Вы можете использовать приложение Regression Learner для автоматического обучения выбора различных моделей в ваших данных. Используйте автоматизированное обучение, чтобы быстро попробовать выбрать типы моделей, а затем изучить перспективные модели в интерактивном режиме. Для начала выполните следующие действия:
| Начало работы с кнопками регрессионной модели | Описание |
|---|---|
| Все быстро переходить | Сначала нажмите кнопку «Все». Приложение обучает все типы моделей, которые обычно быстро обучаются. |
| Все | Используйте кнопку Все (All), чтобы обучить все доступные неоптимизируемые типы моделей. Тренирует каждый тип независимо от любых ранее обученных моделей. Это может занять много времени. |
Дополнительные сведения об обучении работе с автоматизированными моделями см. в разделе Обучение работе с автоматизированными регрессионными моделями.
Если требуется исследовать модели по одной или если уже известно, какой тип модели требуется, можно выбрать отдельные модели или обучить группу одного типа. Чтобы просмотреть все доступные опции регрессионной модели, на вкладке Обучающийся регрессии (Regression Learner) щелкните стрелку в разделе Тип модели (Model Type), чтобы развернуть список регрессионных моделей. Неоптимизируемые опции модели в галерее являются заданными начальными точками с различными настройками, подходящими для ряда различных проблем регрессии. Сведения об использовании параметров оптимизируемой модели и автоматической настройке гиперпараметров модели см. в разделе Оптимизация гиперпараметров в приложении регрессионного обучения.
Для получения справки по выбору наилучшего типа модели для проблемы см. таблицы, показывающие типичные характеристики различных типов регрессионных моделей. Решите, какой компромисс вы хотите в скорости, гибкости и интерпретируемости. Наилучший тип модели зависит от данных.
Совет
Чтобы избежать переоборудования, найдите менее гибкую модель, обеспечивающую достаточную точность. Например, ищите простые модели, такие как деревья регрессии, которые быстро и легко интерпретировать. Если модели недостаточно точно предсказывают отклик, выберите другие модели с более высокой гибкостью, например ансамбли. Для управления гибкостью см. подробные сведения по каждому типу модели.
Характеристики типов регрессионных моделей
| Тип регрессионной модели | Интерпретируемость |
|---|---|
| Модели линейной регрессии
| Легкий |
| Регрессионные деревья
| Легкий |
| Поддержка векторных машин
| Простота для линейных SVM. Трудно для других ядер. |
| Регрессионные модели гауссовых процессов
| Трудно |
| Ансамбли деревьев
| Трудно |
| Нейронные сети
| Трудно |
Чтобы прочитать описание каждой модели в модуле «Обучающийся регрессии», перейдите к представлению подробных данных в списке всех наборов параметров модели.
Совет
Неоптимизируемые модели в галерее Тип модели (Model Type) являются предустановленными начальными точками с различными настройками. После выбора типа модели, такого как деревья регрессии, попробуйте обучить все неоптимизируемые наборы параметров, чтобы увидеть, какая из них создает лучшую модель с вашими данными.
Инструкции по рабочему процессу см. в разделе Обучение регрессионным моделям в приложении Regression Learner App.
В Regression Learner все типы моделей поддерживают категориальные предикторы.
Совет
Если у вас есть категориальные предикторы со многими уникальными значениями, обучение линейных моделей с взаимодействием или квадратичными терминами и пошаговыми линейными моделями может использовать много памяти. Если модель не тренируется, попробуйте удалить эти категориальные предикторы.
Модели линейной регрессии имеют предикторы, которые являются линейными в параметрах модели, легко интерпретируются и являются быстрыми для составления прогнозов. Эти характеристики делают модели линейной регрессии популярными моделями, чтобы попытаться первыми. Однако сильно ограниченная форма этих моделей означает, что они часто имеют низкую точность прогнозирования. После подгонки модели линейной регрессии попробуйте создать более гибкие модели, такие как деревья регрессии, и сравнить результаты.
Совет
В галерее Тип модели (Model Type) щелкните Все линейные (All Linear
), чтобы попробовать каждую из![]() опций линейной регрессии и посмотреть, какие настройки создают наилучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
опций линейной регрессии и посмотреть, какие настройки создают наилучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
| Тип регрессионной модели | Интерпретируемость | Гибкость модели |
|---|---|---|
| Линейный | Легкий | Очень низкий |
| Взаимодействия Линейные | Легкий | Среда |
| Надежная линейная | Легкий | Очень низко. Менее чувствителен к отклонениям, но может медленно тренироваться. |
| Ступенчатая линейная | Легкий | Среда |
Совет
Пример рабочего процесса см. в разделе Подготовка деревьев регрессии с помощью приложения для обучения регрессии.
Обучающийся регрессии использует fitlm функция для обучения линейной, линейной и надежной линейной моделей. Приложение использует stepwiselm для тренировки ступенчатых линейных моделей.
Для моделей Линейная (Linear), Линейные взаимодействия (Interactions Linear) и Надежная линейная (Rustive Linear) можно задать следующие
Условия
Укажите, какие термины следует использовать в линейной модели. Вы можете выбрать один из следующих вариантов:
Linear. Постоянный член и линейные члены в предикторах
Interactions. Постоянный член, линейные члены и члены взаимодействия между предикторами
Pure Quadratic. Постоянный член, линейные члены и члены, которые являются чисто квадратичными в каждом из предикторов
Quadratic. Постоянный член, линейные члены и квадратичные члены (включая взаимодействия)
Надежный вариант
Укажите, следует ли использовать надежную целевую функцию и сделать модель менее чувствительной к отклонениям. При использовании этой опции метод подгонки автоматически назначает меньшие веса точкам данных, которые с большей вероятностью будут отклонениями.
Пошаговая линейная регрессия начинается с начальной модели и систематически добавляет и удаляет термины в модель, основываясь на объяснительной силе этих инкрементно больших и меньших моделей. Для ступенчатых линейных моделей можно задать следующие опции.
Исходные условия
Укажите термины, которые включены в начальную модель пошаговой процедуры. Вы можете выбрать из Constant, Linear, Interactions, Pure Quadratic, и Quadratic.
Верхняя граница для терминов
Укажите наивысший порядок терминов, которые пошаговая процедура может добавить в модель. Вы можете выбрать из Linear, Interactions, Pure Quadratic, и Quadratic.
Максимальное количество шагов
Укажите максимальное количество различных линейных моделей, которые можно попробовать в пошаговой процедуре. Чтобы ускорить обучение, попробуйте сократить максимальное количество шагов. Выбор небольшого максимального количества шагов снижает шансы найти хорошую модель.
Совет
Если у вас есть категориальные предикторы со многими уникальными значениями, обучение линейных моделей с взаимодействием или квадратичными терминами и пошаговыми линейными моделями может использовать много памяти. Если модель не тренируется, попробуйте удалить эти категориальные предикторы.
Регрессионные деревья легко интерпретировать, быстро подгонять и прогнозировать и недостаточно использовать память. Старайтесь выращивать более мелкие деревья с меньшим количеством более крупных листьев, чтобы предотвратить переоснащение. Задайте размер листа с помощью параметра Минимальный размер листа.
Совет
В галерее Тип модели (Model Type) щелкните Все деревья (All Trees
), чтобы попробовать каждую из![]() неоптимизируемых опций дерева регрессии и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
неоптимизируемых опций дерева регрессии и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
| Тип регрессионной модели | Интерпретируемость | Гибкость модели |
|---|---|---|
| Тонкое дерево | Легкий | Высоко Много небольших листьев для очень гибкой функции ответа (минимальный размер листа 4.) |
| Среднее дерево | Легкий | Среда Листья среднего размера для менее гибкой функции ответа (минимальный размер листа 12). |
| Грубое дерево | Легкий | Низко Мало больших листьев для функции грубой реакции (минимальный размер листа 36.) |
Чтобы предсказать отклик дерева регрессии, следуйте за деревом от корневого (начального) узла до узла листа. Конечный узел содержит значение ответа.
Деревья Toolbox™ статистики и машинного обучения являются двоичными. Каждый шаг в прогнозе включает в себя проверку значения одной прогнозирующей переменной. Например, вот простое дерево регрессии
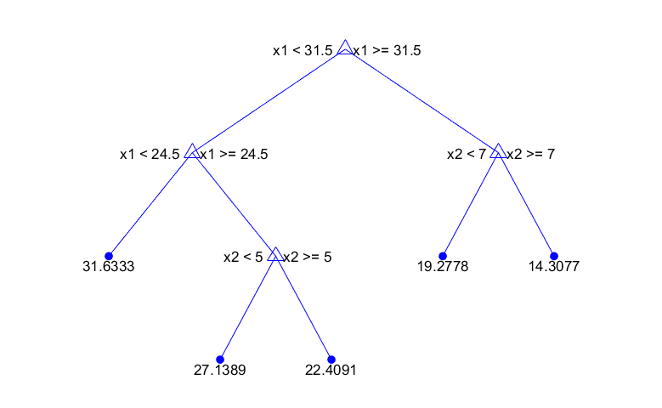
Это дерево предсказывает ответ на основе двух предикторов, x1 и x2. Чтобы сделать прогноз, начните с верхнего узла. В каждом узле проверьте значения предикторов, чтобы решить, за какой ветвью следует. Когда ветви достигают конечного узла, ответ устанавливается на значение, соответствующее этому узлу.
Можно визуализировать модель регрессионного дерева, экспортировав модель из приложения, а затем введя:
view(trainedModel.RegressionTree,'Mode','graph')
Совет
Пример рабочего процесса см. в разделе Подготовка деревьев регрессии с помощью приложения для обучения регрессии.
В приложении Regression Learner используется fitrtree функция для обучения деревьев регрессии. Можно задать следующие параметры:
Минимальный размер листа
Укажите минимальное количество обучающих образцов, используемых для вычисления ответа каждого конечного узла. Когда вы выращиваете регрессионное дерево, учитывайте его простоту и прогностическую силу. Чтобы изменить минимальный размер листа, нажмите кнопки или введите положительное целое значение в поле Минимальный размер листа.
Тонкое дерево со множеством мелких листьев обычно очень точно на тренировочных данных. Однако дерево может не показывать сопоставимую точность на независимом тестовом наборе. Очень листовое дерево имеет тенденцию к перевыполнению, и его точность проверки часто намного ниже, чем точность обучения (или повторного замещения).
В отличие от этого грубое дерево с меньшим количеством крупных листьев не достигает высокой точности тренировки. Но грубое дерево может быть более надежным в том смысле, что его точность обучения может быть близка к точности репрезентативного тестового набора.
Совет
Уменьшите минимальный размер листа, чтобы создать более гибкую модель.
Разделение суррогатного решения - только для отсутствующих данных.
Укажите использование суррогата для разделения решений. При наличии данных с отсутствующими значениями используйте суррогатные разделения для повышения точности прогнозов.
Если задано разделение суррогатного решения на Onдерево регрессии находит не более 10 суррогатных расщеплений в каждом узле ветви. Чтобы изменить количество суррогатных разделений, нажмите кнопки или введите положительное целое значение в поле Максимальное количество суррогатов на узел.
Если задано разделение суррогатного решения на Find All, дерево регрессии находит все суррогатные разделения в каждом узле ветви. Find All установка может использовать значительное время и память.
Можно также разрешить приложению автоматически выбирать некоторые из этих параметров модели с помощью оптимизации гиперпараметров. См. раздел Оптимизация гиперпараметров в приложении для учащихся с регрессией.
Можно обучить векторные машины поддержки регрессии (SVM) в модуле «Обучающийся регрессии». Линейные SVM легко интерпретировать, но могут иметь низкую точность прогнозирования. Нелинейные SVM более трудно интерпретировать, но могут быть более точными.
Совет
В галерее Тип модели щелкните Все SVM
, чтобы попробовать каждую из![]() неоптимизируемых опций SVM и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
неоптимизируемых опций SVM и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
| Тип регрессионной модели | Интерпретируемость | Гибкость модели |
|---|---|---|
| Линейный SVM | Легкий | Низко |
| Квадратичный SVM | Трудно | Среда |
| Кубический SVM | Трудно | Среда |
| Тонкий гауссов SVM | Трудно | Высоко Позволяет быстро изменять функцию ответа. Для масштаба ядра установлено значение sqrt(P)/4, где P - количество предикторов. |
| Средний гауссов SVM | Трудно | Среда Обеспечивает менее гибкую функцию отклика. Для масштаба ядра установлено значение sqrt(P). |
| Крупный гауссов SVM | Трудно | Низко Дает жесткую функцию отклика. Для масштаба ядра установлено значение sqrt(P)*4. |
Набор инструментов для статистики и машинного обучения реализует линейную регрессию SVM без учета эпсилонов. Этот SVM игнорирует ошибки прогнозирования, которые меньше, чем некоторое фиксированное число start. Векторы поддержки - это точки данных, которые имеют ошибки, большие, чем λ. Функция, используемая SVM для прогнозирования новых значений, зависит только от векторов поддержки. Дополнительные сведения о регрессии SVM см. в разделе Общие сведения о поддержке векторной машинной регрессии.
Совет
Пример рабочего процесса см. в разделе Подготовка деревьев регрессии с помощью приложения для обучения регрессии.
Обучающийся регрессии использует fitrsvm функция для обучения регрессионных моделей SVM.
В приложении можно задать следующие параметры:
Функция ядра
Функция ядра определяет нелинейное преобразование, применяемое к данным перед обучением SVM. Вы можете выбрать один из следующих вариантов:
Gaussian или ядро радиальной базовой функции (RBF)
Linear ядро, легче всего интерпретировать
Quadratic ядро
Cubic ядро
Режим ограничения прямоугольника
Ограничение поля управляет штрафом, наложенным на наблюдения с большими остатками. Большее ограничение рамки дает более гибкую модель. Меньшее значение дает более жесткую модель, менее чувствительную к переоборудованию.
Если для режима ограничения «Рамка» установлено значение Autoприложение использует эвристическую процедуру для выбора ограничения поля.
Попробуйте точно настроить модель, указав ограничение рамки вручную. Задать для режима ограничения «Поле» значение Manual и укажите значение. Измените значение, нажав кнопки или введя положительное скалярное значение в поле ограничения Поле вручную (Manual box constraint). Приложение автоматически выбирает для вас приемлемое значение. Попробуйте немного увеличить или уменьшить это значение и проверьте, улучшает ли это модель.
Совет
Увеличьте значение ограничения поля, чтобы создать более гибкую модель.
Режим эпсилона
Ошибки прогнозирования, которые меньше значения epsilon (start), игнорируются и обрабатываются как равные нулю. Меньшее значение эпсилона дает более гибкую модель.
Когда режим Epsilon установлен в Autoприложение использует эвристическую процедуру для выбора масштаба ядра.
Попробуйте точно настроить модель, указав значение эпсилона вручную. Установить режим Epsilon в значение Manual и укажите значение. Измените значение, нажав кнопки или введя положительное скалярное значение в поле Ручной эпсилон (Manual epsilon). Приложение автоматически выбирает для вас приемлемое значение. Попробуйте немного увеличить или уменьшить это значение и проверьте, улучшает ли это модель.
Совет
Уменьшите значение эпсилона, чтобы создать более гибкую модель.
Режим масштабирования ядра
Шкала ядра управляет масштабом предикторов, на которых ядро значительно варьируется. Меньшая шкала ядра дает более гибкую модель.
Если для режима масштаба ядра установлено значение Autoприложение использует эвристическую процедуру для выбора масштаба ядра.
Попробуйте настроить модель, указав масштаб ядра вручную. Установить режим масштабирования ядра в значение Manual и укажите значение. Измените значение, нажав кнопки или введя положительное скалярное значение в поле Масштаб ядра вручную. Приложение автоматически выбирает для вас приемлемое значение. Попробуйте немного увеличить или уменьшить это значение и проверьте, улучшает ли это модель.
Совет
Уменьшите значение масштаба ядра, чтобы создать более гибкую модель.
Стандартизировать
Стандартизация предикторов преобразует их таким образом, чтобы они имели среднее значение 0 и стандартное отклонение 1. Стандартизация устраняет зависимость от произвольных масштабов в предикторах и, как правило, улучшает производительность.
Можно также разрешить приложению автоматически выбирать некоторые из этих параметров модели с помощью оптимизации гиперпараметров. См. раздел Оптимизация гиперпараметров в приложении для учащихся с регрессией.
Модели регрессии гауссовых процессов (GPR) можно обучить в модуле Regression Learner. Модели GPR часто очень точны, но их трудно интерпретировать.
Совет
В галерее Тип модели (Model Type) щелкните Все модели GPR (All GPR Models
), чтобы попробовать каждую из![]() неоптимизируемых опций модели GPR и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
неоптимизируемых опций модели GPR и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
| Тип регрессионной модели | Интерпретируемость | Гибкость модели |
|---|---|---|
| Рациональный квадратичный | Трудно | Автоматический |
| Квадрат экспоненциальный | Трудно | Автоматический |
| Матерн 5/2 | Трудно | Автоматический |
| Показательный | Трудно | Автоматический |
В гауссовой регрессии процесса отклик моделируется с использованием распределения вероятностей по пространству функций. Гибкость предустановок в галерее Тип модели (Model Type) автоматически выбирается для обеспечения небольшой ошибки обучения и одновременно защиты от переоборудования. Дополнительные сведения о регрессии гауссова процесса см. в разделе Регрессионные модели гауссова процесса.
Совет
Пример рабочего процесса см. в разделе Подготовка деревьев регрессии с помощью приложения для обучения регрессии.
Обучающийся регрессии использует fitrgp функция для обучения моделей GPR.
В приложении можно задать следующие параметры:
Базисная функция
Базисная функция определяет форму предшествующей средней функции модели регрессии гауссова процесса. Вы можете выбрать из Zero, Constant, и Linear. Попробуйте выбрать другую базовую функцию и проверьте, улучшает ли это модель.
Функция ядра
Функция ядра определяет корреляцию в ответе как функцию расстояния между значениями предиктора. Вы можете выбрать из Rational Quadratic, Squared Exponential, Matern 5/2, Matern 3/2, и Exponential.
Дополнительные сведения о функциях ядра см. в разделе Параметры функции Kernel (Covariance).
Использовать изотропное ядро
При использовании изотропного ядра шкалы длины корреляции одинаковы для всех предикторов. Для неизотропного ядра каждая переменная предиктора имеет свою собственную шкалу длины корреляции.
Использование неизотропного ядра может повысить точность модели, но может замедлить подгонку модели.
Дополнительные сведения о неизотропных ядрах см. в разделе Параметры функции Kernel (Covariance).
Режим ядра
Можно вручную задать начальные значения параметров ядра Kernel scale и Signal standard deviation. Стандартное отклонение сигнала представляет собой предыдущее стандартное отклонение значений отклика. По умолчанию приложение локально оптимизирует параметры ядра, начиная с начальных значений. Чтобы использовать фиксированные параметры ядра, снимите флажок Оптимизировать числовые параметры в дополнительных параметрах.
Если для режима масштаба ядра установлено значение Autoприложение использует эвристическую процедуру для выбора исходных параметров ядра.
Если установлен режим масштаба ядра Manual, можно указать начальные значения. Нажмите кнопки или введите положительное скалярное значение в поле Масштаб ядра (Kernel scale) и поле Стандартное отклонение сигнала (Signal standard deviation).
Если снять флажок Использовать изотропное ядро, невозможно вручную установить начальные параметры ядра.
Режим «Сигма»
Можно вручную задать начальное значение среднеквадратического отклонения шума наблюдения Sigma. По умолчанию приложение оптимизирует стандартное отклонение шума наблюдения, начиная с начального значения. Чтобы использовать фиксированные параметры ядра, снимите флажок Оптимизировать числовые параметры в дополнительных параметрах.
Если режим Sigma установлен в Autoприложение использует эвристическую процедуру для выбора начального стандартного отклонения шума наблюдения.
Если для режима Sigma установлено значение Manual, можно указать начальные значения. Нажмите кнопки или введите положительное скалярное значение в поле Сигма (Sigma).
Стандартизировать
Стандартизация предикторов преобразует их таким образом, чтобы они имели среднее значение 0 и стандартное отклонение 1. Стандартизация устраняет зависимость от произвольных масштабов в предикторах и, как правило, улучшает производительность.
Оптимизация числовых параметров
С помощью этого параметра приложение автоматически оптимизирует числовые параметры модели GPR. Оптимизированные параметры - это коэффициенты функции Basis, параметры ядра Kernel scale и Signal standard deviation, а также стандартное отклонение Sigma шума наблюдения.
Можно также разрешить приложению автоматически выбирать некоторые из этих параметров модели с помощью оптимизации гиперпараметров. См. раздел Оптимизация гиперпараметров в приложении для учащихся с регрессией.
Можно обучать ансамбли деревьев регрессии в модуле «Обучающийся регрессии». Модели ансамбля объединяют результаты многих слабых учеников в одну качественную модель ансамбля.
Совет
В галерее Тип модели (Model Type) щелкните Все ансамбли (All Ensembles
), чтобы попробовать каждую из![]() неоптимизируемых опций ансамбля и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
неоптимизируемых опций ансамбля и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
| Тип регрессионной модели | Интерпретируемость | Метод ансамбля | Гибкость модели |
|---|---|---|---|
| Усиленные деревья | Трудно | Повышение наименьших квадратов ( | От среднего до высокого |
| Фасованные деревья | Трудно | Агрегация или пакетирование загрузочной ленты с учащимися регрессионного дерева. | Высоко |
Совет
Пример рабочего процесса см. в разделе Подготовка деревьев регрессии с помощью приложения для обучения регрессии.
Обучающийся регрессии использует fitrensemble функция для обучения моделей ансамблей. Можно задать следующие параметры:
Минимальный размер листа
Укажите минимальное количество обучающих образцов, используемых для вычисления ответа каждого конечного узла. Когда вы выращиваете регрессионное дерево, учитывайте его простоту и прогностическую силу. Чтобы изменить минимальный размер листа, нажмите кнопки или введите положительное целое значение в поле Минимальный размер листа.
Тонкое дерево со множеством мелких листьев обычно очень точно на тренировочных данных. Однако дерево может не показывать сопоставимую точность на независимом тестовом наборе. Очень листовое дерево имеет тенденцию к перевыполнению, и его точность проверки часто намного ниже, чем точность обучения (или повторного замещения).
В отличие от этого грубое дерево с меньшим количеством крупных листьев не достигает высокой точности тренировки. Но грубое дерево может быть более надежным в том смысле, что его точность обучения может быть близка к точности репрезентативного тестового набора.
Совет
Уменьшите минимальный размер листа, чтобы создать более гибкую модель.
Число обучающихся
Попробуйте изменить число обучающихся, чтобы узнать, можно ли улучшить модель. Многие ученики могут производить высокую точность, но это может занять много времени.
Совет
Увеличьте число обучающихся, чтобы создать более гибкую модель.
Уровень обучения
Для повышенных деревьев укажите скорость обучения для усадки. Если установить скорость обучения меньше 1, ансамбль требует больше итераций обучения, но часто достигает лучшей точности. 0.1 - популярный первоначальный выбор.
Можно также разрешить приложению автоматически выбирать некоторые из этих параметров модели с помощью оптимизации гиперпараметров. См. раздел Оптимизация гиперпараметров в приложении для учащихся с регрессией.
Модели нейронных сетей обычно имеют хорошую точность прогнозирования; однако их нелегко интерпретировать.
Гибкость модели увеличивается с размером и количеством полностью соединенных слоев в нейронной сети.
Совет
В галерее Тип модели (Model Type) щелкните Все нейронные сети (All Neural Networks
), чтобы попробовать каждый из![]() предустановленных параметров нейронной сети и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
предустановленных параметров нейронной сети и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
| Тип регрессионной модели | Интерпретируемость | Гибкость модели |
|---|---|---|
| Узкая нейронная сеть | Трудно | Средний - увеличивается с размером каждого полностью подключенного слоя |
| Средненейронная сеть | Трудно | Средний - увеличивается с размером каждого полностью подключенного слоя |
| Широкая нейронная сеть | Трудно | Средний - увеличивается с размером каждого полностью подключенного слоя |
| Билайерная нейронная сеть | Трудно | Высокий - увеличивается с размером каждого полностью подключенного слоя |
| Трилайерная нейронная сеть | Трудно | Высокий - увеличивается с размером каждого полностью подключенного слоя |
Каждая модель является прямой, полностью связанной нейронной сетью для регрессии. Первый полностью связанный уровень нейронной сети имеет соединение от сетевого входа (данные предиктора), а каждый последующий уровень имеет соединение от предыдущего уровня. Каждый полностью связанный слой умножает входной сигнал на весовую матрицу и затем добавляет вектор смещения. Функция активации следует за каждым полностью подключенным уровнем, исключая последний. Конечный полностью подключенный уровень формирует выходной сигнал сети, а именно прогнозируемые значения отклика. Дополнительные сведения см. в разделе Структура нейронной сети.
Пример см. в разделе Нейронные сети Train Regression Using Regression Learner App.
Обучающийся регрессии использует fitrnet функция для обучения моделей нейронных сетей. Можно задать следующие параметры:
Количество полностью соединенных слоев - количество полностью соединенных слоев в нейронной сети, исключая конечный полностью связанный слой для регрессии. Можно выбрать максимум три полностью соединенных слоя.
Размер каждого полностью подключенного слоя - укажите размер каждого полностью подключенного слоя, исключая конечный полностью подключенный слой. Если выбрана нейронная сеть с несколькими полностью соединенными слоями, попробуйте задать слои с уменьшающимися размерами.
Активация (Activation) - указывает функцию активации для всех полностью подключенных слоев, исключая конечный полностью подключенный слой. Выберите из следующих функций активации: ReLU, Tanh, Sigmoid, и None.
Предел итерации - укажите максимальное количество итераций обучения.
Сила термина «регуляризация» - укажите срок штрафа за регуляризацию гребня (L2).
Стандартизировать данные - укажите, следует ли стандартизировать числовые предикторы. Если предикторы имеют широко различные масштабы, стандартизация может улучшить подгонку. Настоятельно рекомендуется стандартизировать данные.
