В этом примере показано, как настроить гиперпараметры модели вектора поддержки классификации (SVM) с помощью оптимизации гиперпараметров в приложении Classification Learner. Сравните производительность тестового набора обученного оптимизируемого SVM с производительностью наиболее производительной предварительно заданной модели SVM.
В окне команд MATLAB ® загрузите ionosphere и создайте таблицу, содержащую данные. Разделите таблицу на учебные и тестовые наборы.
load ionosphere tbl = array2table(X); tbl.Y = Y; rng('default') % For reproducibility of the data split partition = cvpartition(Y,'Holdout',0.15); idxTrain = training(partition); % Indices for the training set tblTrain = tbl(idxTrain,:); tblTest = tbl(~idxTrain,:);
Открыть классификатор. Перейдите на вкладку Приложения и щелкните стрелку справа от раздела Приложения, чтобы открыть галерею приложений. В группе Machine Learning and Deep Learning выберите Classification Learner.
На вкладке «Классификатор» в разделе «Файл» выберите «Новый сеанс» > «Из рабочей области».
В диалоговом окне «Новая сессия из рабочей области» выберите tblTrain из списка «Переменная набора данных».
Как показано в диалоговом окне, приложение выбирает переменные ответа и предиктора. Переменная ответа по умолчанию: Y. Для защиты от переоборудования по умолчанию используется пятикратная перекрестная проверка. В этом примере не изменяйте параметры по умолчанию.
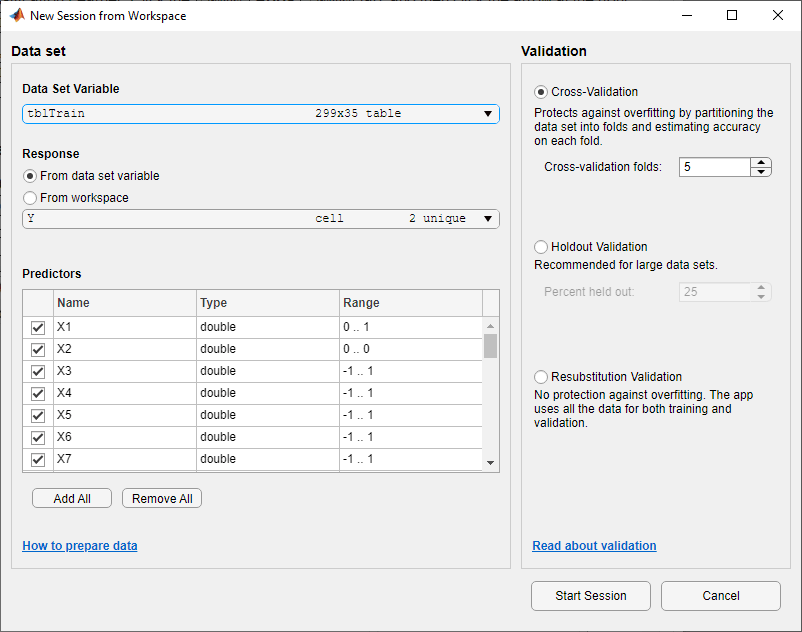
Чтобы принять параметры по умолчанию и продолжить, щелкните Начать сеанс (Start Session).
Обучение всех предварительно установленных моделей SVM. На вкладке «Классификатор» в разделе «Тип модели» щелкните стрелку, чтобы открыть галерею. В группе Поддерживаемые векторные машины щелкните Все SVM. В разделе Обучение щелкните Обучение. Приложение обучает одну из моделей каждого типа SVM и отображает модели на панели Модели.
Совет
При наличии Toolbox™ Parallel Computing можно одновременно обучить все модели SVM (All SVM), нажав кнопку Use Parallel в разделе Training, прежде чем нажать Train. После нажатия кнопки Обучить открывается диалоговое окно Открытие параллельного пула, которое остается открытым, пока приложение открывает параллельный пул работников. В течение этого времени взаимодействие с программным обеспечением невозможно. После открытия пула приложение одновременно обучает модели SVM.
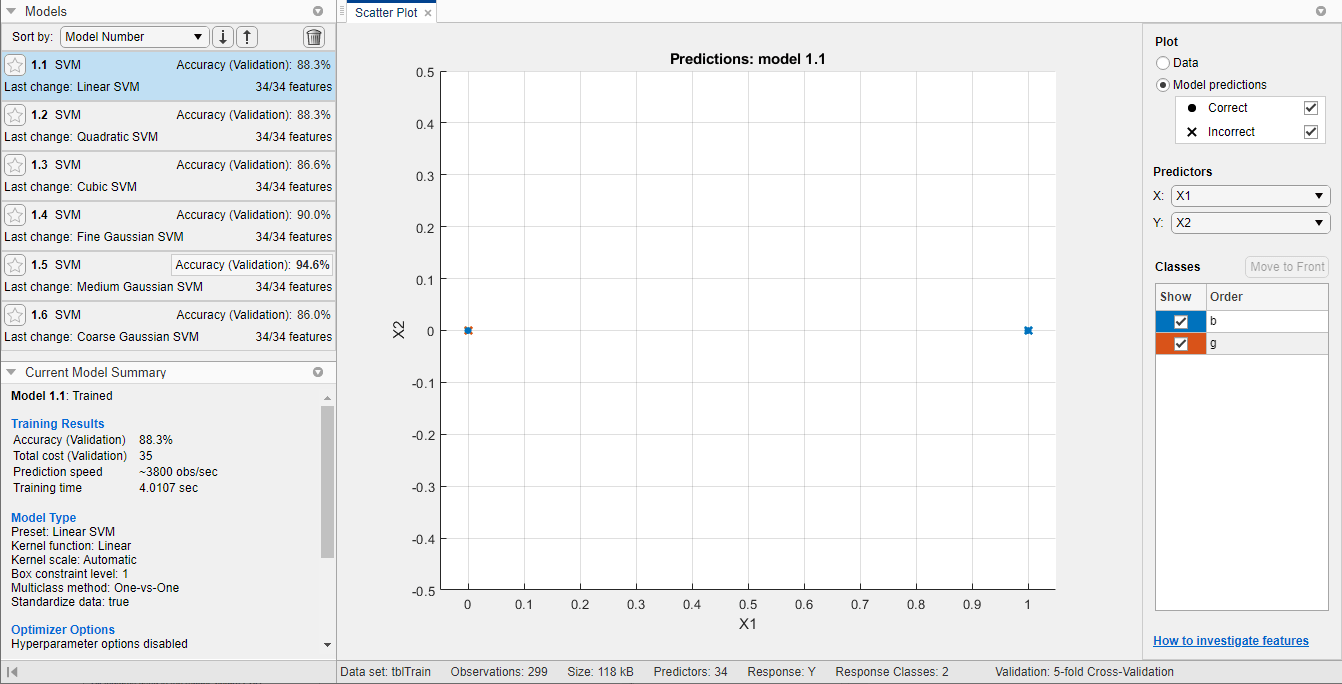
Приложение отображает график рассеяния ionosphere данные. Правильно классифицированные точки помечаются буквой O, а неправильно классифицированные точки - буквой X. На панели Модели слева показана точность проверки для каждой модели.
Примечание
Проверка вносит некоторую случайность в результаты. Результаты проверки модели могут отличаться от результатов, показанных в этом примере.
Выберите оптимизируемую модель SVM для обучения. На вкладке «Классификатор» в разделе «Тип модели» щелкните стрелку, чтобы открыть галерею. В группе Поддерживаемые векторные машины щелкните Оптимизируемый SVM. Приложение отключает кнопку «Использовать параллель» при выборе оптимизируемой модели.
Выберите гиперпараметры модели для оптимизации. В разделе Тип модели (Model Type) выберите Дополнительно (Advanced) > Дополнительно (Advanced). Приложение открывает диалоговое окно, в котором можно установить флажки Оптимизировать для гиперпараметров, которые требуется оптимизировать. По умолчанию для доступных гиперпараметров установлены все флажки. В этом примере снимите флажки Оптимизировать для функций Ядро и Стандартизировать данные. По умолчанию приложение отключает флажок Оптимизировать для масштаба ядра, когда функция ядра имеет фиксированное значение, отличное от Gaussian. Выберите Gaussian и установите флажок Оптимизировать для масштаба ядра.
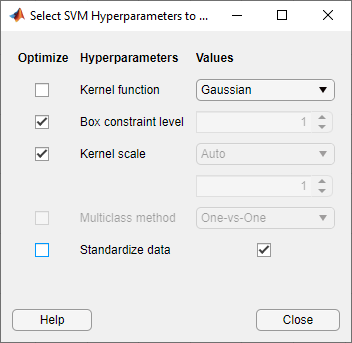
В разделе Обучение щелкните Обучение.
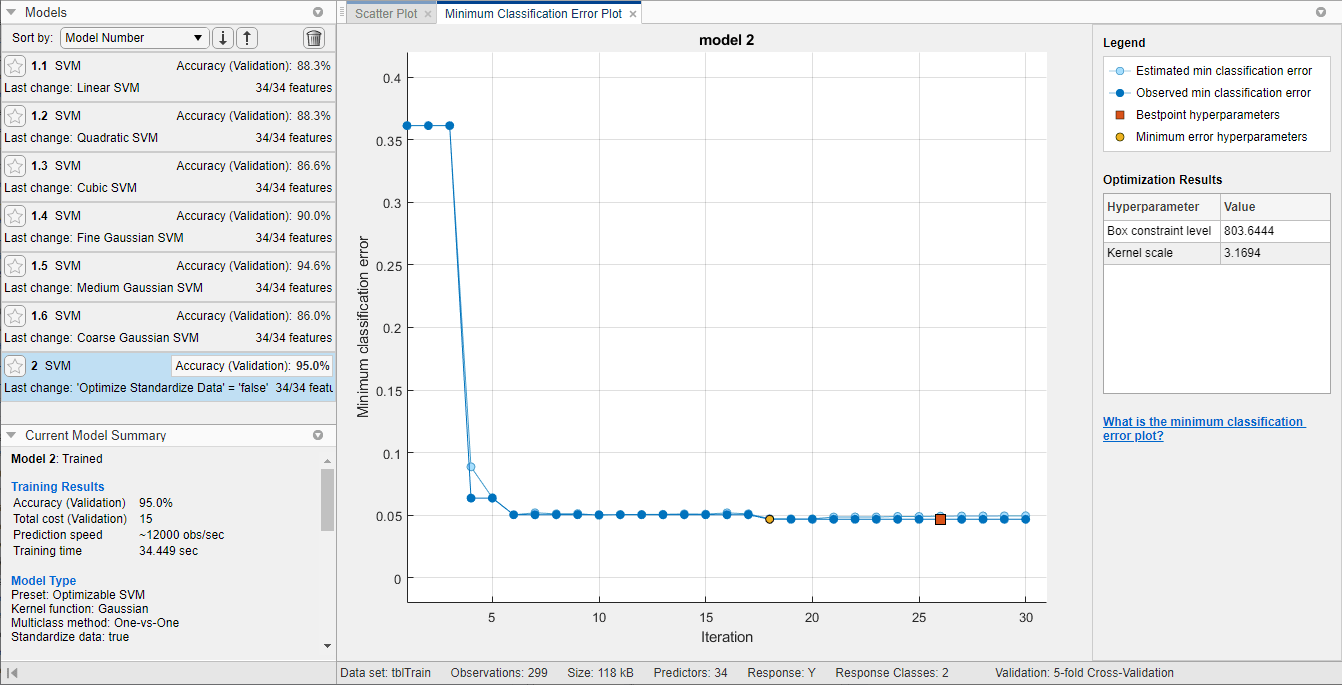
Приложение отображает график минимальной ошибки классификации при выполнении процесса оптимизации. При каждой итерации приложение пробует различную комбинацию значений гиперпараметров и обновляет график с минимальной ошибкой классификации проверки, наблюдаемой до этой итерации, обозначенной темно-синим цветом. Когда приложение завершает процесс оптимизации, оно выбирает набор оптимизированных гиперпараметров, обозначенных красным квадратом. Дополнительные сведения см. в разделе График минимальной ошибки классификации.
Приложение перечисляет оптимизированные гиперпараметры в разделе «Результаты оптимизации» справа от графика и в разделе «Оптимизированные гиперпараметры» панели «Сводка текущей модели».
Примечание
В общем, результаты оптимизации не воспроизводимы.
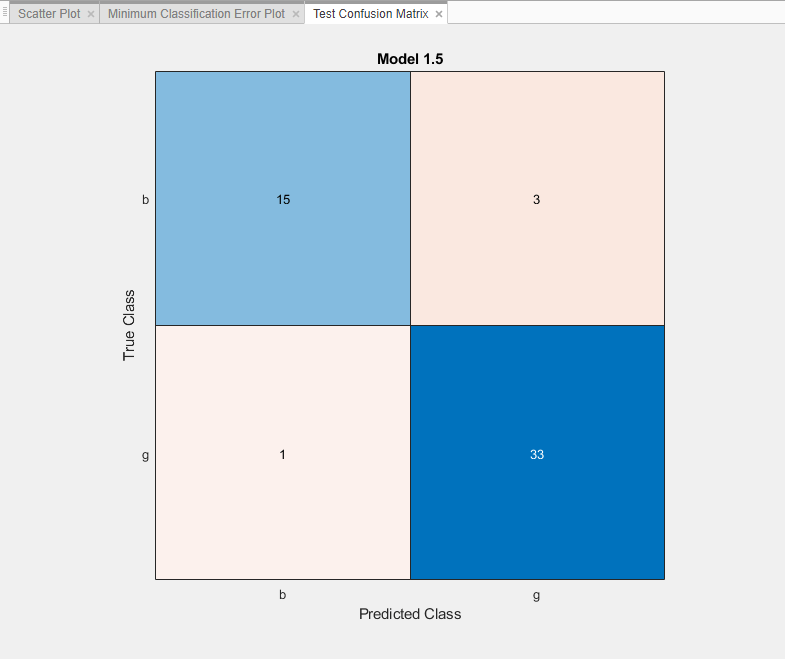
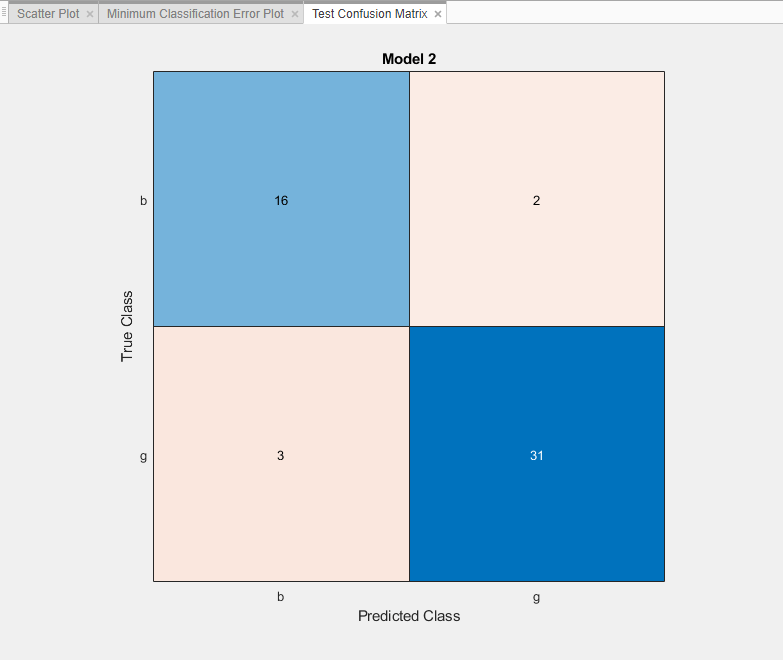
Сравните обученные предустановленные модели SVM с обученной оптимизированной моделью. На панели Модели (Models) приложение выделяет наивысшую точность (проверка), помещая ее в рамку. В этом примере обученная оптимизируемая модель SVM превосходит шесть предварительно установленных моделей.
Обученная оптимизируемая модель не всегда имеет более высокую точность, чем обученные предустановленные модели. Если обученная оптимизируемая модель работает плохо, можно попытаться получить лучшие результаты, выполнив оптимизацию дольше. В разделе «Тип модели» выберите «Дополнительно» > «Параметры оптимизатора». В диалоговом окне увеличьте значение Итерации (Iterations). Например, можно дважды щелкнуть значение по умолчанию 30 и введите значение 60.
Поскольку гиперпараметрическая настройка часто приводит к переоборудованию моделей, проверьте производительность оптимизируемой модели SVM на тестовом наборе и сравните ее с производительностью лучшей предустановленной модели SVM. Начните с импорта тестовых данных в приложение.
На вкладке Классификатор в разделе Тестирование выберите Тестовые данные > Из рабочей области.
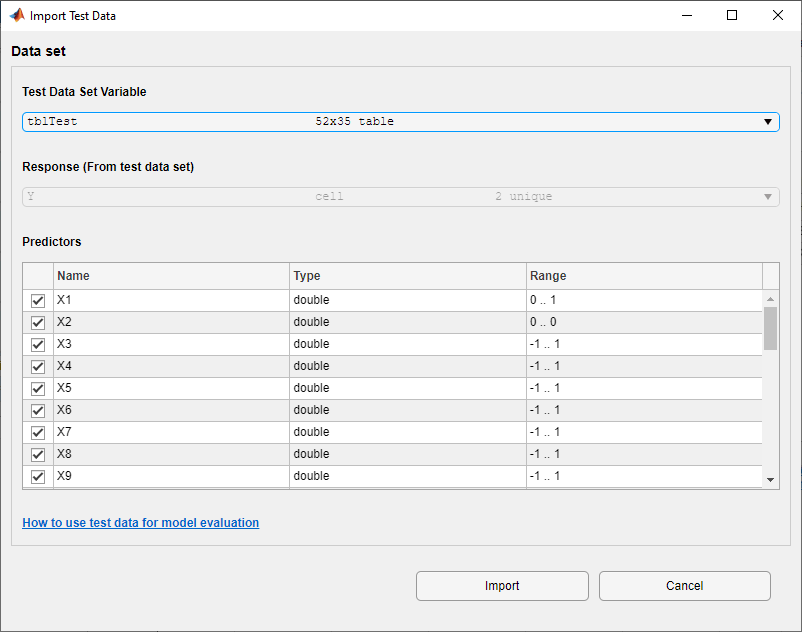
В диалоговом окне Import Test Data выберите tblTest из списка Test Data Set Variable.
Как показано в диалоговом окне, приложение идентифицирует переменные ответа и предиктора.
Щелкните Импорт (Import).
Вычислите точность наилучшей предустановленной модели и оптимизируемой модели на tblTest данные.
Сначала на панели Модели (Models) щелкните звездчатые значки рядом с моделью среднего гауссова SVM и моделью Optimizable SVM.
Для каждой модели выберите модель на панели Модели (Models), а затем выберите Проверить все (Test All) > Проверить выбранные (Test Selected) в разделе Тестирование (Testing). Приложение вычисляет производительность тестового набора модели, обученной на полном наборе данных, включая данные обучения и проверки.
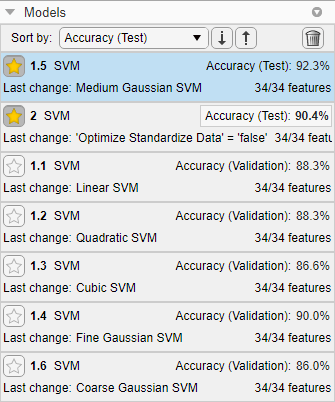
Сортировать модели по точности набора тестов. На панели Модели (Models) откройте список Сортировать по (Sort by) и выберите Accuracy (Test).
В этом примере обученная оптимизируемая модель не выполняет так же хорошо, как обученная предустановленная модель для данных тестового набора.
В разделе «Графики» на вкладке «Классификатор» выберите «Матрица путаницы» > «Тестовые данные». Переключение между средней моделью Gaussian SVM и оптимизируемой моделью SVM и визуальное сравнение двух матриц путаницы.