров для оценки параметра и полностью независимого условного метода для предсказания. Стандартизируйте предикторы.
gprMdl = fitrgp(tbl,'NoShellRings','KernelFunction','ardsquaredexponential',... 'FitMethod','sr','PredictMethod','fic','Standardize',1)
grMdl =
RegressionGP
PredictorNames: {1x8 cell}
ResponseName: 'Var9'
ResponseTransform: 'none'
NumObservations: 4177
KernelFunction: 'ARDSquaredExponential'
KernelInformation: [1x1 struct]
BasisFunction: 'Constant'
Beta: 10.9148
Sigma: 2.0243
PredictorLocation: [10x1 double]
PredictorScale: [10x1 double]
Alpha: [1000x1 double]
ActiveSetVectors: [1000x10 double]
PredictMethod: 'FIC'
ActiveSetSize: 1000
FitMethod: 'SR'
ActiveSetMethod: 'Random'
IsActiveSetVector: [4177x1 logical]
LogLikelihood: -9.0013e+03
ActiveSetHistory: [1x1 struct]
BCDInformation: []
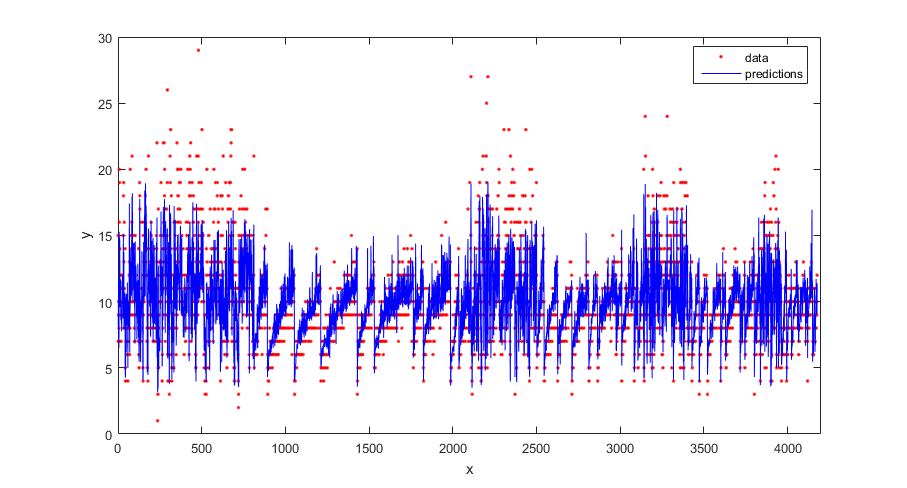
Предскажите ответы с помощью обученной модели.
ypred = resubPredict(gprMdl);
Постройте истинный ответ и предсказанные ответы.
figure(); plot(tbl.NoShellRings,'r.'); hold on plot(ypred,'b'); xlabel('x'); ylabel('y'); legend({'data','predictions'},'Location','Best'); axis([0 4300 0 30]); hold off;
Вычислите потерю регрессии на обучающих данных (потеря перезамены) для обученной модели.
L = resubLoss(gprMdl)
L =
4.0064Сгенерируйте выборочные данные.
rng(0,'twister'); % For reproducibility n = 1000; x = linspace(-10,10,n)'; y = 1 + x*5e-2 + sin(x)./x + 0.2*randn(n,1);
Подбирайте модель GPR с помощью линейной основной функции и точного подходящего метода, чтобы оценить параметры. Также используйте точный метод предсказания.
gprMdl = fitrgp(x,y,'Basis','linear',... 'FitMethod','exact','PredictMethod','exact');
Предскажите ответ, соответствующий строкам x (предсказания перезамены) использование обученной модели.
ypred = resubPredict(gprMdl);
Постройте истинный ответ с ожидаемыми значениями.
plot(x,y,'b.'); hold on; plot(x,ypred,'r','LineWidth',1.5); xlabel('x'); ylabel('y'); legend('Data','GPR predictions'); hold off

Загрузите выборочные данные.
load('gprdata2.mat')Данные имеют один переменный предиктор и непрерывный ответ. Это - симулированные данные.
Подбирайте модель GPR с помощью экспоненциальной функции ядра в квадрате параметрами ядра по умолчанию.
gprMdl1 = fitrgp(x,y,'KernelFunction','squaredexponential');
Теперь подбирайте вторую модель, где вы задаете начальные значения для параметров ядра.
sigma0 = 0.2; kparams0 = [3.5, 6.2]; gprMdl2 = fitrgp(x,y,'KernelFunction','squaredexponential',... 'KernelParameters',kparams0,'Sigma',sigma0);
Вычислите предсказания перезамены из обеих моделей.
ypred1 = resubPredict(gprMdl1); ypred2 = resubPredict(gprMdl2);
Постройте предсказания ответа из обеих моделей и ответов в обучающих данных.
figure(); plot(x,y,'r.'); hold on plot(x,ypred1,'b'); plot(x,ypred2,'g'); xlabel('x'); ylabel('y'); legend({'data','default kernel parameters',... 'kparams0 = [3.5,6.2], sigma0 = 0.2'},... 'Location','Best'); title('Impact of initial kernel parameter values'); hold off
![Figure contains an axes. The axes with title Impact of initial kernel parameter values contains 3 objects of type line. These objects represent data, default kernel parameters, kparams0 = [3.5,6.2], sigma0 = 0.2.](../examples/stats/win64/ImpactofSpecifyingInitialKernelParameterValuesExample_01.png)
Крайняя логарифмическая вероятность, что fitrgp максимизирует, чтобы оценить, что параметры GPR имеют несколько локальных решений; решение, к которому это сходится, зависит от начальной точки. Каждое локальное решение соответствует конкретной интерпретации данных. В этом примере решение начальными параметрами ядра по умолчанию соответствует низкочастотному сигналу с высоким шумом, тогда как второе решение пользовательскими начальными параметрами ядра соответствует высокочастотному сигналу с низким шумом.
Загрузите выборочные данные.
load('gprdata.mat')Существует шесть непрерывных переменных предикторов. Существует 500 наблюдений в обучающем наборе данных и 100 наблюдений в наборе тестовых данных. Это - симулированные данные.
Подбирайте модель GPR с помощью экспоненциальной функции ядра в квадрате с отдельной шкалой расстояний для каждого предиктора. Эта функция ковариации задана как:
где представляет шкалу расстояний для предиктора , = 1, 2, ..., и стандартное отклонение сигнала. Неограниченная параметризация
Инициализируйте шкалы расстояний функции ядра в 10 и и шумовых стандартных отклонений сигнала в стандартном отклонении ответа.
sigma0 = std(ytrain); sigmaF0 = sigma0; d = size(Xtrain,2); sigmaM0 = 10*ones(d,1);
Подбирайте модель GPR с помощью начальных значений параметров ядра. Стандартизируйте предикторы в обучающих данных. Используйте точный подбор кривой и методы предсказания.
gprMdl = fitrgp(Xtrain,ytrain,'Basis','constant','FitMethod','exact',... 'PredictMethod','exact','KernelFunction','ardsquaredexponential',... 'KernelParameters',[sigmaM0;sigmaF0],'Sigma',sigma0,'Standardize',1);
Вычислите потерю регрессии на тестовых данных.
L = loss(gprMdl,Xtest,ytest)
L = 0.6919
Доступ к информации о ядре.
gprMdl.KernelInformation
ans = struct with fields:
Name: 'ARDSquaredExponential'
KernelParameters: [7x1 double]
KernelParameterNames: {7x1 cell}
Отобразите названия параметра ядра.
gprMdl.KernelInformation.KernelParameterNames
ans = 7x1 cell
{'LengthScale1'}
{'LengthScale2'}
{'LengthScale3'}
{'LengthScale4'}
{'LengthScale5'}
{'LengthScale6'}
{'SigmaF' }
Отобразите параметры ядра.
sigmaM = gprMdl.KernelInformation.KernelParameters(1:end-1,1)
sigmaM = 6×1
104 ×
0.0004
0.0007
0.0004
5.2709
0.1018
0.0056
sigmaF = gprMdl.KernelInformation.KernelParameters(end)
sigmaF = 28.1721
sigma = gprMdl.Sigma
sigma = 0.8162
Постройте журнал изученных шкал расстояний.
figure() plot((1:d)',log(sigmaM),'ro-'); xlabel('Length scale number'); ylabel('Log of length scale');

Журнал шкалы расстояний для 4-х и 5-х переменных предикторов высок относительно других. Эти переменные предикторы, кажется, как не влияют на ответ как другие переменные предикторы.
Подбирайте модель GPR, не используя 4-е и 5-е переменные в качестве переменных предикторов.
X = [Xtrain(:,1:3) Xtrain(:,6)]; sigma0 = std(ytrain); sigmaF0 = sigma0; d = size(X,2); sigmaM0 = 10*ones(d,1); gprMdl = fitrgp(X,ytrain,'Basis','constant','FitMethod','exact',... 'PredictMethod','exact','KernelFunction','ardsquaredexponential',... 'KernelParameters',[sigmaM0;sigmaF0],'Sigma',sigma0,'Standardize',1);
Вычислите ошибку регрессии на тестовых данных.
xtest = [Xtest(:,1:3) Xtest(:,6)]; L = loss(gprMdl,xtest,ytest)
L = 0.6928
Потеря похожа на ту, когда все переменные используются в качестве переменных предикторов.
Вычислите предсказанный ответ для тестовых данных.
ypred = predict(gprMdl,xtest);
Постройте исходный ответ наряду с подходящими значениями.
figure; plot(ytest,'r'); hold on; plot(ypred,'b'); legend('True response','GPR predicted values','Location','Best'); hold off

В этом примере показано, как оптимизировать гиперпараметры автоматически с помощью fitrgp. Пример использует gprdata2 данные, которые поставляются с вашим программным обеспечением.
Загрузите данные.
load('gprdata2.mat')Данные имеют один переменный предиктор и непрерывный ответ. Это - симулированные данные.
Подбирайте модель GPR с помощью экспоненциальной функции ядра в квадрате параметрами ядра по умолчанию.
gprMdl1 = fitrgp(x,y,'KernelFunction','squaredexponential');
Найдите гиперпараметры, которые минимизируют пятикратную потерю перекрестной проверки при помощи автоматической гипероптимизации параметров управления.
Для воспроизводимости установите случайный seed и используйте 'expected-improvement-plus' функция приобретения.
rng default gprMdl2 = fitrgp(x,y,'KernelFunction','squaredexponential',... 'OptimizeHyperparameters','auto','HyperparameterOptimizationOptions',... struct('AcquisitionFunctionName','expected-improvement-plus'));
|======================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Sigma | | | result | log(1+loss) | runtime | (observed) | (estim.) | | |======================================================================================| | 1 | Best | 0.29417 | 4.8721 | 0.29417 | 0.29417 | 0.0015045 | | 2 | Best | 0.037898 | 2.9698 | 0.037898 | 0.060792 | 0.14147 | | 3 | Accept | 1.5693 | 2.2862 | 0.037898 | 0.040633 | 25.279 | | 4 | Accept | 0.29417 | 3.9255 | 0.037898 | 0.037984 | 0.0001091 | | 5 | Accept | 0.29393 | 3.575 | 0.037898 | 0.038029 | 0.029932 | | 6 | Accept | 0.13152 | 3.2312 | 0.037898 | 0.038127 | 0.37127 | | 7 | Best | 0.037785 | 5.189 | 0.037785 | 0.037728 | 0.18116 | | 8 | Accept | 0.03783 | 4.3223 | 0.037785 | 0.036524 | 0.16251 | | 9 | Accept | 0.037833 | 4.9764 | 0.037785 | 0.036854 | 0.16159 | | 10 | Accept | 0.037835 | 5.3911 | 0.037785 | 0.037052 | 0.16072 | | 11 | Accept | 0.29417 | 5.427 | 0.037785 | 0.03705 | 0.00038214 | | 12 | Accept | 0.42256 | 3.4003 | 0.037785 | 0.03696 | 3.2067 | | 13 | Accept | 0.03786 | 3.6868 | 0.037785 | 0.037087 | 0.15245 | | 14 | Accept | 0.29417 | 4.3881 | 0.037785 | 0.037043 | 0.0063584 | | 15 | Accept | 0.42302 | 3.1663 | 0.037785 | 0.03725 | 1.2221 | | 16 | Accept | 0.039486 | 2.6376 | 0.037785 | 0.037672 | 0.10069 | | 17 | Accept | 0.038591 | 3.091 | 0.037785 | 0.037687 | 0.12077 | | 18 | Accept | 0.038513 | 2.4893 | 0.037785 | 0.037696 | 0.1227 | | 19 | Best | 0.037757 | 2.0492 | 0.037757 | 0.037572 | 0.19621 | | 20 | Accept | 0.037787 | 3.169 | 0.037757 | 0.037601 | 0.18068 | |======================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Sigma | | | result | log(1+loss) | runtime | (observed) | (estim.) | | |======================================================================================| | 21 | Accept | 0.44917 | 2.4079 | 0.037757 | 0.03766 | 8.7818 | | 22 | Accept | 0.040201 | 3.4579 | 0.037757 | 0.037601 | 0.075414 | | 23 | Accept | 0.040142 | 3.7027 | 0.037757 | 0.037607 | 0.087198 | | 24 | Accept | 0.29417 | 5.0095 | 0.037757 | 0.03758 | 0.0031018 | | 25 | Accept | 0.29417 | 5.1286 | 0.037757 | 0.037555 | 0.00019545 | | 26 | Accept | 0.29417 | 4.7136 | 0.037757 | 0.037582 | 0.013608 | | 27 | Accept | 0.29417 | 3.9032 | 0.037757 | 0.037556 | 0.00076147 | | 28 | Accept | 0.42162 | 1.9316 | 0.037757 | 0.037854 | 0.6791 | | 29 | Best | 0.037704 | 2.7232 | 0.037704 | 0.037908 | 0.2367 | | 30 | Accept | 0.037725 | 3.5853 | 0.037704 | 0.037881 | 0.21743 |


__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 140.3815 seconds
Total objective function evaluation time: 110.8067
Best observed feasible point:
Sigma
______
0.2367
Observed objective function value = 0.037704
Estimated objective function value = 0.038223
Function evaluation time = 2.7232
Best estimated feasible point (according to models):
Sigma
_______
0.16159
Estimated objective function value = 0.037881
Estimated function evaluation time = 3.3839
Сравните пред - и подгонки постоптимизации.
ypred1 = resubPredict(gprMdl1); ypred2 = resubPredict(gprMdl2); figure(); plot(x,y,'r.'); hold on plot(x,ypred1,'b'); plot(x,ypred2,'k','LineWidth',2); xlabel('x'); ylabel('y'); legend({'data','Initial Fit','Optimized Fit'},'Location','Best'); title('Impact of Optimization'); hold off

Этот пример использует данные о морском ушке [1], [2], от Репозитория Машинного обучения UCI [3]. Загрузите данные и сохраните их в вашей текущей папке с именем abalone.data.
Храните данные в table. Отобразите первые семь строк.
tbl = readtable('abalone.data','Filetype','text','ReadVariableNames',false); tbl.Properties.VariableNames = {'Sex','Length','Diameter','Height','WWeight','SWeight','VWeight','ShWeight','NoShellRings'}; tbl(1:7,:)
ans =
Sex Length Diameter Height WWeight SWeight VWeight ShWeight NoShellRings
___ ______ ________ ______ _______ _______ _______ ________ ____________
'M' 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15
'M' 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7
'F' 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21 9
'M' 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10
'I' 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7
'I' 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8
'F' 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20Набор данных имеет 4 177 наблюдений. Цель состоит в том, чтобы предсказать возраст морского ушка от восьми физических измерений. Последняя переменная, количество звонков интерпретатора показывает возраст морского ушка. Первый предиктор является категориальной переменной. Последняя переменная в таблице является переменной отклика.
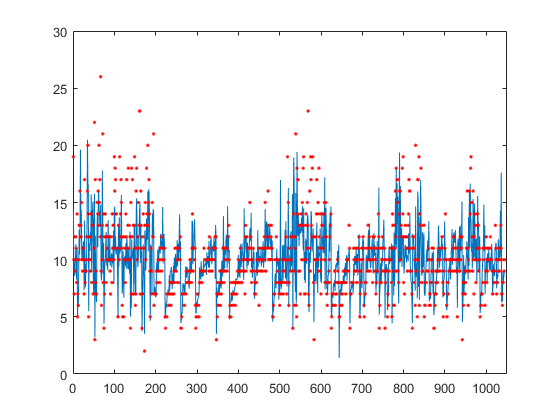
Обучите перекрестную подтвержденную модель GPR с помощью 25% данных для валидации.
rng('default') % For reproducibility cvgprMdl = fitrgp(tbl,'NoShellRings','Standardize',1,'Holdout',0.25);
Вычислите среднюю потерю на моделях использования сгибов, обученных на наблюдениях из сгиба.
kfoldLoss(cvgprMdl)
ans = 4.6409
Предскажите ответы для данных из сгиба.
ypred = kfoldPredict(cvgprMdl);
Постройте истинные ответы, используемые для тестирования и предсказаний.
figure(); plot(ypred(cvgprMdl.Partition.test)); hold on; y = table2array(tbl(:,end)); plot(y(cvgprMdl.Partition.test),'r.'); axis([0 1050 0 30]); xlabel('x') ylabel('y') hold off;
Сгенерируйте выборочные данные.
rng(0,'twister'); % For reproducibility n = 1000; x = linspace(-10,10,n)'; y = 1 + x*5e-2 + sin(x)./x + 0.2*randn(n,1);
Задайте экспоненциальную функцию ядра в квадрате как пользовательскую функцию ядра.
Можно вычислить экспоненциальную функцию ядра в квадрате как
где стандартное отклонение сигнала, шкала расстояний. Оба и должен быть больше нуля. Это условие может быть осуществлено неограниченной параметризацией, и , для некоторого неограниченного вектора параметризации .
Следовательно, можно задать экспоненциальную функцию ядра в квадрате как пользовательскую функцию ядра можно следующим образом:
kfcn = @(XN,XM,theta) (exp(theta(2))^2)*exp(-(pdist2(XN,XM).^2)/(2*exp(theta(1))^2));
Здесь pdist2(XN,XM).^2 вычисляет матрицу расстояния.
Подбирайте модель GPR с помощью пользовательской функции ядра, kfcn. Задайте начальные значения параметров ядра (Поскольку вы используете пользовательскую функцию ядра, необходимо ввести начальные значения для неограниченного вектора параметризации, theta).
theta0 = [1.5,0.2]; gprMdl = fitrgp(x,y,'KernelFunction',kfcn,'KernelParameters',theta0);
fitrgp использует аналитические производные, чтобы оценить параметры при использовании встроенной функции ядра, тогда как при использовании пользовательского ядра функционируют, это использует числовые производные.
Вычислите потерю перезамены для этой модели.
L = resubLoss(gprMdl)
L = 0.0391
Подбирайте модель GPR с помощью встроенной экспоненциальной опции функции ядра в квадрате. Задайте начальные значения параметров ядра (Поскольку вы используете встроенную пользовательскую функцию ядра и задающий начальные значения параметров, необходимо ввести начальные значения для стандартного отклонения сигнала и шкалы (шкал) расстояний непосредственно).
sigmaL0 = exp(1.5); sigmaF0 = exp(0.2); gprMdl2 = fitrgp(x,y,'KernelFunction','squaredexponential','KernelParameters',[sigmaL0,sigmaF0]);
Вычислите потерю перезамены для этой модели.
L2 = resubLoss(gprMdl2)
L2 = 0.0391
Два значения потерь эквивалентны ожидаемый.
Обучите модель GPR на сгенерированных данных со многими предикторами. Задайте начальный размер шага для оптимизатора LBFGS.
Установите seed и тип генератора случайных чисел для воспроизводимости результатов.
rng(0,'twister'); % For reproducibility
Сгенерируйте выборочные данные с 300 наблюдениями и 3 000 предикторов, где переменная отклика зависит от 4-х, 7-х, и 13-х предикторов.
N = 300; P = 3000; X = rand(N,P); y = cos(X(:,7)) + sin(X(:,4).*X(:,13)) + 0.1*randn(N,1);
Установите начальные значения для параметров ядра.
sigmaL0 = sqrt(P)*ones(P,1); % Length scale for predictors sigmaF0 = 1; % Signal standard deviation
Установите начальное шумовое стандартное отклонение на 1.
sigmaN0 = 1;
Specify 1e-2 как допуск завершения к относительной норме градиента.
opts = statset('fitrgp');
opts.TolFun = 1e-2;Подбирайте модель GPR с помощью начальных значений параметров ядра, начального шумового стандартного отклонения, и автоматическое определение уместности (ARD) придало экспоненциальной функции ядра квадратную форму.
Задайте начальный размер шага как 1 для определения начального приближения Гессиана для оптимизатора LBFGS.
gpr = fitrgp(X,y,'KernelFunction','ardsquaredexponential','Verbose',1, ... 'Optimizer','lbfgs','OptimizerOptions',opts, ... 'KernelParameters',[sigmaL0;sigmaF0],'Sigma',sigmaN0,'InitialStepSize',1);
o Parameter estimation: FitMethod = Exact, Optimizer = lbfgs
o Solver = LBFGS, HessianHistorySize = 15, LineSearchMethod = weakwolfe
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 0 | 3.004966e+02 | 2.569e+02 | 0.000e+00 | | 3.893e-03 | 0.000e+00 | YES |
| 1 | 9.525779e+01 | 1.281e+02 | 1.003e+00 | OK | 6.913e-03 | 1.000e+00 | YES |
| 2 | 3.972026e+01 | 1.647e+01 | 7.639e-01 | OK | 4.718e-03 | 5.000e-01 | YES |
| 3 | 3.893873e+01 | 1.073e+01 | 1.057e-01 | OK | 3.243e-03 | 1.000e+00 | YES |
| 4 | 3.859904e+01 | 5.659e+00 | 3.282e-02 | OK | 3.346e-03 | 1.000e+00 | YES |
| 5 | 3.748912e+01 | 1.030e+01 | 1.395e-01 | OK | 1.460e-03 | 1.000e+00 | YES |
| 6 | 2.028104e+01 | 1.380e+02 | 2.010e+00 | OK | 2.326e-03 | 1.000e+00 | YES |
| 7 | 2.001849e+01 | 1.510e+01 | 9.685e-01 | OK | 2.344e-03 | 1.000e+00 | YES |
| 8 | -7.706109e+00 | 8.340e+01 | 1.125e+00 | OK | 5.771e-04 | 1.000e+00 | YES |
| 9 | -1.786074e+01 | 2.323e+02 | 2.647e+00 | OK | 4.217e-03 | 1.250e-01 | YES |
| 10 | -4.058422e+01 | 1.972e+02 | 6.796e-01 | OK | 7.035e-03 | 1.000e+00 | YES |
| 11 | -7.850209e+01 | 4.432e+01 | 8.335e-01 | OK | 3.099e-03 | 1.000e+00 | YES |
| 12 | -1.312162e+02 | 3.334e+01 | 1.277e+00 | OK | 5.432e-02 | 1.000e+00 | YES |
| 13 | -2.005064e+02 | 9.519e+01 | 2.828e+00 | OK | 5.292e-03 | 1.000e+00 | YES |
| 14 | -2.070150e+02 | 1.898e+01 | 1.641e+00 | OK | 6.817e-03 | 1.000e+00 | YES |
| 15 | -2.108086e+02 | 3.793e+01 | 7.685e-01 | OK | 3.479e-03 | 1.000e+00 | YES |
| 16 | -2.122920e+02 | 7.057e+00 | 1.591e-01 | OK | 2.055e-03 | 1.000e+00 | YES |
| 17 | -2.125610e+02 | 4.337e+00 | 4.818e-02 | OK | 1.974e-03 | 1.000e+00 | YES |
| 18 | -2.130162e+02 | 1.178e+01 | 8.891e-02 | OK | 2.856e-03 | 1.000e+00 | YES |
| 19 | -2.139378e+02 | 1.933e+01 | 2.371e-01 | OK | 1.029e-02 | 1.000e+00 | YES |
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 20 | -2.151111e+02 | 1.550e+01 | 3.015e-01 | OK | 2.765e-02 | 1.000e+00 | YES |
| 21 | -2.173046e+02 | 5.856e+00 | 6.537e-01 | OK | 1.414e-02 | 1.000e+00 | YES |
| 22 | -2.201781e+02 | 8.918e+00 | 8.484e-01 | OK | 6.381e-03 | 1.000e+00 | YES |
| 23 | -2.288858e+02 | 4.846e+01 | 2.311e+00 | OK | 2.661e-03 | 1.000e+00 | YES |
| 24 | -2.392171e+02 | 1.190e+02 | 6.283e+00 | OK | 8.113e-03 | 1.000e+00 | YES |
| 25 | -2.511145e+02 | 1.008e+02 | 1.198e+00 | OK | 1.605e-02 | 1.000e+00 | YES |
| 26 | -2.742547e+02 | 2.207e+01 | 1.231e+00 | OK | 3.191e-03 | 1.000e+00 | YES |
| 27 | -2.849931e+02 | 5.067e+01 | 3.660e+00 | OK | 5.184e-03 | 1.000e+00 | YES |
| 28 | -2.899797e+02 | 2.068e+01 | 1.162e+00 | OK | 6.270e-03 | 1.000e+00 | YES |
| 29 | -2.916723e+02 | 1.816e+01 | 3.213e-01 | OK | 1.415e-02 | 1.000e+00 | YES |
| 30 | -2.947674e+02 | 6.965e+00 | 1.126e+00 | OK | 6.339e-03 | 1.000e+00 | YES |
| 31 | -2.962491e+02 | 1.349e+01 | 2.352e-01 | OK | 8.999e-03 | 1.000e+00 | YES |
| 32 | -3.004921e+02 | 1.586e+01 | 9.880e-01 | OK | 3.940e-02 | 1.000e+00 | YES |
| 33 | -3.118906e+02 | 1.889e+01 | 3.318e+00 | OK | 1.213e-01 | 1.000e+00 | YES |
| 34 | -3.189215e+02 | 7.086e+01 | 3.070e+00 | OK | 8.095e-03 | 1.000e+00 | YES |
| 35 | -3.245557e+02 | 4.366e+00 | 1.397e+00 | OK | 2.718e-03 | 1.000e+00 | YES |
| 36 | -3.254613e+02 | 3.751e+00 | 6.546e-01 | OK | 1.004e-02 | 1.000e+00 | YES |
| 37 | -3.262823e+02 | 4.011e+00 | 2.026e-01 | OK | 2.441e-02 | 1.000e+00 | YES |
| 38 | -3.325606e+02 | 1.773e+01 | 2.427e+00 | OK | 5.234e-02 | 1.000e+00 | YES |
| 39 | -3.350374e+02 | 1.201e+01 | 1.603e+00 | OK | 2.674e-02 | 1.000e+00 | YES |
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 40 | -3.379112e+02 | 5.280e+00 | 1.393e+00 | OK | 1.177e-02 | 1.000e+00 | YES |
| 41 | -3.389136e+02 | 3.061e+00 | 7.121e-01 | OK | 2.935e-02 | 1.000e+00 | YES |
| 42 | -3.401070e+02 | 4.094e+00 | 6.224e-01 | OK | 3.399e-02 | 1.000e+00 | YES |
| 43 | -3.436291e+02 | 8.833e+00 | 1.707e+00 | OK | 5.231e-02 | 1.000e+00 | YES |
| 44 | -3.456295e+02 | 5.891e+00 | 1.424e+00 | OK | 3.772e-02 | 1.000e+00 | YES |
| 45 | -3.460069e+02 | 1.126e+01 | 2.580e+00 | OK | 3.907e-02 | 1.000e+00 | YES |
| 46 | -3.481756e+02 | 1.546e+00 | 8.142e-01 | OK | 1.565e-02 | 1.000e+00 | YES |
Infinity norm of the final gradient = 1.546e+00
Two norm of the final step = 8.142e-01, TolX = 1.000e-12
Relative infinity norm of the final gradient = 6.016e-03, TolFun = 1.000e-02
EXIT: Local minimum found.
o Alpha estimation: PredictMethod = Exact
Поскольку модель GPR использует ядро ARD со многими предикторами, использование приближения LBFGS к Гессиану использует память более эффективно, чем хранение полной матрицы Гессиана. Кроме того, использование начального размера шага, чтобы определить начальное приближение Гессиана может помочь ускорить оптимизацию.
Найдите веса предиктора путем взятия экспоненциала отрицательных изученных шкал расстояний. Нормируйте веса.
sigmaL = gpr.KernelInformation.KernelParameters(1:end-1); % Learned length scales weights = exp(-sigmaL); % Predictor weights weights = weights/sum(weights); % Normalized predictor weights
Постройте нормированные веса предиктора.
figure; semilogx(weights,'ro'); xlabel('Predictor index'); ylabel('Predictor weight');

Обученная модель GPR присваивает самые большие веса 4-м, 7-м, и 13-м предикторам. Несоответствующие предикторы имеют веса близко к нулю.
fitrgp принимает любую комбинацию подбора кривой, предсказания и активных методов выбора набора. В некоторых случаях не может быть возможно вычислить стандартные отклонения предсказанных ответов, следовательно интервалы предсказания. Смотрите predict. И в некоторых случаях, использование точного метода может быть дорогим из-за размера обучающих данных.
PredictorNames свойство хранит один элемент для каждого из исходных имен переменного предиктора. Например, если существует три предиктора, один из которых является категориальной переменной с тремя уровнями, PredictorNames 1 3 массив ячеек из символьных векторов.
ExpandedPredictorNames свойство хранит один элемент для каждого из переменных предикторов, включая фиктивные переменные. Например, если существует три предиктора, один из которых является категориальной переменной с тремя уровнями, затем ExpandedPredictorNames массив ячеек из символьных векторов 1 на 5.
Точно так же Beta свойство хранит один бета коэффициент для каждого предиктора, включая фиктивные переменные.
X свойство хранит обучающие данные, как первоначально введено. Это не включает фиктивные переменные.
Подход по умолчанию к инициализации приближения Гессиана в fitrgp может быть медленным, когда у вас есть модель GPR многими параметрами ядра, такой как тогда, когда с помощью ядра ARD со многими предикторами. В этом случае считайте определение 'auto' или значение для начального размера шага.
Можно установить 'Verbose',1 для отображения итеративных диагностических сообщений, и начинают обучение модель GPR с помощью LBFGS или оптимизатора квазиньютона со значением по умолчанию fitrgp оптимизация. Если итеративные диагностические сообщения не отображены после нескольких секунд возможно, что инициализация приближения Гессиана занимает слишком много времени. В этом случае полагайте, что обучение перезапуску и использование начального размера шага ускоряют оптимизацию.
После обучения модель можно сгенерировать код C/C++, который предсказывает ответы для новых данных. Генерация кода C/C++ требует MATLAB Coder™. Для получения дополнительной информации смотрите Введение в Генерацию кода..
Подбирать модель GPR включает оценку следующих параметров модели из данных:
Функция ковариации параметрированный в терминах параметров ядра в векторе (см. ядро (ковариация) опции функции),
Шумовое отклонение,
Вектор коэффициентов фиксированных основных функций,
Значение 'KernelParameters' аргументом пары "имя-значение" является вектор, который состоит из начальных значений для стандартного отклонения сигнала и характеристические шкалы расстояний . fitrgp функционируйте использует эти значения, чтобы определить параметры ядра. Точно так же 'Sigma' аргумент пары "имя-значение" содержит начальное значение для шумового стандартного отклонения .
Во время оптимизации, fitrgp создает вектор из неограниченных начальных значений параметров при помощи начальных значений для шумового стандартного отклонения и параметров ядра.
fitrgp аналитически определяет явные базисные коэффициенты , заданный 'Beta' аргумент пары "имя-значение", от ориентировочных стоимостей и . Поэтому не появляется в вектор, когда fitrgp инициализирует числовую оптимизацию.
Примечание
Если вы не задаете оценки параметров для модели GPR, fitrgp использует значение 'Beta' аргумент пары "имя-значение" и другие начальные значения параметров как известные значения параметров GPR (см. Beta). Во всех других случаях, значении 'Beta' аргумент оптимизирован аналитически от целевой функции.
Оптимизатор квазиньютона использует метод доверительной области с плотным, симметричным rank-1-based (SR1), приближением квазиньютона к Гессиану, в то время как оптимизатор LBFGS использует стандартный метод поиска линии приближением квазиньютона ограниченной памяти Бройдена Флетчера Голдфарба Шэнно (LBFGS) к Гессиану. Смотрите Носедэла и Райта [6].
Если вы устанавливаете 'InitialStepSize' аргумент пары "имя-значение" 'auto', fitrgp определяет начальный размер шага, , при помощи .
начальный вектор шага, и вектор из неограниченных начальных значений параметров.
Во время оптимизации, fitrgp использует начальный размер шага, , можно следующим образом:
Если вы используете 'Optimizer','quasinewton' с начальным размером шага затем начальное приближение Гессиана .
Если вы используете 'Optimizer','lbfgs' с начальным размером шага затем начальное приближение обратного Гессиана .
начальный вектор градиента, и единичная матрица.
[1] Нэш, W.J., Т. Л. Селлерс, С. Р. Тэлбот, А. Дж. Которн и В. Б. Форд. "Биология Населения Морского ушка (разновидности Haliotis) на Тасмании. I. Морское ушко Blacklip (H. rubra) от Северного Побережья и Островов Пролива Басса". Морское Деление Рыболовства, Технический отчет № 48, 1994.
[2] Во, S. "Расширяя и Тестируя Каскадной Корреляции в сравнении с эталоном: Расширения Архитектуры Каскадной Корреляции и Сравнительное тестирование Feedforward Контролируемые Искусственные Нейронные сети". Университет тезиса Факультета информатики Тасмании, 1995.
[3] Личмен, M. Репозиторий Машинного обучения UCI, Ирвин, CA: Калифорнийский университет, Школа Информатики и вычислительной техники, 2013. http://archive.ics.uci.edu/ml.
[4] Расмуссен, C. E. и К. К. Ай. Уильямс. Гауссовы процессы для машинного обучения. Нажатие MIT. Кембридж, Массачусетс, 2006.
[5] Lagarias, J. C. Дж. А. Ридс, М. Х. Райт и П. Э. Райт. "Свойства сходимости Симплекс-метода Nelder-меда в Низких Размерностях". SIAM Journal Оптимизации. Издание 9, Номер 1, 1998, стр 112–147.
[6] Nocedal, J. и С. Дж. Райт. Числовая оптимизация, второй выпуск. Ряд Спрингера в исследовании операций, Springer Verlag, 2006.
