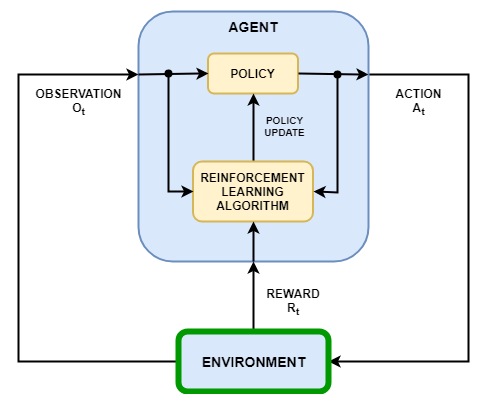
В сценарии обучения усилению, в котором агент обучается выполнению задачи, среда моделирует динамику взаимодействия агента. Как показано на следующем рисунке, среда:
Получает действия от агента.
Выводит замечания в ответ на действия.
Генерирует вознаграждение, измеряющее, насколько хорошо действие способствует выполнению задачи.
Создание модели среды включает в себя определение следующего:
Сигналы действий и наблюдения, которые агент использует для взаимодействия с окружающей средой.
Сигнал вознаграждения, который агент использует для измерения своего успеха. Дополнительные сведения см. в разделе Определение сигналов вознаграждения.
Динамическое поведение среды.
При создании объекта среды необходимо указать сигналы действия и наблюдения, которые агент использует для взаимодействия с средой. Можно создавать как дискретные, так и непрерывные пространства действий. Дополнительные сведения см. в разделе rlNumericSpec и rlFiniteSetSpecсоответственно.
Выбор сигналов в качестве действий и наблюдений зависит от приложения. Например, для систем управления интегралы (а иногда и производные) сигналов ошибок часто являются полезными наблюдениями. Кроме того, для приложений отслеживания ссылок полезно иметь изменяющийся во времени опорный сигнал в качестве наблюдения.
При определении сигналов наблюдения убедитесь, что все состояния системы видны через наблюдения. Например, наблюдение изображения качающегося маятника имеет информацию о положении, но не имеет достаточной информации для определения скорости маятника. В этом случае можно задать скорость маятника как отдельное наблюдение.
В программном обеспечении Ampilation Learning Toolbox™ предусмотрены предопределенные среды Simulink ®, для которых уже определены действия, наблюдения, вознаграждения и динамика. Эти среды можно использовать для:
Изучите концепции обучения усилению.
Познакомьтесь с функциями ПО для обучения по усилению.
Протестируйте собственные агенты обучения усилению.
Дополнительные сведения см. в разделе Загрузка предопределенных сред Simulink.
Чтобы задать собственную среду обучения усилению, создайте модель Simulink с блоком RL Agent. В этой модели подключите сигналы действия, наблюдения и вознаграждения к блоку агента RL. Пример см. в разделе Модель среды обучения усилению резервуара для воды.
Для сигналов действий и наблюдений необходимо создать объекты спецификации с помощью rlNumericSpec для непрерывных сигналов и rlFiniteSetSpec для дискретных сигналов. Для сигналов шины создайте спецификации с помощью bus2RLSpec.
Для сигнала вознаграждения создайте скалярный сигнал в модели и подключите этот сигнал к блоку агента RL. Дополнительные сведения см. в разделе Определение сигналов вознаграждения.
После настройки модели Simulink создайте объект среды для модели с помощью rlSimulinkEnv функция.
При наличии ссылочной модели с соответствующим входным портом действия, выходным портом наблюдения и выходным портом скалярного вознаграждения можно автоматически создать модель Simulink, включающую эту ссылочную модель и блок агента RL. Дополнительные сведения см. в разделе createIntegratedEnv. Эта функция возвращает объект среды, спецификации действий и спецификации наблюдения для модели.
Среда может включать функции сторонних производителей. Дополнительные сведения см. в разделе Интеграция с существующим моделированием или средой (Simulink).
createIntegratedEnv | rlPredefinedEnv | rlSimulinkEnv
