Вычислить количество операций чтения, сопоставленных с геномными элементами
T = featurecount(GTFfile,Inputfile)Inputfile которые сопоставляются с геномными элементами, как указано в файле в формате GTF GTFfile. GTFfile указывает файл аннотаций. Inputfile указывает имена файлов BAM или SAM, которые необходимо рассмотреть. Продукция T - таблица, в которой строки соответствуют функциям, а столбцы - входным файлам. Элементы таблицы состоят из числа чтений, сопоставляемых каждому элементу для данного входного файла.
[___] = featurecount(___, использует дополнительные параметры, указанные одним или несколькими Name,Value)Name,Value аргументы пары.
GTFfile - имя файла в формате GTFИмя файла в формате GTF, указанное как символьный вектор или строка.
Пример: 'Dmel_BDGP5_nohc.gtf'
Inputfile - имя файла в формате BAM или SAMИмя файла в формате BAM или SAM, указанное как символьный вектор, строка, строковый вектор или массив ячеек символьных векторов.
Пример: 'rnaseq_sample1.sam'
Укажите дополнительные пары, разделенные запятыми Name,Value аргументы. Name является именем аргумента и Value - соответствующее значение. Name должен отображаться внутри кавычек. Можно указать несколько аргументов пары имен и значений в любом порядке как Name1,Value1,...,NameN,ValueN.
'CountFragments',true указывает считать чтения как пары пар.'BothEndsMapped' - логическая переменная, указывающая, должен ли фрагмент иметь сопоставленные пары;false (по умолчанию) | trueЛогическая переменная, указывающая, должен ли фрагмент иметь обе совмещения, указанная как true или false. Сведения о сопоставлении получаются из FLAG во входном файле. По умолчанию: false.
'ProperlyPaired' - логическая переменная, указывающая, должен ли фрагмент быть правильно спаренfalse (по умолчанию) | trueЛогическая переменная, указывающая, должен ли фрагмент быть правильно спарен, указанная как true или false. Информация о спаривании пар извлекается из FLAG во входном файле. По умолчанию: false.
'ShowZeroCounts' - Логическая переменная, указывающая, следует ли сообщать элементы или метафайты с нулевым числомfalse (по умолчанию) | trueЛогическая переменная, указывающая, следует ли сообщать элементы или метафайты с нулевым числом для каждого входного файла в выходной таблице, указанная как true или false.
По умолчанию: falseто есть в выходную таблицу включаются только строки с ненулевыми счетчиками и столбцы с ненулевыми счетчиками.
'OverlapMethod' - Метод, используемый при назначении данного считывания метафеатуре'partial' (по умолчанию) | 'full' | 'max' | 'hits'Метод, используемый при назначении данного чтения метафеатуре, указанный как 'partial', 'full', 'max', или 'hits'. Если 'Summarization' имеет значение false, то чтения назначаются элементам, вместо метафеатур, на основе указанного метода.
В следующей таблице R относится к считыванию или фрагменту, а M относится к метафеатуре.
| Метод | Описание |
|---|---|
'partial' | R присваивается M, если R перекрывается (даже частично) только с M. Иначе R считается неоднозначным. |
'full' | R назначается M, если R полностью отображается только в пределах M, то есть полностью перекрывает только M. В противном случае R считается неоднозначным |
'max' | R присваивается M, если R удовлетворяет критериям перекрытия только с М, или если R удовлетворяет критериям перекрытия с несколькими метафеатурами, но полностью перекрывается только с М. |
'hits' | R присваивается M, если R перекрывает даже частично только M, или если M является единственной метафеатурой с наибольшим количеством признаков, пораженных R; в противном случае R считается неоднозначным. |
Следующая принципиальная схема и таблица иллюстрируют результаты этих методов в сочетании с 'CountMultiOverlap' аргумент пары имя-значение. На рисунке считывание относится к короткой последовательности считывания из входного файла, а элемент A и элемент B относятся к элементам, перечисленным в файле GTF.
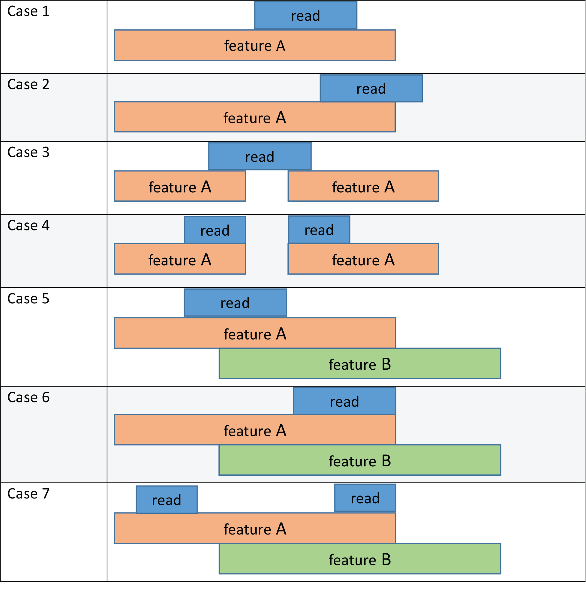
В каждом столбце метода перечисляется функция, которой назначено считывание на основе соответствующего метода. 'CountMultiOverlap' столбец указывает, имеет ли эта пара имя-значение значение true или false и если это оказывает какое-либо влияние на результат каждого метода.
'CountMultiOverlap' | 'partial' | 'full' | 'max' | 'hits' | |
|---|---|---|---|---|---|
| Случай 1 | Эффект отсутствует, так как чтение сопоставляется только с одной функцией (функция A). | Функция A | Функция A | Функция A | Функция A |
| Дело 2 | Эффект отсутствует, так как чтение сопоставляется только с одной функцией (функция A). | Функция A | нет функции | Функция A | Функция A |
| Дело 3 | Эффект отсутствует, так как чтение сопоставляется только с одной функцией (функция A). | Функция A | нет функции | Функция A | Функция A |
| Дело 4 | Эффект отсутствует, так как чтение сопоставляется только с одной функцией (функция A). | Функция A | Функция A | Функция A | Функция A |
| Дело 5 | false | неоднозначный | Функция A | Функция A | неоднозначный |
true | элемент A, элемент B | Функция A | Функция A | элемент A, элемент B | |
| Дело 6 | false | неоднозначный | неоднозначный | неоднозначный | неоднозначный |
true | элемент A, элемент B | элемент A, элемент B | элемент A, элемент B | элемент A, элемент B | |
| Дело 7 | false | Неоднозначный | Функция A | Функция A | Функция A |
true | элемент A, элемент B | Функция A | Функция A | Функция A |
no feature означает, что считывание не назначено ни одному элементу. Если указана вторая выходная таблица Sего Unassigned_noFeature для такого вхождения строка увеличивается на единицу. неоднозначно означает, что считывание не назначено ни одному элементу, поскольку оно удовлетворяет критериям перекрытия для нескольких элементов, и Unassigned_ambiguous для такого вхождения строка увеличивается на единицу.
'UseParallel' - логическая переменная, указывающая, следует ли вычислять параллельно;false (по умолчанию) | trueЛогическая переменная, указывающая, следует ли вычислять параллельно, указанная как true или false.
Для параллельного выполнения вычислений необходимо наличие Toolbox™ параллельных вычислений. Если параллельный пул MATLAB ® не существует, он автоматически создается, если в настройках параллельного создания включена опция автоматического создания. В противном случае вычисления выполняются в последовательном режиме.
По умолчанию: false, то есть последовательный режим.
'Verbose' - Логическая переменная, указывающая, отображать ли ход вычисленийtrue (по умолчанию) | falseЛогическая переменная, указывающая, отображать ли ход вычислений, указанная как true или false.
