Политика обучения усилению - это сопоставление, которое выбирает действие, выполняемое агентом на основе наблюдений из среды. Во время обучения агент настраивает параметры своего политического представления, чтобы максимизировать ожидаемое совокупное долгосрочное вознаграждение.
Агенты обучения усиления оценивают политики и функции стоимости, используя аппроксиматоры функций, называемые представлениями актера и критика соответственно. Актер представляет политику, которая выбирает наилучшее действие на основе текущего наблюдения. Критик представляет функцию стоимости, которая оценивает ожидаемое совокупное долгосрочное вознаграждение для текущей политики.
Перед созданием агента необходимо создать требуемые представления актера и критика с помощью глубоких нейронных сетей, линейных базисных функций или таблиц подстановки. Тип используемых аппроксиматоров функций зависит от приложения.
Дополнительные сведения об агентах см. в разделе Усиление агентов обучения.
Программное обеспечение Toolbox™ обучения усилению поддерживает следующие типы представлений:
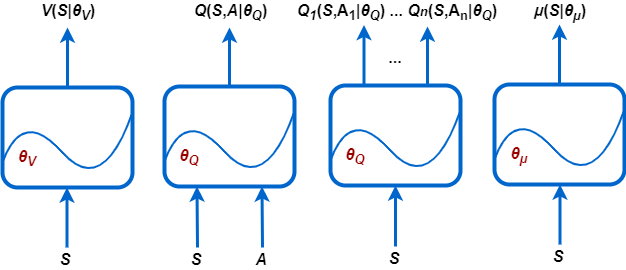
V (S 'startV) - критики, которые оценивают ожидаемое совокупное долгосрочное вознаграждение на основе данного наблюдения S. Вы можете создать этих критиков, используяrlValueRepresentation.
Q (S, A 'startQ) - критики, которые оценивают ожидаемое совокупное долгосрочное вознаграждение за данное дискретное действие A и данное наблюдение S. Вы можете создать этих критиков, используяrlQValueRepresentation.
Qi (S, Ai 'startQ) - Многоотходные критики, которые оценивают ожидаемое совокупное долгосрочное вознаграждение за все возможные дискретные действия Ai учитывая наблюдение S. Вы можете создать этих критиков, используяrlQValueRepresentation.
λ (S 'startλ) - актеры, которые выбирают действие на основе данного наблюдения S. Создать этих актеров можно с помощью одного из нихrlDeterministicActorRepresentation или rlStochasticActorRepresentation.
Каждое представление использует функцию approximator с соответствующим набором параметров (θV, θQ, θμ), которые вычислены во время процесса обучения.
Для систем с ограниченным количеством дискретных наблюдений и дискретных действий можно сохранить функции значений в таблице поиска. Для систем, которые имеют много дискретных наблюдений и действий, а также для пространств наблюдения и действий, которые являются непрерывными, хранение наблюдений и действий нецелесообразно. Для таких систем можно представить своих актёров и критиков с помощью глубоких нейронных сетей или пользовательских (линейных в параметрах) базисных функций.
В следующей таблице приведены общие сведения о том, как можно использовать четыре объекта представления, доступные с помощью программы «Инструментарий обучения армированию», в зависимости от пространств действий и наблюдений среды, а также от аппроксиматора и агента, которые требуется использовать.
Представления в сравнении с аппроксиматорами и агентами
| Представление | Поддерживаемые аппроксиматоры | Пространство наблюдения | Пространство действий | Поддерживаемые агенты |
|---|---|---|---|---|
Критик функции значения V (S), который создается с помощью | Стол | Дискретный | Неприменимо | PG, AC, PPO |
| Глубокая нейронная сеть или пользовательская базовая функция | Дискретный или непрерывный | Неприменимо | PG, AC, PPO | |
Критик функций Q-value, Q (S, A), которые создаются с помощью | Стол | Дискретный | Дискретный | Q, DQN, SARSA |
| Глубокая нейронная сеть или пользовательская базовая функция | Дискретный или непрерывный | Дискретный | Q, DQN, SARSA | |
| Глубокая нейронная сеть или пользовательская базовая функция | Дискретный или непрерывный | Непрерывный | DDPG, TD3 | |
Критик функции Q (S, A) с несколькими выходами, созданный с помощью | Глубокая нейронная сеть или пользовательская базовая функция | Дискретный или непрерывный | Дискретный | Q, DQN, SARSA |
Детерминированный политический субъект δ (S), который создается с помощью | Глубокая нейронная сеть или пользовательская базовая функция | Дискретный или непрерывный | Непрерывный | DDPG, TD3 |
Stochastic policy actor δ (S), который создается с помощью | Глубокая нейронная сеть или пользовательская базовая функция | Дискретный или непрерывный | Дискретный | PG, AC, PPO |
| Глубокая нейронная сеть | Дискретный или непрерывный | Непрерывный | PG, AC, PPO, SAC |
Дополнительные сведения об агентах см. в разделе Усиление агентов обучения.
Представления, основанные на таблицах подстановки, подходят для сред с ограниченным количеством дискретных наблюдений и действий. Можно создать два типа представлений таблицы подстановки:
Таблицы значений, в которых хранятся вознаграждения за соответствующие наблюдения
Q-таблицы, в которых хранятся вознаграждения за соответствующие пары наблюдение-действие
Чтобы создать табличное представление, сначала создайте таблицу значений или Q-таблицу с помощью rlTable функция. Затем создайте представление для таблицы с помощью rlValueRepresentation или rlQValueRepresentation объект. Чтобы настроить скорость обучения и оптимизацию, используемую представлением, используйте rlRepresentationOptions объект.
Создать аппроксиматоры функций актёра и критика можно с помощью глубоких нейронных сетей. При этом используются функции программного обеспечения Deep Learning Toolbox™.
Размеры ваших сетей актеров и критиков должны соответствовать соответствующим спецификациям действий и наблюдений из объекта учебной среды. Получение измерений действий и наблюдений для окружающей среды env, используйте getActionInfo и getObservationInfo соответственно. Затем получите доступ к Dimensions свойства объектов спецификации.
actInfo = getActionInfo(env); actDimensions = actInfo.Dimensions; obsInfo = getObservationInfo(env); obsDimensions = obsInfo.Dimensions;
Сети для критиков стоимостных функций (например, используемые в агентах AC, PG или PPO) должны принимать только наблюдения в качестве входных данных и иметь один скалярный выход. Для этих сетей размеры входных слоев должны соответствовать размерам спецификаций наблюдения окружающей среды. Дополнительные сведения см. в разделе rlValueRepresentation.
Сети для критиков функций Q-value с одним выходом (такие как сети, используемые в агентах Q, DQN, SARSA, DDPG, TD3 и SAC) должны принимать как наблюдения, так и действия в качестве входных данных и иметь один скалярный выход. Для этих сетей размеры входных слоев должны соответствовать размерам спецификаций среды как для наблюдений, так и для действий. Дополнительные сведения см. в разделе rlQValueRepresentation.
Сети для критиков многовыходных Q-стоимостных функций (например, используемые в агентах Q, DQN и SARSA) принимают только наблюдения за входами и должны иметь один выходной уровень с размером выхода, равным числу дискретных действий. Для этих сетей размеры входных слоев должны соответствовать размерам наблюдений окружающей среды. спецификации. Дополнительные сведения см. в разделе rlQValueRepresentation.
Для сетей акторов размеры входных слоев должны соответствовать размерам спецификаций наблюдения окружающей среды.
Сети, используемые в акторах с дискретным пространством действия (например, в агентах PG, AC и PPO), должны иметь один выходной уровень с размером выхода, равным числу возможных дискретных действий.
Сети, используемые в детерминированных акторах с непрерывным пространством действий (например, в DDPG и агентах TD3), должны иметь один уровень вывода с размером вывода, соответствующим размеру пространства действий, определенному в спецификации действий среды.
Сети, используемые в стохастических акторах с непрерывным пространством действия (например, в агентах PG, AC, PPO и SAC), должны иметь один выходной уровень с размером выхода, в два раза превышающим размер пространства действия, определенный в спецификации действия среды. Эти сети должны иметь два отдельных пути, первый из которых создает средние значения (которые должны быть масштабированы до выходного диапазона), а второй - стандартные отклонения (которые должны быть неотрицательными).
Дополнительные сведения см. в разделе rlDeterministicActorRepresentation и rlStochasticActorRepresentation.
Глубокие нейронные сети состоят из ряда взаимосвязанных слоев. В следующей таблице перечислены некоторые общие уровни глубокого обучения, используемые в приложениях обучения для усиления. Полный список доступных слоев см. в разделе Список слоев глубокого обучения.
| Слой | Описание |
|---|---|
featureInputLayer | Ввод данных элемента и применение нормализации |
imageInputLayer | Вводит векторы и 2-D изображения и применяет нормализацию. |
sigmoidLayer | Применяет сигмоидальную функцию к входу таким образом, что выход ограничен интервалом (0,1). |
tanhLayer | Применяет к входу слой активации гиперболической касательной. |
reluLayer | Устанавливает все входные значения, которые меньше нуля, равными нулю. |
fullyConnectedLayer | Умножает входной вектор на весовую матрицу и добавляет вектор смещения. |
convolution2dLayer | Применяет к входу скользящие сверточные фильтры. |
additionLayer | Добавляет вместе выходные данные нескольких слоев. |
concatenationLayer | Конкатенация входных данных вдоль заданного размера. |
sequenceInputLayer | Обеспечивает ввод данных последовательности в сеть. |
lstmLayer | Применяет к входу уровень долговременной кратковременной памяти. Поддерживается для агентов DQN и PPO. |
bilstmLayer и batchNormalizationLayer слои не поддерживаются для обучения армированию.
Инструментарий для обучения по армированию содержит следующие слои, которые не содержат настраиваемых параметров (то есть параметров, изменяющихся во время обучения).
| Слой | Описание |
|---|---|
scalingLayer | Применяет линейный масштаб и смещение к входному массиву. Этот слой полезен для масштабирования и сдвига выходных сигналов нелинейных слоев, таких как tanhLayer и sigmoidLayer. |
quadraticLayer | Создает вектор квадратичных мономеров, построенный из элементов входного массива. Этот уровень полезен, когда необходим выход, представляющий собой некую квадратичную функцию его входов, например, для контроллера LQR. |
softplusLayer | Реализует активацию softplus Y = log (1 + eX), которая гарантирует, что выходной сигнал всегда будет положительным. Эта функция является сглаженной версией выпрямленного линейного блока (ReLU). |
Можно также создать собственные пользовательские слои. Дополнительные сведения см. в разделе Определение пользовательских слоев глубокого обучения.
Для приложений обучения усилению вы создаете глубокую нейронную сеть, соединяя ряд слоев для каждого входного пути (наблюдения или действия) и для каждого выходного пути (предполагаемые вознаграждения или действия). Затем эти пути соединяются с помощью connectLayers функция.
Можно также создать глубокую нейронную сеть с помощью приложения Deep Network Designer. Пример см. в разделах Создание агента с помощью Deep Network Designer и Обучение с помощью наблюдений за изображениями.
При создании глубокой нейронной сети необходимо указать имена первого уровня каждого входного пути и конечного уровня выходного пути.
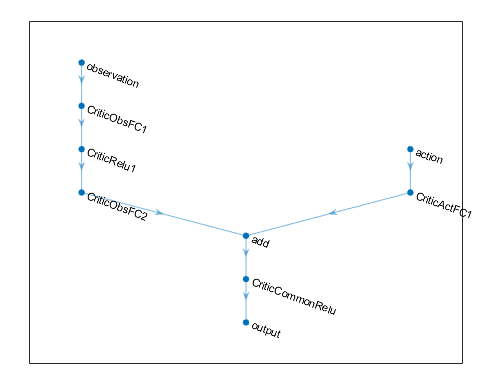
Следующий код создает и соединяет следующие пути ввода и вывода:
Входной путь наблюдения, observationPath, с первым слоем с именем 'observation'.
Путь ввода действия, actionPath, с первым слоем с именем 'action'.
Выходной путь функции расчетного значения, commonPath, который принимает выходы observationPath и actionPath в качестве входных данных. Конечному слою этого пути присвоено имя 'output'.
observationPath = [
imageInputLayer([4 1 1],'Normalization','none','Name','observation')
fullyConnectedLayer(24,'Name','CriticObsFC1')
reluLayer('Name','CriticRelu1')
fullyConnectedLayer(24,'Name','CriticObsFC2')];
actionPath = [
imageInputLayer([1 1 1],'Normalization','none','Name','action')
fullyConnectedLayer(24,'Name','CriticActFC1')];
commonPath = [
additionLayer(2,'Name','add')
reluLayer('Name','CriticCommonRelu')
fullyConnectedLayer(1,'Name','output')];
criticNetwork = layerGraph(observationPath);
criticNetwork = addLayers(criticNetwork,actionPath);
criticNetwork = addLayers(criticNetwork,commonPath);
criticNetwork = connectLayers(criticNetwork,'CriticObsFC2','add/in1');
criticNetwork = connectLayers(criticNetwork,'CriticActFC1','add/in2');Для всех путей ввода данных наблюдения и действий необходимо указать imageInputLayer в качестве первого слоя в контуре.
Вы можете просмотреть структуру вашей глубокой нейронной сети с помощью plot функция.
plot(criticNetwork)
Для агентов PG и AC окончательными выходными уровнями представления вашего глубокого нейронного сетевого актера являются fullyConnectedLayer и softmaxLayer. При указании слоев для сети необходимо указать fullyConnectedLayer и при необходимости можно указать softmaxLayer. Если опустить softmaxLayer, программное обеспечение автоматически добавляет один для вас.
Определение количества, типа и размера слоев для представления глубокой нейронной сети может быть затруднено и зависит от приложения. Однако наиболее важным компонентом при выборе характеристик аппроксиматора функции является возможность аппроксимации оптимальной политики или функции дисконтированного значения для вашего приложения, то есть наличие слоев, которые могут правильно узнать особенности ваших сигналов наблюдения, действия и вознаграждения.
Рассмотрим следующие советы при построении сети.
Для пространств непрерывных действий привязать действия с помощью tanhLayer за которым следует ScalingLayer, при необходимости.
Глубокие плотные сети с reluLayer слои могут быть довольно хорошими в аппроксимации многих различных функций. Поэтому они часто являются хорошим первым выбором.
Начните с наименьшей возможной сети, которая, по вашему мнению, может аппроксимировать оптимальную политику или функцию значения.
При аппроксимации сильных нелинейностей или систем с алгебраическими ограничениями добавление большего количества слоев часто лучше, чем увеличение числа выходов на слой. В общем, способность аппроксиматора представлять более сложные функции растет только полиномиально по размеру слоев, но растет экспоненциально с числом слоев. Другими словами, большее количество слоев позволяет аппроксимировать более сложные и нелинейные композиционные функции, хотя для этого обычно требуется больше данных и больше времени обучения. Сети с меньшим количеством уровней могут требовать экспоненциально больше единиц, чтобы успешно аппроксимировать один и тот же класс функций, и могут не учиться и правильно обобщаться.
Для агентов on-policy (тех, которые учатся только на опыте, накопленном при выполнении текущей политики), таких как агенты AC и PG, параллельное обучение работает лучше, если ваши сети большие (например, сеть с двумя скрытыми уровнями с 32 узлами каждый, которая имеет несколько сотен параметров). Параллельные обновления в соответствии с политикой предполагают, что каждый работник обновляет отдельную часть сети, например, при исследовании различных областей пространства наблюдения. Если сеть мала, обновления работника могут коррелировать друг с другом и делать обучение нестабильным.
Чтобы создать критическое представление для вашей глубокой нейронной сети, используйте rlValueRepresentation или rlQValueRepresentation объект. Чтобы создать представление актера для вашей глубокой нейронной сети, используйте rlDeterministicActorRepresentation или rlStochasticActorRepresentation объект. Чтобы настроить скорость обучения и оптимизацию, используемую представлением, используйте rlRepresentationOptions объект.
Например, создайте объект представления Q-значения для сети критиков criticNetwork, указывая скорость обучения 0.0001. При создании представления передайте действие среды и спецификации наблюдения в rlQValueRepresentation и укажите имена сетевых уровней, с которыми связаны наблюдения и действия (в данном случае 'observation' и 'action').
opt = rlRepresentationOptions('LearnRate',0.0001); critic = rlQValueRepresentation(criticNetwork,obsInfo,actInfo,... 'Observation',{'observation'},'Action',{'action'},opt);
При создании глубокой нейронной сети и настройке объекта представления следует использовать следующий подход в качестве отправной точки.
Начните с наименьшей возможной сети и высокой скорости обучения (0.01). Обучите эту начальную сеть, чтобы увидеть, быстро ли агент сходится с плохой политикой или действует случайным образом. В случае возникновения любой из этих проблем выполните масштабирование сети путем добавления большего количества уровней или более выходов на каждом уровне. Ваша цель - найти структуру сети, которая достаточно велика, не учится слишком быстро и показывает признаки обучения (улучшение траектории графика вознаграждений) после начального периода обучения.
После того как вы остановитесь на хорошей сетевой архитектуре, низкая начальная скорость обучения позволит вам увидеть, находится ли агент на правильном пути, и поможет вам проверить, удовлетворительна ли ваша сетевая архитектура для этой проблемы. Низкая скорость обучения значительно облегчает настройку параметров, особенно при сложных проблемах.
Кроме того, рассмотрим следующие советы при настройке представления глубокой нейронной сети.
Будьте терпеливы с агентами DDPG и DQN, поскольку они могут ничего не узнать в течение некоторого времени во время ранних эпизодов, и они обычно показывают падение совокупного вознаграждения на ранней стадии процесса обучения. В конце концов, они могут показать признаки обучения после первых нескольких тысяч эпизодов.
Для агентов DDPG и DQN решающее значение имеет содействие исследованию агента.
Для агентов с сетями как актёров, так и критиков установите начальные скорости обучения обоих представлений на одно и то же значение. Для некоторых проблем установка критического уровня обучения на более высокую величину, чем у актера, может улучшить результаты обучения.
При создании представлений для использования с любым агентом, кроме Q и SARSA, можно использовать рекуррентные нейронные сети (RNN). Эти сети являются глубокими нейронными сетями с sequenceInputLayer входной слой и, по меньшей мере, один слой, который имеет скрытую информацию о состоянии, такую как lstmLayer. Они могут быть особенно полезны, когда среда имеет состояния, которые не могут быть включены в вектор наблюдения.
Для агентов, имеющих как актёра, так и критика, необходимо либо использовать RNN для них обоих, либо не использовать RNN для любого из них. Нельзя использовать RNN только для критика или только для актёра.
При использовании агентов PG длина траектории обучения для RNN представляет собой весь эпизод. Для агента переменного тока NumStepsToLookAhead свойство - объект options рассматривается как длина учебной траектории. Для агента PPO длина траектории равна MiniBatchSize свойства его объекта options.
Для агентов DQN, DDPG, SAC и TD3 необходимо указать длину обучения траектории как целое число, большее единицы в SequenceLength свойство объекта их опций.
Следует отметить, что генерация кода не поддерживается для непрерывных действий агентов PG, AC, PPO и SAC, использующих повторяющуюся нейронную сеть (RNN), или для любого агента, имеющего несколько входных путей и содержащего RNN в любом из путей.
Дополнительные сведения и примеры о политиках и ценностных функциях см. в разделе rlValueRepresentation, rlQValueRepresentation, rlDeterministicActorRepresentation, и rlStochasticActorRepresentation.
Аппроксиматоры пользовательских (линейных в параметрах) базисных функций имеют вид f = W'B, где W является массивом весов и B является выводом вектора столбца пользовательской базисной функции, которую необходимо создать. Обучаемые параметры представления линейной базисной функции являются элементами W.
Для критических представлений функций значений (например, используемых в агентах AC, PG или PPO), f является скалярным значением, поэтому W должен быть вектором столбца той же длины, что и B, и B должно быть функцией наблюдения. Дополнительные сведения см. в разделе rlValueRepresentation.
Для критических представлений функций Q-value с одним выходом (таких как используемые в агентах Q, DQN, SARSA, DDPG, TD3 и SAC), f является скалярным значением, поэтому W должен быть вектором столбца той же длины, что и B, и B должна быть функцией как наблюдения, так и действия. Дополнительные сведения см. в разделе rlQValueRepresentation.
Для множественных выходных критических представлений функций Q-value с пространствами дискретных действий (например, используемых в агентах Q, DQN и SARSA), f - вектор, содержащий столько элементов, сколько возможно действий. Поэтому W должен быть матрицей, содержащей столько столбцов, сколько возможно действий, и столько строк, сколько длина B. B должна быть только функцией наблюдения. Дополнительные сведения см. в разделе rlQValueRepresentation.
Для субъектов с дискретным пространством действия (например, для агентов PG, AC и PPO), f должен быть столбчатым вектором длиной, равной числу возможных дискретных действий.
Для детерминированных субъектов с непрерывным пространством действия (например, в DDPG и TD3 агентах) размеры f должны соответствовать измерениям спецификации действия агента, которая является скаляром или вектором столбца.
Стохастические актёры с непрерывными пространствами действия не могут опираться на пользовательские базисные функции (они могут использовать только нейронные сетевые аппроксиматоры, из-за необходимости принудительно применять положительность для стандартных отклонений).
Для любого представления актера, W должно иметь столько столбцов, сколько элементов в fи столько же строк, сколько элементов в B. B должна быть только функцией наблюдения. Дополнительные сведения см. в разделе rlDeterministicActorRepresentation, и rlStochasticActorRepresentation.
Пример подготовки пользовательского агента, использующего представление линейной базовой функции, см. в разделе Подготовка пользовательского агента LQR.
После создания представлений актера и критика можно создать агент обучения усилению, который использует эти представления. Например, создайте PG-агент с использованием данного актера и сети критиков.
agentOpts = rlPGAgentOptions('UseBaseline',true);
agent = rlPGAgent(actor,baseline,agentOpts);Дополнительные сведения о различных типах агентов обучения усилению см. в разделе Агенты обучения усилению.
Можно получить представление актера и критика от существующего агента с помощью getActor и getCriticсоответственно.
Можно также задать актера и критика существующего агента с помощью setActor и setCriticсоответственно. При указании представления для существующего агента с помощью этих функций входные и выходные слои указанного представления должны соответствовать спецификациям наблюдения и действий исходного агента.
