Инкрементное обучение, или онлайн-обучение, - это ветвь машинного обучения, которая включает в себя обработку входящих данных из потока данных - непрерывно и в реальном времени - возможно, без знания распределения переменных предиктора, размера выборки, аспектов предсказания или целевой функции (включая адекватные значения параметров настройки), и имеют ли наблюдения метки.
Алгоритмы инкрементного обучения являются гибкими, эффективными и адаптивными. Следующие характеристики отличают инкрементное обучение от традиционного машинного обучения:
Инкрементная модель подходит для данных быстро и эффективно, что означает, что она может адаптироваться в реальном времени к изменениям (или смещениям) в распределении данных.
Поскольку метки наблюдения могут отсутствовать при наличии соответствующих данных предиктора, алгоритм должен быть способен быстро генерировать прогнозы из последней версии модели и откладывать обучение модели.
До начала инкрементного обучения о населении может быть известно мало информации. Поэтому алгоритм можно запустить с холодным запуском. Например, для проблем классификации имена классов могут быть известны только после того, как модель обработает наблюдения. Если до начала обучения известно достаточно информации (например, имеются хорошие оценки коэффициентов линейной модели), можно указать такую информацию для обеспечения модели теплым началом.
Поскольку наблюдения могут поступать в поток, размер выборки, вероятно, неизвестен и, возможно, велик, что делает хранение данных неэффективным или невозможным. Поэтому алгоритм должен обрабатывать наблюдения, когда они доступны и прежде чем система их отбросит. Эта инкрементная характеристика обучения делает гиперпараметрическую настройку трудной или невозможной.
В традиционном машинном обучении доступен пакет помеченных данных для выполнения перекрестной проверки, чтобы оценить ошибку обобщения и настроить гиперпараметры, вывести распределение переменных предиктора и подогнать модель. Однако результирующая модель должна быть переучена с самого начала, если основные распределения дрейфуют или модель ухудшается. Хотя выполнение перекрестной проверки для настройки гиперпараметров трудно в среде инкрементного обучения, методы инкрементного обучения являются гибкими, потому что они могут адаптироваться к дрейфу распределения в реальном времени с точностью прогнозирования, приближающейся к точности традиционно обученной модели, когда модель обучает больше данных.
Предположим, что инкрементная модель готова генерировать прогнозы и измерять их прогностическую производительность. Учитывая входящие порции наблюдений, схема инкрементного обучения обрабатывает данные в реальном времени и любым из следующих способов, но обычно в указанном порядке:
Оценка модели: отслеживание прогностической производительности модели при наличии истинных меток либо только на входящих данных, либо на скользящем окне наблюдений, либо на протяжении всей истории модели, используемой для инкрементного обучения.
Обнаружение дрейфа: проверка структурных разрывов или дрейфа распределения. Например, определить, достаточно ли изменилось распределение какой-либо предикторной переменной.
Модель поезда: Обновите модель, обучая ее входящим наблюдениям, когда доступны истинные метки или когда текущая модель достаточно деградировала.
Генерировать прогнозы: прогнозировать метки из последней модели.
Эта процедура представляет собой особый случай инкрементного обучения, в котором все входящие порции рассматриваются как тестовые (удерживаемые) наборы. Процедура называется перемеженной тестовой или преквенциальной оценкой [1].
Если для инкрементной модели существует недостаточная информация для генерации прогнозов или вы не хотите отслеживать прогностическую производительность модели, поскольку она недостаточно обучена, можно включить дополнительный начальный шаг для поиска адекватных значений гиперпараметров для моделей, поддерживающих одну (период оценки) или начальный период обучения перед оценкой модели (период прогрева метрик).
В качестве примера проблемы инкрементного обучения рассмотрим интеллектуальный термостат, который автоматически устанавливает температуру с учетом температуры окружающей среды, относительной влажности, времени суток и других измерений, а также может узнать предпочтения пользователя в отношении температуры внутри помещения. Предположим, производитель подготовил устройство, внедрив известную модель, которая описывает предпочтения среднего человека с учетом измерений. После установки устройство собирает данные каждую минуту и настраивает температуру в соответствии со своими настройками. Термостат настраивает встроенную модель или перестраивается, основываясь на действиях пользователя или бездействии с устройством. Этот цикл может продолжаться бесконечно долго. Если термостат имеет ограниченное дисковое пространство для хранения исторических данных, он должен переобучаться в режиме реального времени. Если производитель не готовил аппарат с известной моделью, аппарат чаще переквалифицируется.
Функции Toolbox™ статистики и машинного обучения позволяют реализовать инкрементное обучение для классификации или регрессии. Как и другие функции машинного обучения Statistics and Machine Learning Toolbox, точкой входа в инкрементное обучение является объект инкрементного обучения, который передается функциям с данными для реализации инкрементного обучения. В отличие от других функций машинного обучения, данные не требуются для создания инкрементного объекта обучения. Однако объект инкрементного обучения определяет, как обрабатывать поступающие данные, например, когда подгонять модель, измерять метрики производительности или выполнять оба действия, в дополнение к параметрической форме модели и специфичным для проблемы опциям.
Эта таблица содержит доступные объекты модели начального уровня для инкрементного обучения с их поддерживаемой целью машинного обучения, типом модели и любой информацией, необходимой при создании.
| Объект модели | Цель | Тип модели | Необходимая информация |
|---|---|---|---|
incrementalClassificationLinear | Двоичная классификация | Линейная SVM и логистическая регрессия | Ничего |
incrementalClassificationNaiveBayes | Многоклассная классификация | Наивный Байес с нормальными предикторными условными распределениями | Максимальное число классов, ожидаемых в данных во время инкрементного обучения, или имена всех ожидаемых классов |
incrementalRegressionLinear | Регресс | Линейный | Ничего |
Свойства объекта инкрементной модели обучения определяют:
Характеристики данных, такие как количество переменных предиктора NumPredictors и их первый и второй моменты.
Характеристики модели, например, для линейных моделей тип учащегося Learner, линейные коэффициенты Betaи перехватить Bias
Варианты обучения, такие как, для линейных моделей, целевой решатель Solver и специфичные для решателя гиперпараметры, такие как штраф по гребню Lambda для стандартного и среднего стохастического градиентного спуска (SGD и ASGD)
Характеристики и параметры оценки производительности модели, например, является ли модель теплой IsWarm, какие метрики производительности отслеживать Metricsи последние значения показателей производительности
В отличие от работы с другими объектами модели машинного обучения, можно создать любую модель путем непосредственного вызова объекта и задания значений свойств опций с помощью аргументов «имя-значение»; для создания модели не требуется подгонять ее под данные. Эта функция удобна, когда у вас мало информации о данных или модели перед ее обучением. В зависимости от ваших спецификаций, программное обеспечение может принудительно использовать периоды прогрева оценок и метрик, в течение которых функции инкрементной подгонки определяют характеристики данных, а затем обучать модель оценке производительности. По умолчанию для линейных моделей программное обеспечение решает целевую функцию с помощью адаптивного инвариантного по масштабам решателя, который не требует настройки и нечувствителен к масштабам переменных предиктора [2].
Можно также преобразовать традиционно обученную модель в любую модель с помощью incrementalLearner функция. Трансформируемые модели включают векторные машины поддержки (SVM) для двоичной классификации и регрессии, наивную классификацию Байеса и модели линейной регрессии. Например, incrementalLearner преобразует обученную модель линейной классификации типа ClassificationLinear в incrementalClassificationLinear объект. По умолчанию программа считает, что преобразованные модели должны быть подготовлены для всех аспектов инкрементного обучения (преобразованные модели являются теплыми). incrementalLearner переносит характеристики данных (такие как имена классов), подогнанные параметры и опции, доступные для инкрементного обучения из традиционно обученной модели, которая преобразуется. Например:
Для наивной классификации Байеса, incrementalLearner переносит все имена классов в данные, ожидаемые во время инкрементного обучения, и соответствующие моменты распределений условного предиктора (DistributionParameters).
Для линейных моделей, если целевой решатель традиционно обученной модели - SGD, incrementalLearner задает для решателя инкрементного обучения значение SGD.
Объект модели инкрементного обучения определяет все аспекты алгоритма инкрементного обучения, от обучения и подготовки оценки модели до обучения и оценки модели. Для реализации инкрементного обучения необходимо передать настроенную модель инкрементного обучения функции инкрементной аппроксимации или функции оценки модели. Функции инкрементного обучения Statistics и Machine Learning Toolbox предлагают два рабочих процесса, которые хорошо подходят для преквенциального обучения. Для простоты в следующих описаниях рабочего процесса предполагается, что модель подготовлена для оценки производительности модели (другими словами, модель является теплой).
Гибкий рабочий процесс - Когда блок данных доступен:
Вычисление показателей производительности накопительной и оконной модели путем передачи данных и текущей модели в updateMetrics функция. Данные обрабатываются как тестовые данные, поскольку модель еще не обучена на них. updateMetrics перезаписывает производительность модели, сохраненную в модели, новыми значениями. Для получения информации о линейных моделях см. раздел updateMetrics и, для наивных моделей классификации Байеса, см. updateMetrics.
Дополнительно можно определить дрейф распределения или ухудшение качества модели.
Обучение модели путем передачи входящего блока данных и текущей модели в fit функция. fit функция использует указанный решатель для подгонки модели к входящему фрагменту данных и перезаписывает текущие коэффициенты и смещение новыми оценками. Для получения информации о линейных моделях см. раздел fit и, для наивных моделей классификации Байеса, см. fit.
Гибкий рабочий процесс позволяет выполнять пользовательские оценки качества модели и данных до принятия решения о необходимости обучения модели. Все шаги необязательны, но вызывают updateMetrics прежде fit когда вы планируете вызвать обе функции.
Сжатый рабочий процесс - когда блок данных доступен, поставьте входящий блок и настроенную инкрементную модель в updateMetricsAndFit функция. updateMetricsAndFit требования updateMetrics сразу же за ним следует fit. Сжатый рабочий процесс позволяет легко внедрять инкрементное обучение с преквенциальной оценкой при планировании отслеживания производительности модели и обучения модели по всем входящим блокам данных. Для получения информации о линейных моделях см. раздел updateMetricsAndFit и, для наивных моделей классификации Байеса, см. updateMetricsAndFit.
После создания инкрементного объекта модели и выбора рабочего процесса для использования запишите цикл, реализующий инкрементное обучение:
Считывание части наблюдений из потока данных, когда часть доступна.
Внедрение гибкого или краткого потока операций. Для правильного выполнения инкрементного обучения перезаписайте входную модель выходной моделью. Например:
% Flexible workflow Mdl = updateMetrics(Mdl,X,Y); % Insert optional code Mdl = fit(Mdl,X,Y); % Succinct workflow Mdl = updateMetricsAndFit(Mdl,X,Y);
loss функция. loss возвращает скалярные потери; модель не корректируется. Для получения информации о линейных моделях см. раздел loss и, для наивных моделей классификации Байеса, см. loss.Конфигурации модели определяют, обучают ли функции инкрементного обучения или оценивают производительность модели во время каждой итерации. Конфигурации могут изменяться по мере обработки данных функций. Дополнительные сведения см. в разделе Инкрементные периоды обучения.
Дополнительно:
Создание прогнозов путем передачи фрагмента и последней модели в predict. Для получения информации о линейных моделях см. раздел predict и, для наивных моделей классификации Байеса, см. predict.
Если модель соответствовала данным, вычислите потерю повторного замещения, передав фрагмент и последнюю модель в loss.
Для наивных моделей классификации Байеса logp функция позволяет обнаруживать отклонения в реальном времени. Функция возвращает логарифмическую безусловную плотность вероятности переменных предиктора при каждом наблюдении в блоке.
Учитывая входящие порции данных, действия, выполняемые инкрементными функциями обучения, зависят от текущей конфигурации или состояния модели. На этом рисунке показаны периоды (последовательные группы наблюдений), в течение которых функции инкрементного обучения выполняют определенные действия.
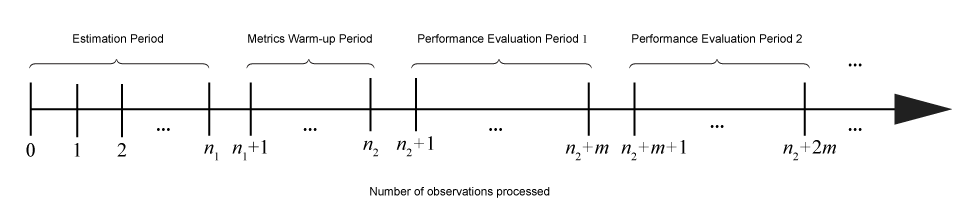
В этой таблице описываются действия, выполняемые инкрементными функциями обучения в течение каждого периода.
| Период | Связанные свойства модели | Размер (количество наблюдений) | Действия |
|---|---|---|---|
| Оценка | EstimationPeriod, применяется только к линейной классификации и регрессионным моделям | n1 | При необходимости аппроксимирующие функции выбирают значения для гиперпараметров на основе наблюдений периода оценки. Действия включают в себя следующее:
|
| Разминка метрик | MetricsWarmupPeriod | n2 – n1 | Когда свойство
|
| Оценка эффективности j | Metrics и MetricsWindowSize | m |
|
