Розенблат [Rose61] создал множество вариаций перцептрона. Одной из простейших была однослойная сеть, веса и смещения которой можно было обучить созданию правильного целевого вектора при представлении с соответствующим входным вектором. Используемая методика обучения называется правилом перцептронного обучения. Перцептрон вызвал большой интерес благодаря своей способности обобщать из своих обучающих векторов и учиться на первоначально случайно распределенных соединениях. Перцептроны особенно подходят для простых проблем в классификации шаблонов. Они являются быстрыми и надежными сетями для решения проблем, которые они могут решить. Кроме того, понимание операций перцептрона обеспечивает хорошую основу для понимания более сложных сетей.
Обсуждение перцептронов в этом разделе неизбежно является кратким. Более подробное обсуждение см. в главе 4 «Правило перцептронного обучения» [HDB1996], в которой обсуждается использование нескольких уровней перцептронов для решения более сложных проблем, выходящих за рамки возможностей одного уровня.
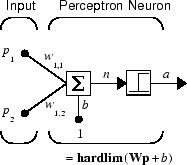
Нейрон перцептрона, который использует функцию переноса жесткого предела hardlim, показано ниже.
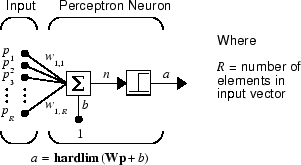
Каждый внешний вход взвешивается с соответствующим весом w1j, и сумма взвешенных входов посылается в передаточную функцию жесткого предела, которая также имеет вход 1, передаваемый ей через смещение. Ниже показана функция переноса жесткого предела, которая возвращает 0 или 1.
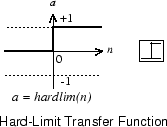
Нейрон перцептрона производит 1, если суммарный вход в передаточную функцию равен или больше 0; в противном случае он создает 0.
Функция переноса жесткого предела даёт перцептрону возможность классифицировать входные векторы путём деления входного пространства на две области. В частности, выходы будут равны 0, если чистый вход n меньше 0, или 1, если чистый вход n равен 0 или больше. На следующем рисунке показано входное пространство двухвходового жесткого предельного нейрона с весами w1,1 = − 1, w1,2 = 1 и смещением b = 1.
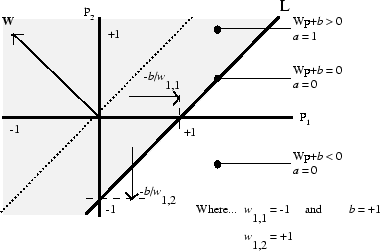
Две классификационные области образованы линией L границы принятия решения при
Wp + b = 0. Эта линия перпендикулярна весовой матрице W и смещена в соответствии со смещением b. Входные векторы выше и слева от линии L будут приводить к результирующему входу больше 0 и, следовательно, заставлять нейрон жесткого предела выводить 1. Входные векторы ниже и справа от линии L заставляют нейрон выводить 0. Можно выбрать значения веса и смещения для ориентации и перемещения разделительной линии, чтобы классифицировать входное пространство по желанию.
Нейроны с жестким пределом без смещения всегда будут иметь классификационную линию, проходящую через начало координат. Добавление смещения позволяет нейрону решать задачи, когда два набора входных векторов не расположены на разных сторонах начала координат. Смещение позволяет сдвинуть границу принятия решения от начала координат, как показано на графике выше.
Возможно, потребуется запустить программу-пример nnd4db. С его помощью можно перемещать границу принятия решения, выбирать новые входные данные для классификации и видеть, как повторное применение правила обучения дает сеть, которая правильно классифицирует входные векторы.
Перцептронная сеть состоит из одного уровня S нейроны перцептрона, соединенные с R входами через набор весов wi, j, как показано ниже в двух формах. Как и ранее, сетевые индексы i и j указывают, что wi, j - это сила соединения от j-го входа к i-му нейрону.
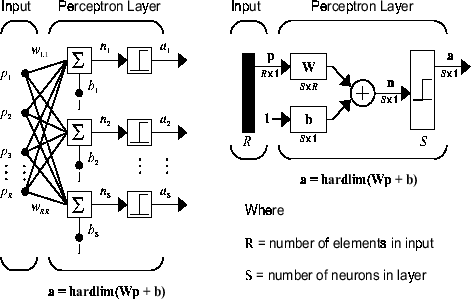
Описанное в ближайшее время правило перцептронного обучения способно обучать только один слой. Таким образом, здесь рассматриваются только одноуровневые сети. Это ограничение накладывает ограничения на вычисления, которые может выполнять перцептрон. Типы задач, на решение которых способны перцептроны, обсуждаются в «Ограничениях и предостережениях».
Перцептрон можно создать следующим образом:
net = perceptron; net = configure(net,P,T);
где входные аргументы следующие:
P представляет собой матрицу R-на-Q из Q входных векторов R элементов каждый.
T представляет собой матрицу S-на-Q из Q целевых векторов S элементов каждый.
Обычно, hardlim функция используется в перцептронах, поэтому она является функцией по умолчанию.
Следующие команды создают перцептронную сеть с одним одноэлементным входным вектором со значениями 0 и 2, и один нейрон с выходами, которые могут быть либо 0, либо 1:
P = [0 2]; T = [0 1]; net = perceptron; net = configure(net,P,T);
Создать сеть можно, выполнив следующую команду:
inputweights = net.inputweights{1,1}
который дает
inputweights =
delays: 0
initFcn: 'initzero'
learn: true
learnFcn: 'learnp'
learnParam: (none)
size: [1 1]
weightFcn: 'dotprod'
weightParam: (none)
userdata: (your custom info)
Функция обучения по умолчанию: learnp, который обсуждается в Perceptron Learning Rule (learnp). Чистый вход в hardlim передаточная функция dotprod, который генерирует произведение входного вектора и весовой матрицы и добавляет смещение для вычисления чистого входного сигнала.
Функция инициализации по умолчанию initzero используется для установки начальных значений весов в нуль.
Аналогично,
biases = net.biases{1}
дает
biases =
initFcn: 'initzero'
learn: 1
learnFcn: 'learnp'
learnParam: []
size: 1
userdata: [1x1 struct]
Можно видеть, что инициализация по умолчанию для смещения также равна 0.
Перцептроны обучаются на примерах желаемого поведения. Желаемое поведение можно суммировать по набору входных, выходных пар
p1t1,p2t1,...,pQtQ
где p - вход в сеть, а t - соответствующий правильный (целевой) выход. Цель состоит в том, чтобы уменьшить ошибку e, которая представляет собой разницу t − a между ответом нейрона a и вектором-мишенью t. Правило обучения перцептрону learnp вычисляет требуемые изменения веса и смещения перцептрона, учитывая входной вектор p и связанную с ним ошибку. Целевой вектор t должен содержать значения 0 или 1, поскольку перцептроны (с hardlim передаточные функции) могут выводить только эти значения.
Каждый раз learnp выполняется, перцептрон имеет больше шансов на получение правильных выходных данных. Доказано, что правило перцептрона сходится в решении в конечном числе итераций, если решение существует.
Если смещение не используется, learnp работает над поиском решения путем изменения только вектора веса w для указания на входные векторы, которые должны быть классифицированы как 1, и от векторов, которые должны быть классифицированы как 0. Это приводит к границе принятия решения, которая перпендикулярна w и надлежащим образом классифицирует входные векторы.
Существует три условия, которые могут возникнуть для одного нейрона, как только будет представлен входной вектор p и вычислен ответ сети a:
СЛУЧАЙ 1. Если входной вектор представлен и выход нейрона верен (a = t и e = t - a = 0), то весовой вектор w не изменяется.
СЛУЧАЙ 2. Если выход нейрона равен 0 и должен был быть равен 1 (a = 0 и t = 1, и e = t - a = 1), входной вектор p добавляется к весовому вектору w. Это делает весовой вектор более близким к входному вектору, увеличивая вероятность того, что входной вектор будет классифицирован как 1 в будущем.
СЛУЧАЙ 3. Если выход нейрона равен 1 и должен был быть равен 0 (a = 1 и t = 0, и e = t - a = -1), входной вектор p вычитается из весового вектора w. Это делает весовой вектор более удаленным от входного вектора, увеличивая вероятность того, что входной вектор будет классифицирован как 0 в будущем.
Правило перцептронного обучения может быть записано более лаконично в терминах ошибки e = t-a и изменения, которое должно быть внесено в весовой вектор Δw:
СЛУЧАЙ 1. Если e = 0, сделайте изменение Δw равным 0.
СЛУЧАЙ 2. Если e = 1, то сделайте изменение Δw равным pT.
СЛУЧАЙ 3. Если e = -1, сделайте изменение Δw равным -pT.
Все три варианта могут быть записаны с одним выражением:
pT = epT
Вы можете получить выражение для изменений смещения нейрона, заметив, что смещение является просто весом, который всегда имеет вход 1:
(1) = e
Для случая слоя нейронов у вас есть
= e (p) T
и
a) = e
Правило обучения перцептрону можно резюмировать следующим образом:
epT
и
+ e
где e = t - a.
Теперь попробуйте простой пример. Начните с одного нейрона, имеющего входной вектор с двумя элементами.
net = perceptron; net = configure(net,[0;0],0);
Для упрощения вопросов установите смещение, равное 0, а веса - 1 и -0,8:
net.b{1} = [0];
w = [1 -0.8];
net.IW{1,1} = w;
Входная целевая пара задается
p = [1; 2]; t = [1];
Вы можете вычислить выходные данные и ошибку с помощью
a = net(p)
a =
0
e = t-a
e =
1
и использовать функцию learnp чтобы найти изменение весов.
dw = learnp(w,p,[],[],[],[],e,[],[],[],[],[])
dw =
1 2
Новые веса, таким образом, получаются как
w = w + dw
w =
2.0000 1.2000
Процесс поиска новых весов (и смещений) может повторяться до тех пор, пока не будет ошибок. Напомним, что правило перцептронного обучения гарантированно сходится в конечном количестве шагов для всех задач, которые могут быть решены перцептроном. К ним относятся все проблемы классификации, которые являются линейно разделяемыми. Объекты, подлежащие классификации в таких случаях, могут быть разделены одной строкой.
Вы можете попробовать пример nnd4pr. Он позволяет выбирать новые входные векторы и применять правило обучения для их классификации.
Если sim и learnp используются неоднократно для представления входных данных перцептрону, и для изменения веса перцептрона и смещения в соответствии с ошибкой, перцептрон в конечном итоге найдет значения веса и смещения, которые решат проблему, учитывая, что перцептрон может решить ее. Каждое прохождение по всем входным и целевым векторам обучения называется проходом.
Функция train осуществляет такой цикл вычисления. В каждой передают функцию train осуществляют переход через заданную последовательность входов, вычисляя выход, ошибку и сетевую корректировку для каждого входного вектора в последовательности, в которой представлены входы.
Обратите внимание, что train не гарантирует, что результирующая сеть выполнит свою работу. Необходимо проверить новые значения W и b путем вычисления сетевого выхода для каждого входного вектора, чтобы проверить, все ли цели достигнуты. Если сеть не работает успешно, ее можно обучить по телефону train снова с новыми весами и отклонениями для дополнительных тренировочных проходов, или вы можете проанализировать проблему, чтобы увидеть, является ли она подходящей проблемой для перцептрона. Проблемы, которые не могут быть решены сетью перцептронов, обсуждаются в разделе Ограничения и предостережения.
Чтобы проиллюстрировать процедуру обучения, прорабатывайте простую проблему. Рассмотрим перцептрон с одним нейроном с одним векторным входом, имеющим два элемента:
Эта сеть и проблема, которую вы собираетесь рассмотреть, достаточно просты, что вы можете следовать через то, что делается с ручными расчетами, если вы хотите. Ниже описана проблема, обнаруженная в [HDB1996].
Предположим, что у вас есть следующая задача классификации и вы хотите решить ее с помощью одного вектора ввода, двухэлементной сети перцептронов.
Используйте начальные веса и смещение. Обозначьте переменные на каждом этапе этого вычисления, используя число в скобках после переменной. Таким образом, выше начальными значениями являются W (0) и b (0).
(0) = 0
Начните с вычисления выходного сигнала перцептрона a для первого входного вектора p1, используя начальные веса и смещение.
) = hardlim (0) = 1
Выходной сигнал a не равен целевому значению t1, поэтому используйте правило perceptron для поиска инкрементных изменений весов и смещений на основе ошибки.
[− 2 − 2] Δb = e = (− 1) = − 1
Вычислить новые веса и смещение можно с помощью правил обновления перцептрона.
bold + e = 0 + (− 1) = − 1 = b (1)
Теперь представим следующий входной вектор, p2. Выходные данные рассчитываются ниже.
] − 1) = hardlim (1) = 1
В этом случае целевой объект равен 1, поэтому ошибка равна нулю. Таким образом, изменений в весах или смещении нет, поэтому W (2) = W (1) = [− 2 − 2] и b (2) = b (1) = − 1.
Вы можете продолжить таким образом, представив p3 далее, рассчитав вывод и ошибку, и внести изменения в веса и смещение и т.д. Пройдя один проход через все четыре входа, получаем значения W (4) = [− 3 − 1] и b (4) = 0. Чтобы определить, получено ли удовлетворительное решение, проведите один проход через все входные векторы, чтобы увидеть, дают ли они все желаемые целевые значения. Это не верно для четвертого входа, но алгоритм сходится на шестом представлении входа. Окончательные значения:
W (6) = [− 2 − 3] и b (6) = 1.
На этом расчет руки завершается. Теперь, как вы можете сделать это с помощью train функция?
Следующий код определяет перцептрон.
net = perceptron;
Рассмотрим применение одного входного сигнала
p = [2; 2];
с целью
t = [0];
Набор epochs на 1, так что train проходит через входные векторы (только один здесь) всего один раз.
net.trainParam.epochs = 1; net = train(net,p,t);
Новые веса и смещение
w = net.iw{1,1}, b = net.b{1}
w =
-2 -2
b =
-1
Таким образом, начальные веса и смещение равны 0, и после тренировки только на первом векторе они имеют значения [− 2 − 2] и − 1, точно так же, как вы делаете расчёт.
Теперь примените второй входной вектор p2. Выход равен 1, так как он будет до тех пор, пока не будут изменены веса и смещение, но теперь цель равна 1, ошибка будет равна 0, а изменение будет равно нулю. Таким образом можно начать с предыдущего результата и применять новый входной вектор время от времени. Но вы можете выполнять эту работу автоматически с помощью train.
Обратиться train для одной эпохи один проход через последовательность всех четырёх входных векторов. Начните с определения сети.
net = perceptron; net.trainParam.epochs = 1;
Входные векторы и цели:
p = [[2;2] [1;-2] [-2;2] [-1;1]] t = [0 1 0 1]
Теперь тренируйте сеть с
net = train(net,p,t);
Новые веса и смещение
w = net.iw{1,1}, b = net.b{1}
w =
-3 -1
b =
0
Это тот же результат, который вы получили ранее от руки.
Наконец, смоделировать обученную сеть для каждого из входов.
a = net(p)
a =
0 0 1 1
Выходы еще не равны целям, поэтому нужно обучить сеть для более чем одного пароля. попробуйте больше эпох. Этот прогон дает среднюю абсолютную погрешность 0 после двух периодов:
net.trainParam.epochs = 1000; net = train(net,p,t);
Таким образом, сеть была обучена к моменту представления входных данных в третью эпоху. (Как известно из ручного расчета, сеть сходится на представлении шестого входного вектора. Это происходит в середине второй эпохи, но для обнаружения сходимости сети требуется третья эпоха.) Окончательные веса и смещение
w = net.iw{1,1}, b = net.b{1}
w =
-2 -3
b =
1
Моделируемые выходные данные и ошибки для различных входных данных:
a = net(p)
a =
0 1 0 1
error = a-t
error =
0 0 0 0
Вы подтверждаете успешность процедуры обучения. Сеть сходится и выдает правильные целевые выходы для четырех входных векторов.
Функция обучения по умолчанию для сетей, созданных с помощью perceptron является trainc. (Это можно найти, выполнив команду net.trainFcn.) Эта обучающая функция применяет правило перцептронного обучения в чистом виде, в котором индивидуальные входные векторы применяются индивидуально, последовательно, и поправки к весам и смещению производятся после каждого представления входного вектора. Таким образом, обучение перцептрону с train будет сходиться в конечном количестве шагов, если только представленная проблема не может быть решена простым перцептроном.
Функция train может использоваться различными способами и другими сетями. Напечатать help train для получения дополнительной информации об этой базовой функции.
Вы можете попробовать различные примеры программ. Например, классификация с двухвходовым перцептроном иллюстрирует классификацию и обучение простого перцептрона.
Сети перцептрона должны быть обучены adapt, которая представляет входные векторы сети по одному и вносит поправки в сеть по результатам каждого представления. Использование adapt таким образом, гарантируется, что любая линейно отделяемая задача решается в ограниченном количестве тренировочных презентаций.
Как отмечалось на предыдущих страницах, перцептроны также могут быть обучены с функцией train. Обычно когда train используется для перцептронов, представляет входы в сеть партиями, вносит в сеть поправки на основе суммы всех индивидуальных поправок. К сожалению, нет доказательств того, что такой обучающий алгоритм сходится для перцептронов. На этот счет использование train для перцептронов не рекомендуется.
Сети перцептронов имеют несколько ограничений. Во-первых, выходные значения перцептрона могут принимать только одно из двух значений (0 или 1) из-за функции переноса жесткого предела. Во-вторых, перцептроны могут классифицировать только линейно разделяемые множества векторов. Если можно провести прямую линию или плоскость для разделения входных векторов на их правильные категории, входные векторы являются линейно разделяемыми. Если векторы не являются линейно разделяемыми, обучение никогда не достигнет точки, где все векторы классифицируются должным образом. Однако было доказано, что если векторы являются линейно разделяемыми, перцептроны, обученные адаптивно, всегда найдут решение за конечное время. Вы можете попробовать линейно неразделяемые векторы. Это показывает сложность попытки классификации входных векторов, которые не являются линейно разделяемыми.
Однако справедливо отметить, что сети с более чем одним перцептроном могут использоваться для решения более сложных проблем. Например, предположим, что у вас есть набор из четырех векторов, которые вы хотели бы классифицировать на отдельные группы, и что можно провести две линии, чтобы разделить их. Сеть с двумя нейронами может быть найдена так, что ее две границы решения классифицируют входные данные на четыре категории. Дополнительные сведения о перцептронах и более сложных проблемах перцептронов см. в [HDB1996].
Длительное время тренировки может быть вызвано наличием более внешнего входного вектора, длина которого намного больше или меньше, чем у других входных векторов. Применение правила обучения перцептрону включает в себя добавление и вычитание входных векторов из текущих весов и смещений в ответ на ошибку. Таким образом, входной вектор с большими элементами может привести к изменениям весов и смещений, которые требуют длительного времени для преодоления гораздо меньшего входного вектора. Чтобы увидеть, как отклонение влияет на обучение, можно попробовать использовать входные векторы отклонения.
Немного изменив правило обучения перцептрону, можно сделать время обучения нечувствительным к чрезвычайно большим или малым входным векторам отклонения.
Вот исходное правило для обновления весов:
pT = epT
Как показано выше, чем больше входной вектор p, тем больше его влияние на весовой вектор w. Таким образом, если входной вектор намного больше, чем другие входные векторы, то меньшие входные векторы должны быть представлены много раз, чтобы иметь эффект.
Решение состоит в нормализации правила таким образом, чтобы влияние каждого входного вектора на веса было одинаковой величины:
pT‖p‖=epT‖p ‖
Нормализованное правило перцептрона реализуется с помощью функции learnpn, который называется точно как learnp. Нормализованная функция правила перцептрона learnpn требует немного больше времени для выполнения, но значительно сокращает количество эпох, если имеются более внешние входные векторы. Можно попробовать Нормализованное правило перцептрона, чтобы увидеть, как работает это нормализованное правило обучения.
