Потеря линейной модели для инкрементного обучения по пакету данных
loss возвращает регрессию или потерю классификации сконфигурированной инкрементной модели обучения для линейной регрессии (incrementalRegressionLinear объект) или линейная двоичная классификация (incrementalClassificationLinear объект).
Чтобы измерить производительность модели в потоке данных и сохранить результаты в выходной модели, вызовите updateMetrics или updateMetricsAndFit.
Производительность инкрементной модели для потоковых данных измеряется тремя способами:
Кумулятивные метрики измеряют производительность с начала инкрементного обучения.
Метрики окна измеряют производительность указанного окна наблюдений. Метрики обновляются каждый раз при обработке модели указанного окна.
loss функция измеряет производительность только для указанного пакета данных.
Загрузите набор данных о деятельности персонала. Произвольно перетасовать данные.
load humanactivity n = numel(actid); rng(1); % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
Для получения подробной информации о наборе данных введите Description в командной строке.
Отклики могут быть одним из пяти классов: Сидя, стоя, Ходьба, Бега или Танцы. Дихотомизировать ответ, определив, движется ли субъект (actid > 2).
Y = Y > 2;
Создайте инкрементную линейную модель SVM для двоичной классификации. Сконфигурируйте его для loss путем указания имен классов, предшествующего распределения классов (равномерного) и произвольных значений коэффициентов и смещений. Укажите размер окна метрик, равный 1000 наблюдениям.
p = size(X,2); Beta = randn(p,1); Bias = randn(1); Mdl = incrementalClassificationLinear('Beta',Beta,'Bias',Bias,... 'ClassNames',unique(Y),'Prior','uniform','MetricsWindowSize',1000);
Mdl является incrementalClassificationLinear модель. Все его свойства доступны только для чтения. Вместо указания произвольных значений можно выполнить одно из следующих действий для настройки модели:
Обучение модели SVM с помощью fitcsvm или fitclinear на подмножестве данных (если доступно), а затем преобразовать модель в добавочный ученик с помощью incrementalLearner.
Инкрементная подгонка Mdl в данные с помощью fit.
Смоделировать поток данных и выполнить следующие действия над каждым входящим блоком из 50 наблюдений:
Звонить updateMetrics для измерения совокупной производительности и производительности в пределах окна наблюдений. Перезаписать предыдущую инкрементную модель новой, чтобы отслеживать метрики производительности.
Звонить loss для измерения производительности модели на входящем блоке.
Звонить fit для подгонки модели к входящему фрагменту. Перезаписать предыдущую инкрементную модель новой, установленной для входящего наблюдения.
Храните все показатели производительности, чтобы увидеть, как они развиваются во время инкрементного обучения.
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); ce = array2table(zeros(nchunk,3),'VariableNames',["Cumulative" "Window" "Loss"]); % Incremental learning for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetrics(Mdl,X(idx,:),Y(idx)); ce{j,["Cumulative" "Window"]} = Mdl.Metrics{"ClassificationError",:}; ce{j,"Loss"} = loss(Mdl,X(idx,:),Y(idx)); Mdl = fit(Mdl,X(idx,:),Y(idx)); end
Mdl является incrementalClassificationLinear объект модели обучен всем данным в потоке. Во время инкрементного обучения и после разогрева модели updateMetrics проверяет производительность модели на входящем наблюдении, затем и fit функция соответствует модели для этого наблюдения. loss агностика периода прогрева метрик, поэтому измеряет ошибку классификации для всех итераций.
Чтобы увидеть, как метрики производительности развивались во время обучения, постройте их график.
figure; plot(ce.Variables); xlim([0 nchunk]); ylim([0 0.05]) ylabel('Classification Error') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'r-.'); legend(ce.Properties.VariableNames) xlabel('Iteration')

Во время периода прогрева метрик (область слева от красной линии) желтая линия представляет ошибку классификации для каждого входящего фрагмента данных. После периода прогрева метрик, Mdl отслеживает кумулятивные и оконные метрики. Совокупные и пакетные потери сходятся, поскольку fit функция соответствует инкрементной модели входящим данным.
Подгонка инкрементной модели обучения для регрессии к потоковым данным и вычисление среднего абсолютного отклонения (MAD) для входящих пакетов данных.
Загрузите набор данных руки робота. Получение размера выборки n и количество переменных предиктора p.
load robotarm
n = numel(ytrain);
p = size(Xtrain,2);Для получения подробной информации о наборе данных введите Description в командной строке.
Создайте линейную модель приращения для регрессии. Сконфигурируйте модель следующим образом:
Укажите период прогрева метрик, равный 1000 наблюдениям.
Укажите размер окна метрик, равный 500 наблюдениям.
Отслеживание среднего абсолютного отклонения (MAD) для измерения производительности модели. Создайте анонимную функцию, измеряющую абсолютную ошибку каждого нового наблюдения. Создание массива структуры, содержащего имя MeanAbsoluteError и его соответствующей функции.
Настройте модель для прогнозирования ответов, указав, что все коэффициенты регрессии и смещение равны 0.
maefcn = @(z,zfit,w)(abs(z - zfit)); maemetric = struct("MeanAbsoluteError",maefcn); Mdl = incrementalRegressionLinear('MetricsWarmupPeriod',1000,'MetricsWindowSize',500,... 'Metrics',maemetric,'Beta',zeros(p,1),'Bias',0,'EstimationPeriod',0)
Mdl =
incrementalRegressionLinear
IsWarm: 0
Metrics: [2x2 table]
ResponseTransform: 'none'
Beta: [32x1 double]
Bias: 0
Learner: 'svm'
Properties, Methods
Mdl является incrementalRegressionLinear объект модели, настроенный для инкрементного обучения.
Выполнение инкрементного обучения. При каждой итерации:
Моделирование потока данных путем обработки части из 50 наблюдений.
Звонить updateMetrics для вычисления кумулятивных и оконных метрик для входящего блока данных. Перезаписать предыдущую инкрементную модель новой, чтобы перезаписать предыдущие метрики.
Звонить loss для вычисления MAD на входящем фрагменте данных. В то время как кумулятивные и оконные метрики требуют, чтобы пользовательские потери возвращали потери для каждого наблюдения, loss требует потери всего блока. Вычислите среднее значение абсолютного отклонения.
Звонить fit для подгонки инкрементной модели к входящему фрагменту данных.
Храните кумулятивные метрики, метрики окон и блоков, чтобы увидеть, как они развиваются во время инкрементного обучения.
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); mae = array2table(zeros(nchunk,3),'VariableNames',["Cumulative" "Window" "Chunk"]); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetrics(Mdl,Xtrain(idx,:),ytrain(idx)); mae{j,1:2} = Mdl.Metrics{"MeanAbsoluteError",:}; mae{j,3} = loss(Mdl,Xtrain(idx,:),ytrain(idx),'LossFun',@(x,y,w)mean(maefcn(x,y,w))); Mdl = fit(Mdl,Xtrain(idx,:),ytrain(idx)); end
IncrementalMdl является incrementalRegressionLinear объект модели обучен всем данным в потоке. Во время инкрементного обучения и после разогрева модели updateMetrics проверяет производительность модели на входящем наблюдении, и fit функция соответствует модели для этого наблюдения.
Постройте график показателей производительности, чтобы увидеть, как они развивались во время инкрементного обучения.
figure; h = plot(mae.Variables); ylabel('Mean Absolute Deviation') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'r-.'); xlabel('Iteration') legend(h,mae.Properties.VariableNames)

Сюжет предполагает следующее:
updateMetrics вычисляет показатели производительности только после периода прогрева показателей.
updateMetrics вычисляет кумулятивные метрики в течение каждой итерации.
updateMetrics вычисляет метрику окна после обработки 500 наблюдений
Поскольку Mdl был сконфигурирован для прогнозирования наблюдений с начала инкрементного обучения, loss может вычислять MAD для каждого входящего блока данных.
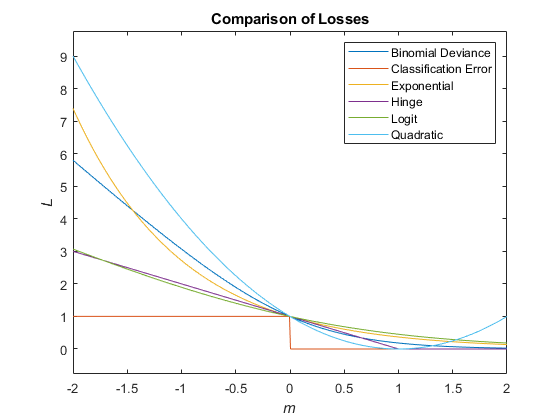
Функции потери классификации измеряют прогностическую неточность классификационных моделей. При сравнении одного и того же типа потерь между многими моделями меньшие потери указывают на лучшую прогностическую модель.
Рассмотрим следующий сценарий.
L - средневзвешенная потеря классификации.
n - размер выборки.
Для двоичной классификации:
yj - наблюдаемая метка класса. Программное обеспечение кодирует его как -1 или 1, указывая отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) - показатель классификации положительного класса для наблюдения (строки) j данных прогнозирования X.
mj = yjf (Xj) - показатель классификации для классификации наблюдения j в класс, соответствующий yj. Положительные значения mj указывают на правильную классификацию и не вносят большого вклада в средние потери. Отрицательные значения mj указывают на неправильную классификацию и вносят значительный вклад в средний убыток.
Вес для наблюдения j равен wj.
С учетом этого сценария в следующей таблице описаны поддерживаемые функции потерь, которые можно указать с помощью 'LossFun' аргумент пары имя-значение.
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | "binodeviance" | |
| Экспоненциальные потери | "exponential" | ). |
| Коэффициент неправильной классификации в десятичных разрядах | "classiferror" | j - метка класса, соответствующая классу с максимальным баллом. I {·} - функция индикатора. |
| Потеря шарнира | "hinge" | |
| Потеря журнала | "logit" | mj)). |
| Квадратичные потери | "quadratic" | ) 2. |
На этом рисунке сравниваются функции потерь над баллом m для одного наблюдения. Некоторые функции нормализуются для прохождения через точку (0,1).