Совет
Сведения о настройке параметров для сети глубокого обучения см. в разделах Настройка параметров и конволюционная нейронная сеть.
Одна из проблем, возникающих во время обучения нейронной сети, называется переоборудованием. Ошибка на обучающем аппарате приводится к очень маленькому значению, но когда в сеть представляются новые данные, ошибка является большой. Сеть запомнила примеры обучения, но не научилась обобщать на новые ситуации.
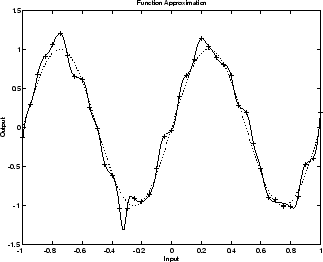
На следующем рисунке показана реакция нейронной сети 1-20-1, которая была обучена аппроксимировать шумную синусоидальную функцию. Основная синусоидальная функция показана пунктирной линией, шумные измерения даны символами +, а ответ нейронной сети - сплошной линией. Очевидно, что эта сеть перевыполнила данные и не будет хорошо обобщаться.
Одним из способов улучшения обобщения сети является использование сети, которая является достаточно большой, чтобы обеспечить адекватную подгонку. Чем больше сеть, тем сложнее ее функции. Если вы используете достаточно маленькую сеть, она не будет иметь достаточно мощности, чтобы переполнить данные. Выполните
пример проектирования нейронной сети nnd11gn [HDB96], чтобы выяснить, как уменьшение размера сети может предотвратить переоборудование.
К сожалению, трудно заранее знать, какой большой должна быть сеть для конкретного приложения. Есть два других метода улучшения обобщения, которые реализованы в программном обеспечении Deep Learning Toolbox™: регуляризация и ранняя остановка. В следующих разделах описываются эти два метода и процедуры их реализации.
Отметим, что если количество параметров в сети значительно меньше общего количества точек в обучающем наборе, то шансов на переоборудование мало или вообще нет. Если вы можете легко собрать больше данных и увеличить размер обучающего набора, то нет необходимости беспокоиться о следующих методах, чтобы предотвратить переоборудование. Остальная часть этого раздела относится только к тем ситуациям, в которых требуется максимально использовать ограниченный объем данных.
Как правило, каждая тренировка обратного распространения начинается с различных начальных весов и отклонений, а также различных разделов данных в обучающих, валидационных и тестовых наборах. Эти различные условия могут привести к очень разным решениям одной и той же проблемы.
Рекомендуется обучить несколько сетей, чтобы обеспечить наличие сети с хорошим обобщением.
Здесь загружается набор данных, который делится на две части: 90% для проектирования сетей и 10% для тестирования всех.
[x, t] = bodyfat_dataset; Q = size(x, 2); Q1 = floor(Q * 0.90); Q2 = Q - Q1; ind = randperm(Q); ind1 = ind(1:Q1); ind2 = ind(Q1 + (1:Q2)); x1 = x(:, ind1); t1 = t(:, ind1); x2 = x(:, ind2); t2 = t(:, ind2);
Затем архитектура сети выбирается и обучается десять раз в первой части набора данных, со средней квадратной ошибкой каждой сети во второй части набора данных.
net = feedforwardnet(10);
numNN = 10;
NN = cell(1, numNN);
perfs = zeros(1, numNN);
for i = 1:numNN
fprintf('Training %d/%d\n', i, numNN);
NN{i} = train(net, x1, t1);
y2 = NN{i}(x2);
perfs(i) = mse(net, t2, y2);
endКаждая сеть будет обучена, начиная с различных начальных весов и отклонений, и с различным разделением первого набора данных на обучение, проверку и наборы тестов. Следует отметить, что тестовые наборы являются хорошей мерой обобщения для каждой соответствующей сети, но не для всех сетей, поскольку данные, которые являются тестовым набором для одной сети, вероятно, будут использоваться для обучения или проверки другими нейронными сетями. Поэтому исходный набор данных был разделен на две части для обеспечения сохранения полностью независимого тестового набора.
Нейронная сеть с самой низкой производительностью - та, которая лучше всего обобщена во второй части набора данных.
Другим простым способом улучшить обобщение, особенно когда оно вызвано шумными данными или небольшим набором данных, является обучение нескольких нейронных сетей и усреднение их выходных данных.
Например, здесь 10 нейронных сетей обучаются небольшой проблеме и их среднеквадратичным ошибкам по сравнению со средними квадратичными ошибками их среднего значения.
Сначала загружается набор данных, который разделяется на проектный и тестовый набор.
[x, t] = bodyfat_dataset; Q = size(x, 2); Q1 = floor(Q * 0.90); Q2 = Q - Q1; ind = randperm(Q); ind1 = ind(1:Q1); ind2 = ind(Q1 + (1:Q2)); x1 = x(:, ind1); t1 = t(:, ind1); x2 = x(:, ind2); t2 = t(:, ind2);
Затем обучают десять нейронных сетей.
net = feedforwardnet(10);
numNN = 10;
nets = cell(1, numNN);
for i = 1:numNN
fprintf('Training %d/%d\n', i, numNN)
nets{i} = train(net, x1, t1);
endЗатем каждая сеть тестируется на втором наборе данных с вычисленными как индивидуальными рабочими характеристиками, так и производительностью для среднего выходного сигнала.
perfs = zeros(1, numNN);
y2Total = 0;
for i = 1:numNN
neti = nets{i};
y2 = neti(x2);
perfs(i) = mse(neti, t2, y2);
y2Total = y2Total + y2;
end
perfs
y2AverageOutput = y2Total / numNN;
perfAveragedOutputs = mse(nets{1}, t2, y2AverageOutput) Средняя квадратичная погрешность для среднего выхода, вероятно, будет ниже, чем большинство отдельных выступлений, возможно, не все. Это, вероятно, будет лучше обобщать дополнительные новые данные.
Для некоторых очень сложных проблем можно обучить сотню сетей, а среднее значение их выхода принять за любой вход. Это особенно полезно для небольшого, шумного набора данных в сочетании с функцией обучения байесовской регуляризации trainbr, описано ниже.
Метод по умолчанию для улучшения обобщения называется ранней остановкой. Этот метод автоматически предоставляется для всех контролируемых функций создания сети, включая функции создания сети обратного распространения, такие как feedforwardnet.
В этом методе доступные данные делятся на три подмножества. Первым подмножеством является обучающий набор, который используется для вычисления градиента и обновления весов и смещений сети. Вторым подмножеством является набор проверки. Ошибка в наборе проверки отслеживается в процессе обучения. Ошибка проверки подлинности обычно уменьшается на начальном этапе обучения, как и ошибка набора обучения. Однако когда сеть начинает перегружать данные, ошибка в наборе проверки обычно начинает увеличиваться. При увеличении ошибки проверки для указанного числа итераций (net.trainParam.max_fail), обучение прекращается, и возвращаются веса и смещения на минимуме ошибки проверки.
Ошибка тестового набора не используется во время обучения, но используется для сравнения различных моделей. Также полезно построить график ошибки тестового набора во время процесса обучения. Если ошибка в тестовом наборе достигает минимума при значимо ином номере итерации, чем ошибка в проверочном наборе, это может свидетельствовать о плохом разделении набора данных.
Для разделения данных на обучающие, валидационные и тестовые наборы предусмотрены четыре функции. Они являются dividerand (по умолчанию), divideblock, divideint, и divideind. С помощью этого свойства можно получить доступ к функции разделения сети или изменить ее.
net.divideFcn
Каждая из этих функций принимает параметры, которые настраивают ее поведение. Эти значения сохраняются и могут быть изменены с помощью следующего свойства сети:
net.divideParam
Создайте простую проблему тестирования. Для полного набора данных генерируйте шумную синусоидальную волну с 201 входной точкой в диапазоне от − 1 до 1 на шагах 0,01:
p = [-1:0.01:1]; t = sin(2*pi*p)+0.1*randn(size(p));
Разделите данные по индексам таким образом, чтобы последовательные выборки были последовательно назначены обучающему набору, проверочному набору и тестовому набору:
trainInd = 1:3:201 valInd = 2:3:201; testInd = 3:3:201; [trainP,valP,testP] = divideind(p,trainInd,valInd,testInd); [trainT,valT,testT] = divideind(t,trainInd,valInd,testInd);
Входные данные можно разделить случайным образом, чтобы 60% проб были назначены обучающему набору, 20% - валидационному набору и 20% - тестовому набору, как показано ниже:
[trainP,valP,testP,trainInd,valInd,testInd] = dividerand(p);
Эта функция не только делит входные данные, но и возвращает индексы, чтобы можно было соответствующим образом разделить целевые данные, используя divideind:
[trainT,valT,testT] = divideind(t,trainInd,valInd,testInd);
Можно также случайным образом разделить входные данные так, чтобы первые 60% образцов были назначены обучающему набору, следующие 20% - валидационному набору и последние 20% - тестовому набору, как показано ниже:
[trainP,valP,testP,trainInd,valInd,testInd] = divideblock(p);
Соответствующим образом разделите целевые данные с помощью divideind:
[trainT,valT,testT] = divideind(t,trainInd,valInd,testInd);
Другим способом разделения входных данных является циклический цикл выборок между обучающим набором, проверочным набором и тестовым набором в соответствии с процентами. 60% проб можно перемезить в обучающий набор, 20% в валидационный набор и 20% в тестовый набор следующим образом:
[trainP,valP,testP,trainInd,valInd,testInd] = divideint(p);
Соответствующим образом разделите целевые данные с помощью divideind.
[trainT,valT,testT] = divideind(t,trainInd,valInd,testInd);
Другой способ улучшения обобщения называется регуляризацией. Это включает в себя изменение функции производительности, которая обычно выбирается как сумма квадратов сетевых ошибок на обучающем аппарате. В следующем разделе объясняется, как можно изменить функцию производительности, а в следующем разделе описывается процедура, которая автоматически устанавливает оптимальную функцию производительности для достижения наилучшего обобщения.
Типичная функция производительности, используемая для обучения нейронных сетей прямой связи, представляет собой среднюю сумму квадратов ошибок сети.
αi) 2
Можно улучшить обобщение, если модифицировать функцию производительности, добавив член, который состоит из среднего значения суммы квадратов весов сети и смещений − γ) * mse, где γ - коэффициент производительности, и
Использование этой функции производительности приводит к тому, что сеть имеет меньшие веса и смещения, и это заставляет отклик сети быть более плавным и менее вероятным.
Следующий код повторно инициализирует предыдущую сеть и переоснащает ее с помощью алгоритма BFGS с регуляризованной функцией производительности. Здесь коэффициент производительности устанавливается равным 0,5, что дает равный вес среднеквадратичным ошибкам и среднеквадратичным весам.
[x,t] = simplefit_dataset; net = feedforwardnet(10,'trainbfg'); net.divideFcn = ''; net.trainParam.epochs = 300; net.trainParam.goal = 1e-5; net.performParam.regularization = 0.5; net = train(net,x,t);
Проблема с регуляризацией заключается в том, что трудно определить оптимальное значение параметра коэффициента эффективности. Если сделать этот параметр слишком большим, может возникнуть переоборудование. Если соотношение слишком мало, сеть не соответствует соответствующим данным обучения. В следующем разделе описывается процедура, которая автоматически устанавливает параметры регуляризации.
Желательно определить оптимальные параметры регуляризации автоматизированным способом. Одним из подходов к этому процессу является байесовская структура Дэвида Маккея [MacK92]. В этой структуре предполагается, что веса и смещения сети являются случайными переменными с заданными распределениями. Параметры регуляризации связаны с неизвестными дисперсиями, связанными с этими распределениями. Затем эти параметры можно оценить с помощью статистических методов.
Подробное обсуждение байесовской регуляризации выходит за рамки данного руководства пользователя. Подробное обсуждение использования байесовской регуляризации в сочетании с обучением Левенберга-Марквардта можно найти в [FoHa97].
В функции реализована байесовская регуляризация trainbr. Следующий код показывает, как можно обучить сеть 1-20-1 с помощью этой функции для аппроксимации шумной синусоидальной волны, показанной на рисунке «Улучшение неглубокого обобщения нейронной сети и избегание переоснащения». (Разделение данных отменяется настройкой net.divideFcn чтобы последствия trainbr изолированы от ранней остановки.)
x = -1:0.05:1; t = sin(2*pi*x) + 0.1*randn(size(x)); net = feedforwardnet(20,'trainbr'); net = train(net,x,t);
Одной из особенностей этого алгоритма является то, что он обеспечивает измерение количества сетевых параметров (весов и смещений), эффективно используемых сетью. В этом случае окончательная обученная сеть использует приблизительно 12 параметров (указано #Par в распечатке) из 61 общих весов и отклонений в сети 1-20-1. Это эффективное количество параметров должно оставаться примерно одинаковым, независимо от того, насколько велико количество параметров в сети. (Предполагается, что сеть обучена достаточному количеству итераций для обеспечения сходимости.)
trainbr алгоритм обычно работает лучше всего, когда сетевые входы и цели масштабируются так, что они попадают приблизительно в диапазон [− 1,1]. Так обстоит дело с проблемой тестирования. Если входные данные и цели не попадают в этот диапазон, можно использовать функциюmapminmax или mapstd для выполнения масштабирования, как описано в разделе Выбор функций обработки ввода-вывода нейронной сети. Сети, созданные с помощью feedforwardnet включать mapminmax в качестве функции обработки ввода и вывода по умолчанию.
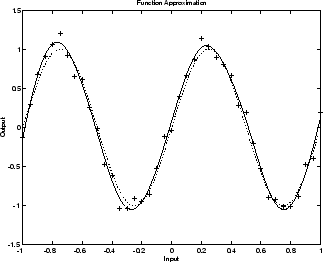
На следующем рисунке показана реакция обученной сети. В отличие от предыдущего рисунка, на котором сеть 1-20-1 переопределяет данные, здесь вы видите, что сетевой ответ очень близок к базовой синусоидальной функции (пунктирной линии), и, следовательно, сеть хорошо обобщится на новые входы. Вы могли бы попробовать еще большую сеть, но сетевой ответ никогда не перевыполнил бы данные. Это устраняет догадки, необходимые для определения оптимального размера сети.
При использовании trainbr, важно позволить алгоритму работать до тех пор, пока эффективное количество параметров не сходится. Обучение может прекратиться сообщением «Maximum MU accounted». Это типично и является хорошим показателем того, что алгоритм действительно сошелся. Можно также сказать, что алгоритм сходился, если суммарная квадратичная ошибка (SSE) и суммарные квадратичные веса (SSW) относительно постоянны в нескольких итерациях. В этом случае можно нажать кнопку Остановить обучение в окне обучения.
Ранняя остановка и регуляризация могут обеспечить обобщение сети при правильном их применении.
Для ранней остановки необходимо быть осторожным, чтобы не использовать алгоритм, который сходится слишком быстро. Если вы используете быстрый алгоритм (например, trainlm), установите параметры обучения так, чтобы сходимость была относительно медленной. Например, установить mu к относительно большому значению, такому как 1, и установить mu_dec и mu_inc до значений, близких к 1, таких как 0,8 и 1,5 соответственно. Функции обучения trainscg и trainbr обычно хорошо работают с ранней остановкой.
При ранней остановке также важен выбор набора проверки. Набор проверки должен быть репрезентативным для всех точек в наборе обучения.
При использовании байесовской регуляризации важно обучать сеть, пока она не достигнет сходимости. Погрешность суммы в квадрате, веса суммы в квадрате и эффективное число параметров должны достигать постоянных значений, когда сеть сходится.
При ранней остановке и регуляризации рекомендуется обучать сеть, начиная с нескольких различных исходных условий. При определенных обстоятельствах любой метод может потерпеть неудачу. Проверяя несколько различных начальных условий, можно проверить надежную производительность сети.
Когда набор данных невелик и вы обучаете сети аппроксимации функций, байесовская регуляризация обеспечивает лучшую производительность обобщения, чем ранняя остановка. Это происходит потому, что байесовская регуляризация не требует, чтобы набор данных проверки был отделен от набора данных обучения; он использует все данные.
Чтобы дать некоторое представление о производительности алгоритмов, как ранняя остановка, так и байесовская регуляризация были протестированы на нескольких наборах эталонных данных, которые перечислены в следующей таблице.
Заголовок набора данных | Количество баллов | Сеть | Описание |
|---|---|---|---|
МЯЧ | 67 | 2-10-1 | Калибровка с двумя датчиками для измерения положения шара |
SINE (5% N) | 41 | 1-15-1 | Одноцикловая синусоидальная волна с гауссовым шумом на уровне 5% |
SINE (2% N) | 41 | 1-15-1 | Одноцикловая синусоидальная волна с гауссовым шумом на уровне 2% |
ДВИГАТЕЛЬ (ВСЕ) | 1199 | 2-30-2 | Датчик двигателя - полный набор данных |
ДВИГАТЕЛЬ (1/4) | 300 | 2-30-2 | Датчик двигателя - 1/4 комплекта данных |
ХОЛЕСТ (ВСЕ) | 264 | 5-15-3 | Измерение холестерина - полный набор данных |
ХОЛЕСТ (1/2) | 132 | 5-15-3 | Измерение холестерина - набор данных 1/2 |
Эти наборы данных имеют различные размеры и имеют различное количество входных данных и целевых показателей. С двумя наборами данных сети были обучены один раз с использованием всех данных, а затем переобучены с использованием только части данных. Это иллюстрирует, как преимущество байесовской регуляризации становится более заметным, когда наборы данных меньше. Все наборы данных получены из физических систем, за исключением наборов данных SINE. Эти два были искусственно созданы путем добавления различных уровней шума к одному циклу синусоидальной волны. Производительность алгоритмов на этих двух наборах данных иллюстрирует эффект шума.
В следующей таблице приведены результаты ранней остановки (ES) и байесовской регуляризации (BR) для семи тестовых наборов. ( trainscg алгоритм использовался для тестов ранней остановки. Другие алгоритмы обеспечивают аналогичную производительность.)
Среднеквадратичная ошибка набора тестов
| Метод | Мяч | Двигатель (все) | Двигатель (1/4) | Холес (все) | Холес (1/2) | Синус (5% N) | Синус (2% N) |
|---|---|---|---|---|---|---|---|
| ES | 1.2e-1 | 1.3e-2 | 1.9e-2 | 1.2e-1 | 1.4e-1 | 1.7e-1 | 1.3e-1 |
| BR | 1.3e-3 | 2.6e-3 | 4.7e-3 | 1.2e-1 | 9.3e-2 | 3.0e-2 | 6.3e-3 |
| ES/BR | 92 | 5 | 4 | 1 | 1.5 | 5.7 | 21 |
Вы можете видеть, что байесовская регуляризация работает лучше, чем ранняя остановка в большинстве случаев. Улучшение производительности наиболее заметно, когда набор данных мал или если в наборе данных мало шума. Набор данных BALL, например, был получен от датчиков, которые имели очень мало шума.
Хотя обобщающая характеристика байесовской регуляризации часто лучше ранней остановки, это не всегда так. Кроме того, форма байесовской регуляризации, реализованная в инструментарии, не так хорошо выполняет задачи распознавания образов, как проблемы аппроксимации функций. Это происходит потому, что приближение к гессенскому, которое используется в алгоритме Левенберга-Марквардта, не так точно, когда сетевой выход насыщен, как в случае проблем распознавания образов. Другим недостатком байесовского метода регуляризации является то, что для его сходимости обычно требуется больше времени, чем для ранней остановки.
Производительность обученной сети может быть в некоторой степени измерена ошибками в обучающих, валидационных и тестовых наборах, но часто полезно исследовать ответ сети более подробно. Одним из вариантов является выполнение регрессионного анализа между сетевым ответом и соответствующими целями. Установленный порядок regression предназначен для выполнения этого анализа.
Следующие команды иллюстрируют выполнение регрессионного анализа в обучаемой сети.
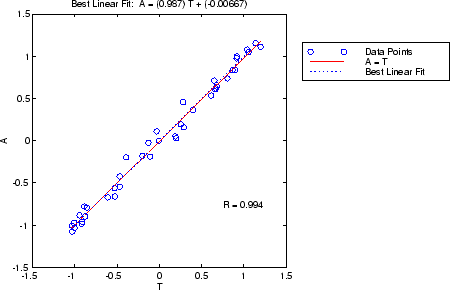
x = [-1:.05:1]; t = sin(2*pi*x)+0.1*randn(size(x)); net = feedforwardnet(10); net = train(net,x,t); y = net(x); [r,m,b] = regression(t,y)
r =
0.9935
m =
0.9874
b =
-0.0067
Сетевой выход и соответствующие целевые объекты передаются в regression. Он возвращает три параметра. Первые два, m и b, соответствуют наклону и y-перехвату наилучшей линейной регрессии, относящейся к целям к выходам сети. Если бы была идеальная посадка (выходы точно равны целям), наклон был бы равен 1, а y-перехват был бы равен 0. В этом примере видно, что цифры очень близки. Третья переменная, возвращенная regression - коэффициент корреляции (R-значение) между выходами и целями. Это показатель того, насколько хорошо вариация выходных данных объясняется целевыми показателями. Если это число равно 1, то существует идеальная корреляция между целями и выходами. В примере число очень близко к 1, что говорит о хорошей посадке.
Следующий рисунок иллюстрирует графический вывод, предоставляемый regression. Сетевые выходы строятся в зависимости от целей в виде разомкнутых окружностей. Наилучшая линейная посадка обозначается пунктирной линией. Идеальная посадка (выход равен целям) обозначается сплошной линией. В этом примере трудно отличить наилучшую линейную линию посадки от идеальной линии посадки, потому что посадка такая хорошая.