Воспроизводимые вычисления дают одинаковые результаты при каждом запуске. Воспроизводимость важна для:
Отладка - для исправления аномального результата необходимо воспроизвести результат.
Уверенность - Когда вы можете воспроизвести результаты, вы можете исследовать и понять их.
Изменение существующего кода - при изменении существующего кода необходимо убедиться в том, что ничего не нарушено.
Как правило, нет необходимости обеспечивать воспроизводимость вычислений. Часто, когда вы хотите воспроизводимость, самый простой метод заключается в том, чтобы работать в серии, а не параллельно. При последовательном вычислении можно просто вызвать rng выполнять следующие функции:
s = rng % Obtain the current state of the random stream % run the statistical function rng(s) % Reset the stream to the previous state % run the statistical function again, obtain identical results
В этом разделе рассматривается случай, когда функция использует случайные числа, и требуется воспроизводимые результаты параллельно. В этом разделе также рассматривается случай, когда необходимо получить те же результаты параллельно, что и в серийном номере.
Для воспроизведения функции Toolbox™ статистики и машинного обучения:
Установите UseSubstreams опция для true использование statset.
Установите Streams для типа, поддерживающего субпотоки: 'mlfg6331_64' или 'mrg32k3a'. Для получения информации об этих потоках см. RandStream.list.
Для параллельного вычисления установите UseParallel опция для true.
Подгонка ансамбля параллельно с помощью fitcensemble или fitrensemble, создайте шаблон дерева с помощью 'Reproducible' пара имя-значение установлена в true:
t = templateTree('Reproducible',true); ens = fitcensemble(X,Y,'Method','bag','Learners',t,... 'Options',options);
Вызовите функцию со структурой опций.
Чтобы воспроизвести вычисления, сбросьте поток, а затем снова вызовите функцию.
Чтобы понять, почему этот метод обеспечивает воспроизводимость, см. раздел Как субпотоки включают воспроизводимые параллельные вычисления.
Например, для использования 'mlfg6331_64' поток для воспроизводимых вычислений:
Создайте соответствующую структуру опций:
s = RandStream('mlfg6331_64'); options = statset('UseParallel',true, ... 'Streams',s,'UseSubstreams',true);
Выполните параллельные вычисления. Инструкции см. в разделе Быстрый запуск параллельных вычислений для статистики и инструментария машинного обучения.
Сбросьте случайный поток:
reset(s);
Повторно запустите параллельные вычисления. Получаются идентичные результаты.
Примеры параллельного вычисления, выполняемого таким воспроизводимым способом, см. в разделе Воспроизводимая параллельная загрузка и ансамбль классификации поездов в параллельном режиме.
Подпоток - это часть случайного потока, которая RandStream может быстро получить доступ. Есть число M такой, что для любого положительного целого k, RandStream может перейти к kMпервое псевдослучайное число в потоке. С этого момента, RandStream может генерировать последующие записи в потоке. В настоящее время, RandStream имеет M = 272, около 5e21 или более.
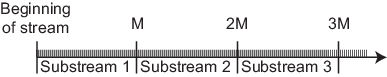
Записи в различных субпотоках имеют хорошие статистические свойства, подобные свойствам записей в одном потоке: независимость, отсутствие k-way корреляции на различных лагах. Субпотоки имеют такую длину, что можно рассматривать субпотоки как независимые потоки, как показано на следующем рисунке.

Два RandStream типы потоков поддерживают субпотоки: 'mlfg6331_64' и 'mrg32k3a'.
Когда MATLAB ® выполняет вычисления параллельно сparforкаждый работник получает итерации цикла в непредсказуемом порядке. Поэтому нельзя предсказать, какой работник получит какую итерацию, поэтому нельзя определить случайные числа, связанные с каждой итерацией.
Субпотоки позволяют MATLAB привязывать каждую итерацию к конкретной последовательности случайных чисел. parfor дает каждой итерации индекс. Итерация использует индекс в качестве номера подпотока. Поскольку случайные числа связаны с итерациями, а не с рабочими, все вычисления воспроизводимы.
Чтобы получить воспроизводимые результаты, просто сбросьте поток, и все субпотоки генерируют одинаковые случайные числа при повторном вызове. Этот метод успешно выполняется, когда все работники используют один и тот же поток, и поток поддерживает субпотоки. На этом завершается обсуждение того, как процедура выполнения воспроизводимых параллельных вычислений дает воспроизводимые параллельные результаты.
Несколько функций генерируют случайные числа на клиенте перед их распределением параллельным работникам. Рабочие не используют случайные числа, поэтому действуют чисто детерминированно. Для этих функций можно выполнять параллельные вычисления воспроизводимо с использованием любого случайного типа потока.
Функции, которые работают таким образом, включают в себя:
Чтобы получить идентичные результаты, сбросьте случайный поток на клиенте или случайный поток, передаваемый клиенту. Например:
s = rng % Obtain the current state of the random stream % run the statistical function rng(s) % Reset the stream to the previous state % run the statistical function again, obtain identical results
Хотя этот метод позволяет выполнять воспроизведение параллельно, результаты могут отличаться от последовательных вычислений. Причина разницы - parfor циклы выполняются в обратном порядке от for петли. Следовательно, последовательные вычисления могут генерировать случайные числа в порядке, отличном от параллельного вычисления. Для однозначной воспроизводимости используйте метод в разделе Выполнение воспроизводимых параллельных вычислений.
Для тестирования или сравнения с использованием определенных алгоритмов случайных чисел необходимо задать генераторы случайных чисел. Как вы устанавливаете эти генераторы параллельно или инициализируете потоки на каждом работнике определенным образом? Кроме того, может потребоваться выполнить вычисление с использованием другой последовательности случайных чисел, отличной от любой другой. Как обеспечить статистическую независимость используемой последовательности?
Функции Parallel Statistics и Machine Learning Toolbox позволяют явно задавать случайные потоки для каждого работника. Для получения информации о создании нескольких потоков введите help RandStream/create в командной строке. Создание четырех независимых потоков с помощью 'mrg32k3a' генератор:
s = RandStream.create('mrg32k3a','NumStreams',4,...
'CellOutput',true);Передача этих потоков статистической функции с помощью Streams вариант. Например:
parpool(4) % if you have at least 4 cores
s = RandStream.create('mrg32k3a','NumStreams',4,...
'CellOutput',true); % create 4 independent streams
paroptions = statset('UseParallel',true,...
'Streams',s); % set the 4 different streams
x = [randn(700,1); 4 + 2*randn(300,1)];
latt = -4:0.01:12;
myfun = @(X) ksdensity(X,latt);
pdfestimate = myfun(x);
B = bootstrp(200,myfun,x,'Options',paroptions);Этот метод распределения потоков дает каждому работнику свой поток для вычисления. Однако это не позволяет выполнять воспроизводимые вычисления, поскольку рабочие выполняют 200 загрузочных операций в непредсказуемом порядке. Если требуется выполнить воспроизводимые вычисления, используйте субпотоки, как описано в разделе Выполнение воспроизводимых параллельных вычислений.
Если установить UseSubstreams опция для true, затем установите Streams параметр для одного случайного потока типа, поддерживающего субпотоки ('mlfg6331_64' или 'mrg32k3a'). Эта настройка обеспечивает воспроизводимые вычисления.
