В программном обеспечении Ampilation Learning Toolbox™ предусмотрены предопределенные среды Simulink ®, для которых уже определены действия, наблюдения, вознаграждения и динамика. Эти среды можно использовать для:
Изучите концепции обучения усилению.
Познакомьтесь с функциями ПО для обучения по усилению.
Протестируйте собственные агенты обучения усилению.
Следующие предопределенные среды Simulink можно загрузить с помощью rlPredefinedEnv функция.
| Окружающая среда | Задача агента |
|---|---|
| Простая маятниковая модель Simulink | Качаться вверх и уравновешивать простой маятник с помощью дискретного или непрерывного пространства действия. |
| Модель Simscape™ тележки | Уравновешивание полюса на движущейся тележке путем приложения усилий к тележке с использованием дискретного или непрерывного пространства действия. |
Для предварительно определенных сред Simulink динамика среды, наблюдения и сигнал вознаграждения определяются в соответствующей модели Simulink. rlPredefinedEnv функция создает SimulinkEnvWithAgent объект, который train использует для взаимодействия с моделью Simulink.
Эта среда представляет собой простой бесфрикционный маятник, который первоначально висит в нисходящем положении. Цель тренировки состоит в том, чтобы сделать маятник стоящим вертикально, не падая при минимальном усилии управления. Модель для этой среды определена в rlSimplePendulumModel Модель Simulink.
open_system('rlSimplePendulumModel')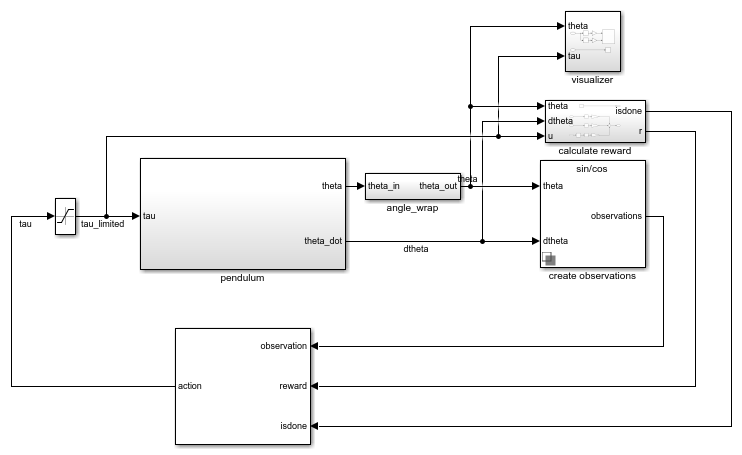
Существуют два простых варианта маятниковой среды, которые отличаются пространством действия агента.
Дискретный - агент может применить крутящий момент Tmax, 0, или -Tmax к маятнику, где Tmax - max_tau переменная в рабочем пространстве модели.
Continuous - Агент может применять любой крутящий момент в диапазоне [-Tmax, Tmax].
Для создания простой маятниковой среды используйте rlPredefinedEnv функция.
Пространство дискретного действия
env = rlPredefinedEnv('SimplePendulumModel-Discrete');Пространство непрерывного действия
env = rlPredefinedEnv('SimplePendulumModel-Continuous');Примеры подготовки агентов в простой маятниковой среде см. в:
В простых маятниковых средах агент взаимодействует с окружающей средой, используя один сигнал действия, крутящий момент, приложенный к основанию маятника. Среда содержит объект спецификации для этого сигнала действия. Для среды с:
Дискретное пространство действия, спецификация является rlFiniteSetSpec объект.
Непрерывное пространство действий, спецификация является rlNumericSpec объект.
Дополнительные сведения о получении спецификаций действий из среды см. в разделе getActionInfo.
В простой маятниковой среде агент принимает следующие три сигнала наблюдения, которые строятся в рамках подсистемы создания наблюдений.
Синус угла маятника
Косинус угла маятника
Производная угла маятника
Для каждого сигнала наблюдения среда содержит rlNumericSpec спецификация наблюдения. Все наблюдения непрерывны и неограниченны.
Дополнительные сведения о получении спецификаций наблюдения из среды см. в разделе getObservationInfo.
Сигнал вознаграждения для этой среды, который создается в подсистеме расчета вознаграждения, является
θt2+0.1∗θ˙t2+0.001∗ut−12)
Здесь:
startt - угол перемещения маятника из вертикального положения.
- производная угла маятника.
ut-1 - контрольное усилие от предыдущего временного шага.
Целью агента в предварительно определенных средах полюсов тележки является уравновешивание полюса на движущейся тележке путем приложения горизонтальных сил к тележке. Полюс считается успешно сбалансированным, если выполняются оба следующих условия:
Угол полюса остается в пределах заданного порога вертикального положения, где вертикальное положение равно нулю радиан.
Величина положения тележки остается ниже заданного порога.
Модель для этой среды определена в rlCartPoleSimscapeModel Модель Simulink. Динамика этой модели определяется с помощью Simscape Multibody™.
open_system('rlCartPoleSimscapeModel')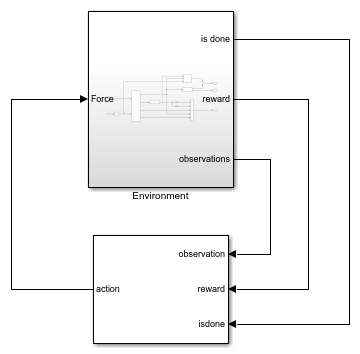
В подсистеме Environment динамика модели определяется с помощью компонентов Simscape, а вознаграждение и наблюдение создаются с помощью блоков Simulink.
open_system('rlCartPoleSimscapeModel/Environment')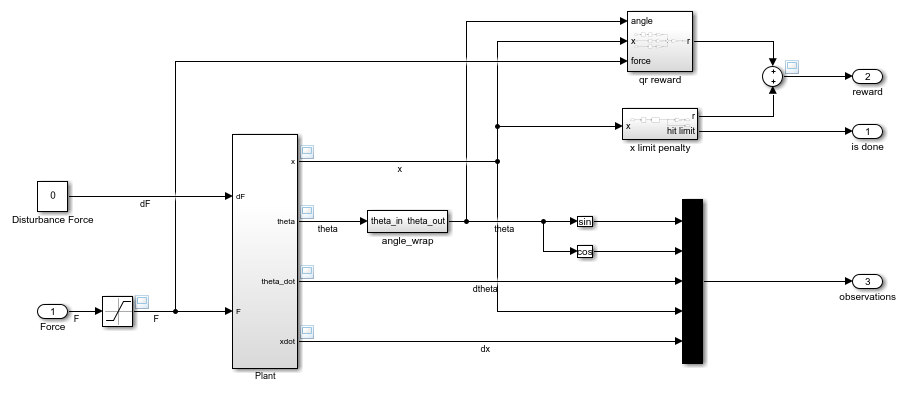
Существует два варианта среды cart-pole, которые отличаются пространством действия агента.
Дискретный - Агент может приложить силу, равную 15, 0, или -15 в тележку.
Непрерывно - Агент может применять любую силу в пределах диапазона [-15,15].
Для создания среды cart-pole используйте rlPredefinedEnv функция.
Пространство дискретного действия
env = rlPredefinedEnv('CartPoleSimscapeModel-Discrete');Пространство непрерывного действия
env = rlPredefinedEnv('CartPoleSimscapeModel-Continuous');Пример подготовки агента в этой среде cart-pole см. в разделе Подготовка агента DDPG к системе Swing Up и Balance Cart-Pole.
В средах «телега-полюс» агент взаимодействует с окружающей средой с помощью одного сигнала действия, силы, приложенной к телеге. Среда содержит объект спецификации для этого сигнала действия. Для среды с:
Дискретное пространство действия, спецификация является rlFiniteSetSpec объект.
Непрерывное пространство действий, спецификация является rlNumericSpec объект.
Дополнительные сведения о получении спецификаций действий из среды см. в разделе getActionInfo.
В среде тележек агент принимает следующие пять сигналов наблюдения.
Синус угла полюса
Косинус угла полюса
Производная угла маятника
Положение корзины
Производная от положения тележки
Для каждого сигнала наблюдения среда содержит rlNumericSpec спецификация наблюдения. Все наблюдения непрерывны и неограниченны.
Дополнительные сведения о получении спецификаций наблюдения из среды см. в разделе getObservationInfo.
Сигнал вознаграждения для этой среды представляет собой сумму трех компонентов (r = rqr + rn + rp):
Квадратичное вознаграждение за управление регулятором, построенное в Environment/qr reward подсистема.
0.1∗x2+0.5∗θ2+0.005∗ut−12)
Дополнительное вознаграждение за то, что полюс находится рядом с вертикальным положением, построенным в Environment/near upright reward подсистема.
0,175)
Штраф за ограничение корзины, построенный в Environment/x limit penalty подсистема. Эта подсистема генерирует отрицательное вознаграждение, когда величина положения тележки превышает заданный порог.
)
Здесь:
x - положение тележки.
λ - полюсный угол смещения из вертикального положения.
ut-1 - контрольное усилие от предыдущего временного шага.
