Двухмерный детектор постоянной частоты ложных аварийных сигналов (CFAR)
Панель инструментов системы фазированных массивов/обнаружение
Блок 2-D CFAR Detector реализует детектор постоянной частоты ложной тревоги для двумерных данных изображения. Обнаружение объявляется, когда значение ячейки изображения превышает пороговое значение. Для поддержания постоянной частоты ложных аварийных сигналов пороговое значение устанавливается кратным мощности шума изображения. Детектор оценивает мощность шума от соседних ячеек, окружающих тестируемую ячейку (CUT), используя один из трех способов усреднения ячеек или способ статистики порядка. Способы усреднения клеток представляют собой усреднение клеток (CA), наибольшее усреднение клеток (GOCA) или наименьшее усреднение клеток (SOCA).
Для каждой испытательной ячейки детектор:
оценивает статистику шума по значениям ячеек в обучающем диапазоне, окружающем соту CUT.
вычисляет пороговое значение путем умножения оценки шума на пороговый коэффициент.
сравнивает значение ячейки CUT с пороговым значением для определения наличия или отсутствия цели. Если значение больше порогового значения, то присутствует целевой объект.
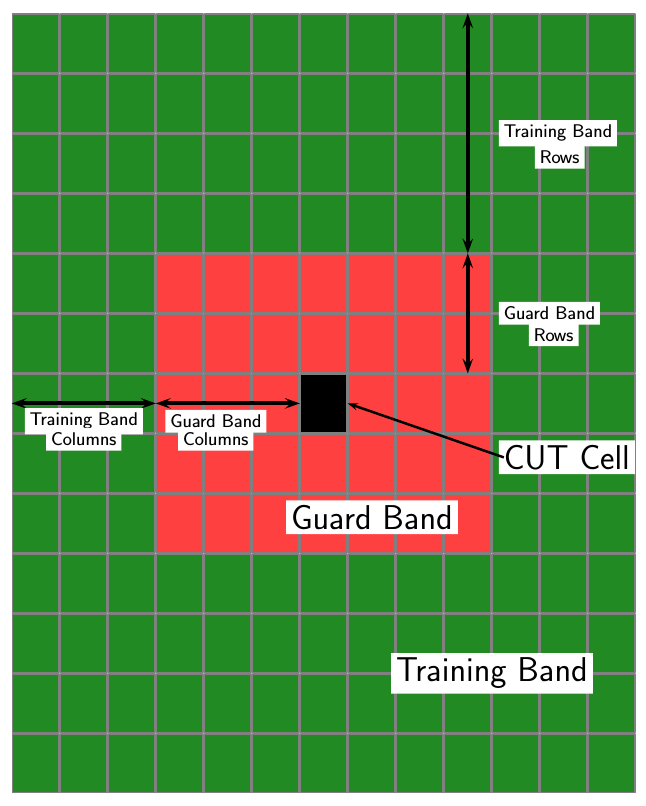
CFAR 2-D требует оценки мощности шума. Мощность шума вычисляется из ячеек, которые, как предполагается, не содержат никакого целевого сигнала. Эти клетки являются тренировочными. Тренировочные клетки образуют полосу вокруг тестируемой ячейки (CUT), но могут быть отделены от ячейки CUT защитной полосой. Порог обнаружения вычисляется путем умножения мощности шума на пороговый коэффициент.
Для усреднения GOCA и SOCA мощность шума получают из среднего значения одной из левой или правой половин области обучающей ячейки.
Поскольку количество столбцов в учебной области нечетное, ячейки в среднем столбце одинаково назначаются левой или правой половине.
При использовании метода order-statistic ранг не может быть больше, чем количество клеток в области тренировочных клеток, Ntrain. Можно вычислить Ntrain.
NTC - количество столбцов обучающей полосы.
NTR - количество строк обучающей полосы.
NGC - количество столбцов полосы защиты.
NGR - количество строк защитной полосы.
Общее число ячеек в комбинированной тренировочной области, защитной области и ячейке CUT равно Ntotal = (2NTC + 2NGC + 1) (2NTR + 2NGR + 1).
Общее число ячеек в объединенной защитной области и ячейке CUT равно Nguard = (2NGC + 1) (2NGR + 1).
Количество тренировочных ячеек - Ntrain = Ntotal - Nguard.
По конструкции количество тренировочных ячеек всегда ровное. Поэтому для реализации медианного фильтра можно выбрать ранг Ntrain/2 или Ntrain/2 + 1.
