Обучение усилению - это целевой вычислительный подход, при котором компьютер учится выполнять задачу, взаимодействуя с неизвестной динамической средой. Этот подход обучения позволяет компьютеру принимать ряд решений, чтобы максимизировать совокупное вознаграждение за задачу без вмешательства человека и без явного программирования для выполнения задачи. На следующей диаграмме показано общее представление сценария обучения армированию.
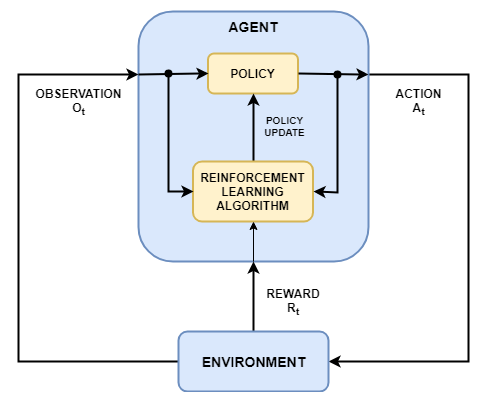
Целью обучения усилению является обучение агента выполнению задачи в неизвестной среде. Агент получает наблюдения и вознаграждение от окружающей среды и отправляет действия в окружающую среду. Награда - это показатель того, насколько успешным является действие в отношении выполнения задачи.
Агент содержит два компонента: политику и алгоритм обучения.
Политика представляет собой сопоставление, которое выбирает действия на основе наблюдений из среды. Обычно политика является аппроксиматором функции с настраиваемыми параметрами, такими как глубокая нейронная сеть.
Алгоритм обучения постоянно обновляет параметры политики на основе действий, наблюдений и вознаграждения. Целью алгоритма обучения является поиск оптимальной политики, которая максимизирует совокупное вознаграждение, полученное во время выполнения задачи.
Другими словами, обучение усилению включает в себя обучение агента оптимальному поведению посредством повторяющихся взаимодействий проб и ошибок с окружающей средой без участия человека.
В качестве примера рассмотрим задачу парковки транспортного средства с помощью автоматизированной системы вождения. Цель этой задачи состоит в том, чтобы компьютер транспортного средства (агент) поставил транспортное средство в правильное положение и ориентацию. Для этого контроллер использует показания камер, акселерометров, гироскопов, GPS-приемника и лидара (наблюдения) для генерации команд (действий) рулевого управления, торможения и ускорения. Команды действий посылаются на исполнительные механизмы, управляющие транспортным средством. Результаты наблюдений зависят от исполнительных механизмов, датчиков, динамики транспортного средства, дорожного покрытия, ветра и многих других менее важных факторов. Все эти факторы, то есть все, что не является агентом, составляют среду в усилении обучения.
Чтобы научиться генерировать правильные действия из наблюдений, компьютер неоднократно пытается запарковать транспортное средство с помощью процесса проб и ошибок. Для руководства процессом обучения вы даете сигнал, который один, когда автомобиль успешно достигает нужного положения и ориентации и ноль в противном случае (вознаграждение). Во время каждой пробной версии компьютер выбирает действия, используя сопоставление (политику), инициализированное с некоторыми значениями по умолчанию. После каждого испытания компьютер обновляет отображение, чтобы максимизировать вознаграждение (алгоритм обучения). Этот процесс продолжается до тех пор, пока компьютер не узнает оптимальное отображение, которое успешно паркует автомобиль.
Общий поток операций для обучения агента с использованием обучения усилению включает в себя следующие шаги.
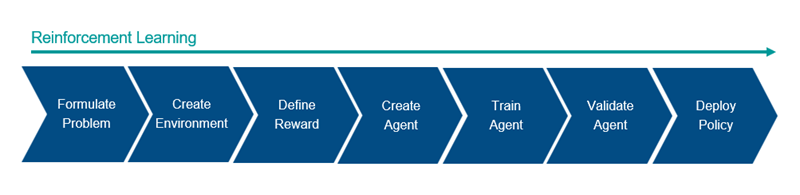
Сформулировать проблему - определите задачу для агента, чтобы узнать, как агент взаимодействует с окружающей средой и любые первичные и вторичные цели, которые агент должен достичь.
Создать среду - определение среды, в которой работает агент, включая интерфейс между агентом и средой и динамическую модель среды. Дополнительные сведения см. в разделах Создание учебных сред для усиления MATLAB и Создание учебных сред для усиления Simulink.
Определить вознаграждение (Define reward) - укажите сигнал вознаграждения, который агент использует для измерения его производительности в соответствии с целями задачи и способом вычисления этого сигнала из среды. Дополнительные сведения см. в разделе Определение сигналов вознаграждения.
Создать агента - создание агента, которое включает определение представления политики и настройку алгоритма обучения агента. Дополнительные сведения см. в разделах Создание представлений политик и ценностных функций и усиление обучающих агентов.
Train agent - подготовка представления политики агента с использованием определенной среды, вознаграждения и алгоритма обучения агента. Дополнительные сведения см. в разделе Обучение агентов обучения усилению.
Проверка агента - оценка производительности обученного агента путем совместного моделирования агента и среды. Дополнительные сведения см. в разделе Обучение агентов обучения усилению.
Развернуть политику - развернуть подготовленное представление политики, используя, например, созданный код графического процессора. Дополнительные сведения см. в разделе Развертывание обучающих политик обученного усиления.
Обучение агента с помощью обучения усилению является итеративным процессом. Для принятия решений и получения результатов на более поздних этапах может потребоваться вернуться на более ранний этап процесса обучения. Например, если процесс обучения не сходится к оптимальной политике в течение разумного периода времени, перед переподготовкой агента может потребоваться обновить любое из следующего:
Настройки обучения
Конфигурация алгоритма обучения
Политическое представительство
Определение сигнала вознаграждения
Сигналы действий и наблюдения
Динамика окружающей среды
