Потеря классификации для перекрестной подтвержденной модели классификации
L = kfoldLoss(CVMdl)CVMdl классификации. Для каждого сгиба, kfoldLoss вычисляет потерю классификации для наблюдений сгиба валидации с помощью классификатора, обученного на наблюдениях учебного сгиба. CVMdl.X и CVMdl.Y содержите оба набора наблюдений.
L = kfoldLoss(CVMdl,Name,Value)
Загрузите ionosphere набор данных.
load ionosphereВырастите дерево классификации.
tree = fitctree(X,Y);
Перекрестный подтвердите дерево классификации использование 10-кратной перекрестной проверки.
cvtree = crossval(tree);
Оцените перекрестную подтвержденную ошибку классификации.
L = kfoldLoss(cvtree)
L = 0.1083
Загрузите ionosphere набор данных.
load ionosphereОбучите ансамбль классификации 100 деревьев решений с помощью AdaBoostM1. Задайте пни как слабых учеников.
t = templateTree('MaxNumSplits',1); ens = fitcensemble(X,Y,'Method','AdaBoostM1','Learners',t);
Перекрестный подтвердите ансамбль, использующий 10-кратную перекрестную проверку.
cvens = crossval(ens);
Оцените перекрестную подтвержденную ошибку классификации.
L = kfoldLoss(cvens)
L = 0.0655
kfoldLossОбучите перекрестную подтвержденную обобщенную аддитивную модель (GAM) с 10 сгибами. Затем используйте kfoldLoss вычислить совокупные ошибки классификации перекрестных проверок (misclassification уровень в десятичном числе). Используйте ошибки определить оптимальное количество деревьев на предиктор (линейный член для предиктора) и оптимальное количество деревьев в период взаимодействия.
В качестве альтернативы можно найти оптимальные значения fitcgam аргументы значения имени при помощи bayesopt функция. Для примера смотрите, Оптимизируют перекрестный Подтвержденный GAM Используя bayesopt.
Загрузите ionosphere набор данных. Этот набор данных имеет 34 предиктора, и 351 бинарный ответ для радара возвращается, любой плохо ('b') или хороший ('g').
load ionosphereСоздайте перекрестный подтвержденный GAM при помощи опции перекрестной проверки по умолчанию. Задайте 'CrossVal' аргумент значения имени как 'on'. Задайте, чтобы включать все доступные периоды взаимодействия, p-значения которых не больше 0.05.
rng('default') % For reproducibility CVMdl = fitcgam(X,Y,'CrossVal','on','Interactions','all','MaxPValue',0.05);
Если вы задаете 'Mode' как 'cumulative' для kfoldLoss, затем функция возвращает совокупные ошибки, которые являются средними погрешностями через все сгибы, полученные с помощью того же количества деревьев для каждого сгиба. Отобразите количество деревьев для каждого сгиба.
CVMdl.NumTrainedPerFold
ans = struct with fields:
PredictorTrees: [65 64 59 61 60 66 65 62 64 61]
InteractionTrees: [1 2 2 2 2 1 2 2 2 2]
kfoldLoss может вычислить совокупные ошибки до 59 деревьев предиктора и одно дерево взаимодействия.
Постройте совокупное, перекрестное подтвержденное 10-кратное, ошибка классификации (misclassification уровень в десятичном числе). Задайте 'IncludeInteractions' как false исключить периоды взаимодействия из расчета.
L_noInteractions = kfoldLoss(CVMdl,'Mode','cumulative','IncludeInteractions',false); figure plot(0:min(CVMdl.NumTrainedPerFold.PredictorTrees),L_noInteractions)

Первый элемент L_noInteractions средняя погрешность по всем сгибам, полученным с помощью только точку пересечения (постоянный) термин. (J+1) элемент th L_noInteractions полученное использование средней погрешности термина точки пересечения и первого J деревья предиктора на линейный член. Графический вывод совокупной потери позволяет вам контролировать, как ошибка изменяется как количество деревьев предиктора в увеличениях GAM.
Найдите минимальную ошибку, и количество деревьев предиктора раньше достигало минимальной ошибки.
[M,I] = min(L_noInteractions)
M = 0.0655
I = 23
GAM достигает минимальной ошибки, когда это включает 22 дерева предиктора.
Вычислите совокупную ошибку классификации и линейные члены и периоды взаимодействия.
L = kfoldLoss(CVMdl,'Mode','cumulative')
L = 2×1
0.0712
0.0712
Первый элемент L средняя погрешность по всем сгибам, полученным с помощью точки пересечения (постоянный) термин и все деревья предиктора на линейный член. Второй элемент L полученное использование средней погрешности термина точки пересечения, всех деревьев предиктора на линейный член и одного дерева взаимодействия в период взаимодействия. Ошибка не уменьшается, когда периоды взаимодействия добавляются.
Если вы удовлетворены ошибкой, когда количество деревьев предиктора равняется 22, можно создать прогнозную модель по образованию одномерный GAM снова и определение 'NumTreesPerPredictor',22 без перекрестной проверки.
Функции Classification loss измеряют прогнозирующую погрешность моделей классификации. Когда вы сравниваете тот же тип потери среди многих моделей, более низкая потеря указывает на лучшую прогнозную модель.
Рассмотрите следующий сценарий.
L является средневзвешенной потерей классификации.
n является объемом выборки.
Для бинарной классификации:
yj является наблюдаемой меткой класса. Программные коды это как –1 или 1, указывая на отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) является классификационной оценкой положительного класса для наблюдения (строка) j данных о предикторе X.
mj = yj f (Xj) является классификационной оценкой для классификации наблюдения j в класс, соответствующий yj. Положительные значения mj указывают на правильную классификацию и не способствуют очень средней потере. Отрицательные величины mj указывают на неправильную классификацию и значительно способствуют средней потере.
Для алгоритмов, которые поддерживают классификацию мультиклассов (то есть, K ≥ 3):
yj* является вектором из K – 1 нуль, с 1 в положении, соответствующем истинному, наблюдаемому классу yj. Например, если истинный класс второго наблюдения является третьим классом и K = 4, то y 2* = [0 0 1 0] ′. Порядок классов соответствует порядку в ClassNames свойство входной модели.
f (Xj) является длиной вектор K из музыки класса к наблюдению j данных о предикторе X. Порядок баллов соответствует порядку классов в ClassNames свойство входной модели.
mj = yj* ′ f (Xj). Поэтому mj является скалярной классификационной оценкой, которую модель предсказывает для истинного, наблюдаемого класса.
Весом для наблюдения j является wj. Программное обеспечение нормирует веса наблюдения так, чтобы они суммировали к соответствующей предшествующей вероятности класса. Программное обеспечение также нормирует априорные вероятности, таким образом, они суммируют к 1. Поэтому
Учитывая этот сценарий, следующая таблица описывает поддерживаемые функции потерь, которые можно задать при помощи 'LossFun' аргумент пары "имя-значение".
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Неправильно классифицированный уровень в десятичном числе | 'classiferror' | метка класса, соответствующая классу с максимальным счетом. I {·} является функцией индикатора. |
| Потеря перекрестной энтропии | 'crossentropy' |
Взвешенная потеря перекрестной энтропии где веса нормированы, чтобы суммировать к n вместо 1. |
| Экспоненциальная потеря | 'exponential' | |
| Потеря стержня | 'hinge' | |
| Потеря логита | 'logit' | |
| Минимальный ожидал стоимость misclassification | 'mincost' |
Программное обеспечение вычисляет взвешенную минимальную ожидаемую стоимость классификации с помощью этой процедуры для наблюдений j = 1..., n.
Взвешенное среднее минимального ожидало, что потеря стоимости misclassification Если вы используете матрицу стоимости по умолчанию (чье значение элемента 0 для правильной классификации и 1 для неправильной классификации), то |
| Квадратичная потеря | 'quadratic' |
Этот рисунок сравнивает функции потерь (кроме 'crossentropy' и 'mincost') по счету m для одного наблюдения. Некоторые функции нормированы, чтобы пройти через точку (0,1).
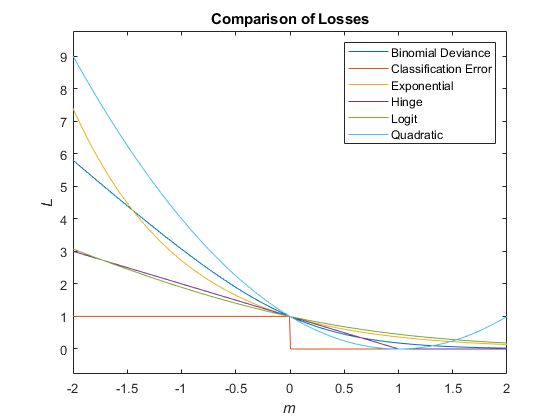
kfoldLoss вычисляет потерю классификации как описано в соответствии loss объектная функция. Для описания модели специфичного смотрите соответствующее loss страница ссылки на функцию в следующей таблице.
| Тип модели | loss Функция |
|---|---|
| Классификатор дискриминантного анализа | loss |
| Классификатор ансамбля | loss |
| Обобщенный аддитивный классификатор модели | loss |
| k- соседний классификатор | loss |
| Наивный классификатор Байеса | loss |
| Классификатор нейронной сети | loss |
| Классификатор машины опорных векторов | loss |
| Дерево выбора из двух альтернатив для классификации мультиклассов | loss |
ClassificationPartitionedModel | kfoldEdge | kfoldfun | kfoldMargin | kfoldPredict
