Выравнивание двух наборов данных, содержащих последовательные наблюдения, путем введения пробелов
[I, J] = samplealign(X, Y)
[I, J] = samplealign(X, Y, ...'Band', BandValue, ...)
[I, J] = samplealign(X, Y, ...'Width', WidthValue, ...)
[I, J] = samplealign(X, Y, ...'Gap', GapValue, ...)
[I, J] = samplealign(X, Y, ...'Quantile', QuantileValue, ...)
[I, J] = samplealign(X, Y, ...'Distance', DistanceValue, ...)
[I, J] = samplealign(X, Y, ...'Weights', WeightsValue, ...)
[I, J] = samplealign(X, Y, ...'ShowConstraints', ShowConstraintsValue, ...)
[I, J] = samplealign(X, Y, ...'ShowNetwork', ShowNetworkValue, ...)
[I, J] = samplealign(X, Y, ...'ShowAlignment', ShowAlignmentValue, ...)
X, Y | Матрицы данных, в которых строки соответствуют наблюдениям или выборкам, а столбцы - элементам или размерам. X и Y может иметь разное количество строк, но они должны иметь одинаковое количество столбцов. Первый столбец является ссылочным измерением и должен содержать уникальные значения в порядке возрастания. Эталонное измерение может содержать выборочные индексы наблюдений или измеряемое значение, например время. |
BandValue | Одно из следующих действий:
|
WidthValue | Одно из следующих действий:
|
GapValue | Любое из следующих действий:
|
QuantileValue | Скаляр между 0 и 1 которое определяет значение квантиля, используемое для вычисления термина QMS, который используется 'Gap' свойство для расчета штрафов за разрыв. По умолчанию: 0.75. |
DistanceValue | Дескриптор функции, указанный с помощью
По умолчанию - евклидово расстояние между парами. Внимание Все столбцы в |
WeightsValue | Одно из следующих действий:
Это свойство управляет включением/исключением столбцов (элементов) или подчеркиванием столбцов (элементов) при вычислении оценки расстояния между наблюдениями, которые являются потенциальными совпадениями, то есть при использовании Совет Использование числового вектора строки для Примечание Значения веса не учитываются при использовании |
ShowConstraintsValue | Управление отображением пространства поиска, ограниченного указанным 'Band' и 'Width' входные параметры, тем самым давая указание на память, необходимую для запуска алгоритма с конкретными 'Band' и 'Width' параметры в наборах данных. Варианты: true или false (по умолчанию). |
ShowNetworkValue | Управляет отображением динамической сети программирования, оценками совпадений, штрафами за разрыв и путем выигрыша. Варианты: true или false (по умолчанию). |
ShowAlignmentValue | Управляет отображением первого и второго столбцов X и Y наборы данных в абсциссе и ординате соответственно двумерного графика. Варианты: true, false (по умолчанию) или целое число, указывающее столбец X и Y наборы данных для печати в качестве ординат. |
I | Вектор столбца, содержащий индексы строк (наблюдений) в X которые соответствуют строке (наблюдение) в Y. Отсутствующие индексы указывают, что строка (наблюдение) соответствует разрыву. |
J | Вектор столбца, содержащий индексы строк (наблюдений) в Y которые соответствуют строке (наблюдение) в X. Отсутствующие индексы указывают, что строка (наблюдение) соответствует разрыву. |
[ выравнивает наблюдения в двух матрицах данных, I, J] = samplealign(X, Y)X и Y, путем введения пробелов. X и Y - матрицы данных, в которых строки соответствуют наблюдениям или выборкам, а столбцы - признакам или размерам. X и Y может иметь разное количество строк, но должно иметь одинаковое количество столбцов. Первый столбец является ссылочным измерением и должен содержать уникальные значения в порядке возрастания. Эталонное измерение может содержать выборочные индексы наблюдений или измеряемое значение, например время. samplealign функция использует алгоритм динамического программирования для минимизации суммы положительных баллов, полученных из пар наблюдений, которые являются потенциальными совпадениями, и штрафов, полученных в результате вставки пробелов. Возвращаемые значения I и J - векторы столбцов, содержащие индексы, которые указывают совпадения для каждой строки (наблюдения) в X и Y соответственно.
Совет
Если возвращаемые значения не указаны, samplealign не запускает алгоритм динамического программирования. Управление samplealign без возвращаемых значений, но установка 'ShowConstraints', 'ShowNetwork', или 'ShowAlignment' свойство для trueпозволяет исследовать ограниченное пространство поиска, динамическую сеть программирования или выровненные наблюдения без возникновения потенциальных проблем с памятью.
[ требования I, J] = samplealign(X, Y, ...'PropertyName', PropertyValue, ...)samplealign с необязательными свойствами, использующими пары имя/значение свойства. Можно указать одно или несколько свойств в любом порядке. Каждый PropertyName должен быть заключен в одинарные кавычки и не учитывать регистр. Эти пары имя/значение свойства следующие:
[ задает максимально допустимое расстояние между наблюдениями (только вдоль справочного размера) в двух наборах данных, ограничивая, таким образом, число потенциальных совпадений между наблюдениями в двух наборах данных. Если I, J] = samplealign(X, Y, ...'Band', BandValue, ...)S - значение в ссылочном измерении для данного наблюдения (строки) в одном наборе данных, то это наблюдение сопоставляется только с наблюдениями в другом наборе данных, значения которого в ссылочном измерении находятся в пределах S ± BandValue. Затем в алгоритм для дальнейшей оценки передаются только эти потенциальные совпадения. BandValue может быть скаляром или функцией, указанной с помощью @(, где z)z - средняя точка между данным наблюдением в одном наборе данных и данным наблюдением в другом наборе данных. Дефолт BandValue является Inf.
Это ограничение уменьшает время и сложность памяти алгоритма от O (MN) в O (sqrt (MN)*K), где M и N - количество наблюдений в X и Y соответственно и K является небольшой константой, такой, что K<<M и K<<N. Приспособиться BandValue до максимального ожидаемого сдвига между опорными размерами в двух наборах данных, то есть между X(:, 1) иY(:,1).
[ ограничивает число потенциальных совпадений между наблюдениями в двух наборах данных; то есть каждое наблюдение в I, J] = samplealign(X, Y, ...'Width', WidthValue, ...)X оценивается до ближайшего U наблюдения в Yи каждое наблюдение в Y оценивается до ближайшего V наблюдения в X. Затем в алгоритм для дальнейшей оценки передаются только эти потенциальные совпадения. WidthValue является либо двухэлементным вектором, [U, V] или скаляр, который используется для обоих U и V. Близость измеряется только с использованием первого столбца (ссылочного измерения) в каждом наборе данных. По умолчанию: Inf если 'Band' указывается; в противном случае по умолчанию 10.
Это ограничение уменьшает время и сложность памяти алгоритма от O (MN) в O (sqrt (MN) * sqrt (UV)), где M и N - количество наблюдений в X и Y соответственно и U и V маленькие такие, что U<<M и V<<N.
Примечание
При указании обоих 'Band' и 'Width', только пары наблюдений, которые соответствуют обоим ограничениям, считаются потенциальными совпадениями и передаются алгоритму оценки.
Совет
Определить 'Width' когда у вас нет хорошей оценки для 'Band' собственность. Чтобы получить указание на память, необходимую для запуска алгоритма с конкретными 'Band' и 'Width' параметры в наборах данных, выполнение samplealign, но не указывайте возвращаемые значения и набор 'ShowConstraints' кому true.
[ определяет зависящие от позиции условия для назначения штрафов за разрыв. I, J] = samplealign(X, Y, ...'Gap', GapValue, ...)
GapValue является одним из следующих:
Массив ячеек, {G, H}, где G является скаляром или дескриптором функции, указанным с помощью @(, и X)H является скаляром или дескриптором функции, указанным с помощью @(. Функции Y)@( и X)@( должен вычислять штраф для каждого наблюдения (строки), когда оно сопоставляется с промежутком в другом наборе данных. Функции Y)@( и X)@( должен возвращать вектор столбца с тем же количеством строк, что и Y)X или Y, содержащий штраф за разрыв для каждого наблюдения (строки).
Один дескриптор функции, указанный с помощью @(, которая используется для обоих Z)G и H. Функция @( должен рассчитать штраф для каждого наблюдения (строки) в обоих Z)X и Y когда он сопоставляется с промежутком в другом наборе данных. Функция @( должен принимать в качестве аргументов Z)X и Y. Функция @( должен возвращать вектор столбца с тем же количеством строк, что и Z)X или Y, содержащий штраф за разрыв для каждого наблюдения (строки).
Скаляр, используемый для обоих G и H.
Вычисленное значение, GPX, является штрафом за разрыв для сопоставления наблюдений из первого набора данных X к пробелам, вставленным во второй набор данных Y, и является результатом двух терминов: GPX = G * QMS. Термин G принимает его значение как функцию от наблюдений в X. Аналогично, GPY - штраф за разрыв для совпадающих наблюдений из Y к пробелам, вставленным в X, и является результатом двух терминов: GPY = H * QMS. Термин H принимает его значение как функцию от наблюдений в Y. По умолчанию термин QMS представляет собой 0,75 квантиля оценки для пар наблюдений, которые являются потенциальными совпадениями (то есть пар, которые соответствуют 'Band' и 'Width' ограничения).
Если G и H являются положительными скалярами, то GPX и GPY не зависят от наблюдения, в которое вставляется зазор.
Дефолт GapValue является 1, то есть оба G и H являются 1, что указывает на то, что штраф по умолчанию для вставок промежутков в обеих последовательностях эквивалентен квантилю (устанавливается 'Quantile' свойство, по умолчанию = 0.75) оценки для пар наблюдений, которые являются потенциальными совпадениями.
Примечание
GapValue по умолчанию - относительно безопасное значение. Однако успех алгоритма зависит от точной настройки штрафов за разрыв, которая зависит от приложения. Когда брешь штрафных велика относительно счета правильных матчей, samplealign возвращает трассы с меньшим количеством промежутков, но с более неправильно выровненными областями. Когда штрафы за разрыв меньше, выравнивание выхода содержит более длинные области с пробелами и меньшим количеством согласованных наблюдений. Набор 'ShowNetwork' кому true сравнить штрафы за разрыв с оценкой сопоставленных наблюдений в различных областях выравнивания.
[ задает значение квантиля, используемое для вычисления термина I, J] = samplealign(X, Y, ...'Quantile', QuantileValue, ...)QMS, который используется 'Gap' свойство для расчета штрафов за разрыв. QuantileValue является скаляром между 0 и 1. По умолчанию: 0.75.
Совет
Набор QuantileValue в пустой массив ([]) сделать штрафы за разрыв независимыми от QMS, то есть GPX и GPY являются функциями только G и H входные параметры соответственно.
[ определяет функцию для вычисления расстояния между парами наблюдений, которые являются потенциальными совпадениями. I, J] = samplealign(X, Y, ...'Distance', DistanceValue, ...)DistanceValue является дескриптором функции, указанным с помощью @(. Функция R,S)@( должен принимать в качестве аргументов, R,S)R и S, матрицы, которые имеют одинаковое количество строк и столбцов, и чьи парные строки представляют все потенциальные совпадения наблюдений в X и Y соответственно. Функция @( должен возвращать вектор столбца положительных значений с тем же количеством элементов, что и строки в R,S)R и S. По умолчанию - евклидово расстояние между парами.
Внимание
Все столбцы в X и Y, включая ссылочный размер, учитываются при расчете расстояний. Если не требуется включать ссылочный размер в расчеты расстояния, используйте 'Weight' свойство для его исключения.
[ управляет включением/исключением столбцов (элементов) или подчеркиванием столбцов (элементов) при вычислении оценки расстояния между наблюдениями, которые являются потенциальными совпадениями, то есть при использовании I, J] = samplealign(X, Y, ...'Weights', WeightsValue, ...)'Distance' собственность. WeightsValue может быть логическим вектором строки, определяющим столбцы в X и Y. WeightsValue также может быть числовым вектором строки с тем же количеством элементов, что и столбцы в X и Y, которая определяет относительные веса столбцов (элементов). По умолчанию - логический вектор строки со всеми элементами, имеющими значение true.
Совет
Использование числового вектора строки для WeightsValue и установка некоторых значений в 0 позволяет упростить расчет расстояния, если наборы данных содержат множество столбцов (элементов).
Примечание
Значения веса не учитываются при вычислении ограниченного пространства выравнивания, то есть при использовании 'Band' или 'Width' свойства или при расчете штрафов за разрыв, то есть при использовании 'Gap' собственность.
[ управляет отображением пространства поиска, ограниченного входными параметрами I, J] = samplealign(X, Y, ...'ShowConstraints', ShowConstraintsValue, ...)'Band' и 'Width', давая указание на память, необходимую для выполнения алгоритма с конкретными 'Band' и 'Width' в наборах данных. Варианты: true или false (по умолчанию).
[ управляет отображением динамической сети программирования, оценкой совпадений, штрафами за разрыв и путем выигрыша. Варианты: I, J] = samplealign(X, Y, ...'ShowNetwork', ShowNetworkValue, ...)true или false (по умолчанию).
[ управляет отображением первого и второго столбцов I, J] = samplealign(X, Y, ...'ShowAlignment', ShowAlignmentValue, ...)X и Y наборы данных в абсциссе и ординате соответственно двумерного графика. Отображаются связи между всеми потенциальными совпадениями, удовлетворяющими ограничениям, и выделяются совпадения, принадлежащие выходной трассе. Варианты: true, false (по умолчанию) или целое число, указывающее столбец X и Y наборы данных для печати в качестве ординат.
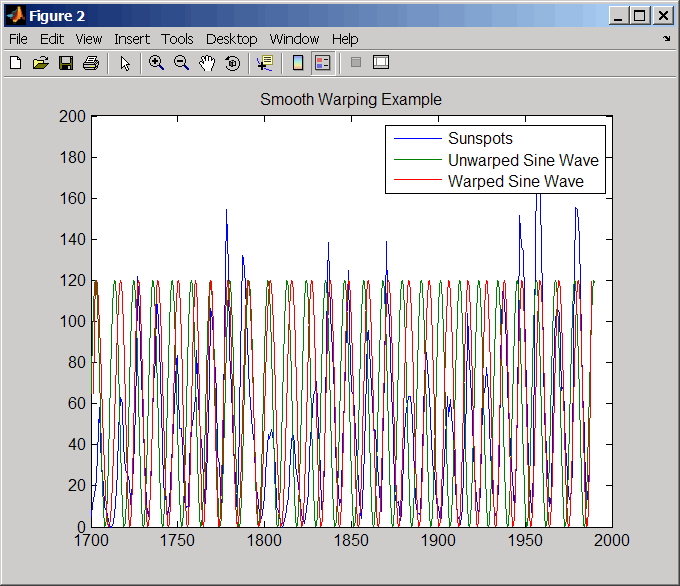
Груз sunspot.dat, файл данных, включенный в программное обеспечение MATLAB ®, который содержит переменнуюsunspot, которая представляет собой матрицу из двух столбцов, содержащую изменения активности солнечных пятен за последние 300 лет. Первый столбец представляет собой ссылочное измерение (годы), а второй столбец содержит значения активности солнечных пятен. Активность солнечных пятен циклична, достигает максимума примерно каждые 11 лет.
load sunspot.datСоздайте синусоидальную волну с известным периодом активности солнечных пятен.
years = (1700:1990)'; T = 11.038; f = @(y) 60 + 60 * sin(y*(2*pi/T));
Выровняйте наблюдения между синусоидальной волной и активностью солнечных пятен, введя промежутки.
[i,j] = samplealign([years f(years)],sunspot,'weights',... [0 1],'showalignment',true);
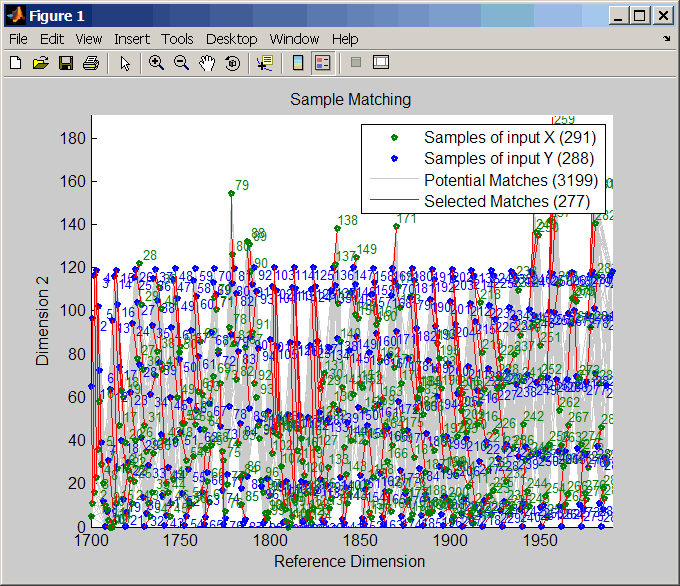
Оцените гладкую функцию для деформации синусоидальной волны.
[p,s,mu] = polyfit(years(i),years(j),15); wy = @(y) polyval(p,(y-mu(1))./mu(2));
Постройте график циклов солнечных пятен, неискривленной синусоидальной волны и деформированной синусоидальной волны.
years = (1700:1/12:1990)'; figure plot(sunspot(:,1),sunspot(:,2),years,f(years),wy(years),... f(years)) legend('Sunspots','Unwarped Sine Wave','Warped Sine Wave') title('Smooth Warping Example')
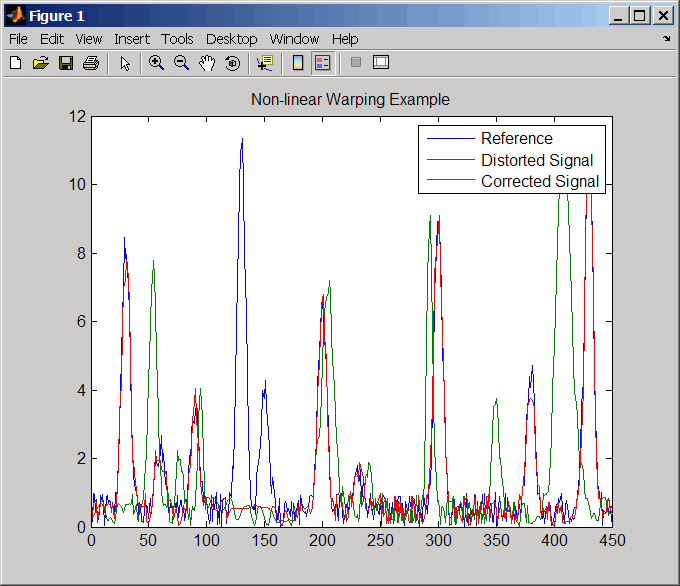
Создайте два сигнала с шумными гауссовыми пиками.
rng('default')
peakLoc = [30 60 90 130 150 200 230 300 380 430];
peakInt = [7 1 3 10 3 6 1 8 3 10];
time = 1:450;
comp = exp(-(bsxfun(@minus,time,peakLoc')./5).^2);
sig_1 = (peakInt + rand(1,10)) * comp + rand(1,450);
sig_2 = (peakInt + rand(1,10)) * comp + rand(1,450);Определите нелинейную функцию деформации.
wf = @(t) 1 + (t<=100).*0.01.*(t.^2) + (t>100).*...
(310+150*tanh(t./100-3));Деформируйте второй сигнал, чтобы исказить его.
sig_2 = interp1(time,sig_2,wf(time),'pchip');Выровняйте наблюдения между двумя сигналами, введя промежутки.
[i,j] = samplealign([time;sig_1]',[time;sig_2]',... 'weights',[0,1],'band',35,'quantile',.5);
Постройте график опорного сигнала, искаженного сигнала и искаженного (скорректированного) сигнала.
figure sig_3 = interp1(time,sig_2,interp1(i,j,time,'pchip'),'pchip'); plot(time,sig_1,time,sig_2,time,sig_3) legend('Reference','Distorted Signal','Corrected Signal') title('Non-linear Warping Example')
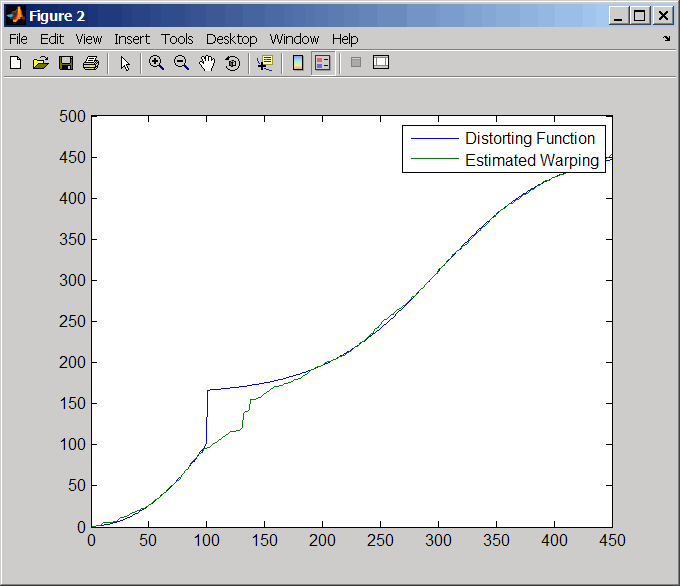
Постройте график реальных и расчетных деформирующих функций.
figure plot(time,wf(time),time,interp1(j,i,time,'pchip')) legend('Distorting Function','Estimated Warping')
Примечание
Примеры использования дескрипторов функций для Band, Gap, и Distance свойства см. в разделе Визуализация и предварительная обработка наборов данных масс-спектрометрии для профилирования метаболитов и белков/пептидов.
[1] Майерс, К. С. и Рабинер, Л. Р. (1981). Сравнительное исследование нескольких динамических алгоритмов искажения времени для распознавания связных слов. Технический журнал Bell System 60:7, 1389-1409.
[2] Сакое, Х. и Тиба, С. (1978). Оптимизация алгоритма динамического программирования для распознавания разговорных слов. IEEE Trans. Acoustics, Speech and Signal Processing ASSP-26 (1), 43-49 .
msalign | msheatmap | mspalign | msppresample | msresample
