Можно использовать Classification Learner для автоматического обучения выбора различных классификационных моделей в данных. Используйте автоматизированное обучение, чтобы быстро попробовать выбрать типы моделей, а затем изучить перспективные модели в интерактивном режиме. Для начала выполните следующие действия:
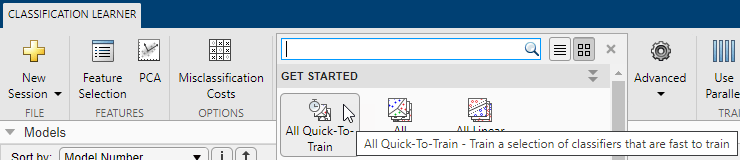
| Кнопки классификатора для начала работы | Описание |
|---|---|
| Все быстро переходить | Попробуй сначала. Приложение обучит всем типам моделей, доступным для набора данных, которые обычно быстро подходят. |
| Все линейные | Попробуйте сделать это, если ожидаются линейные границы между классами в данных. Эта опция подходит только для линейного SVM и линейного дискриминанта. |
| Все | Используется для обучения всех доступных неоптимизируемых типов моделей. Тренирует каждый тип независимо от любых ранее обученных моделей. Это может занять много времени. |
См. раздел Обучение автоматическому классификатору.
Если нужно исследовать классификаторы по одному или вы уже знаете, какой тип классификатора вы хотите, можно выбрать отдельные модели или обучить группу одного типа. Для просмотра всех доступных параметров классификатора на вкладке «Классификатор» щелкните стрелку в разделе «Тип модели», чтобы развернуть список классификаторов. Неоптимизируемые опции модели в галерее Тип модели (Model Type) являются предварительно заданными начальными точками с различными настройками, подходящими для различных проблем классификации. Сведения об использовании параметров оптимизируемой модели и автоматической настройке гиперпараметров модели см. в разделе Оптимизация гиперпараметров в приложении Classification Learner App.
Для получения справки по выбору наилучшего типа классификатора для вашей проблемы см. таблицу, показывающую типичные характеристики различных алгоритмов обучения под наблюдением. Используйте таблицу в качестве руководства для окончательного выбора алгоритмов. Выберите необходимый компромисс в скорости, использовании памяти, гибкости и интерпретируемости. Наилучший тип классификатора зависит от ваших данных.
Совет
Чтобы избежать переоборудования, найдите модель меньшей гибкости, которая обеспечивает достаточную точность. Например, ищите простые модели, такие как деревья решений и дискриминанты, которые быстро и легко интерпретировать. Если модели недостаточно точно предсказывают отклик, выберите другие классификаторы с более высокой гибкостью, например ансамбли. Для управления гибкостью см. подробные сведения для каждого типа классификатора.
Характеристики типов классификаторов
| Классификатор | Скорость прогнозирования | Использование памяти | Интерпретируемость |
|---|---|---|---|
|
Деревья принятия решений
| Быстро | Маленький | Легкий |
|
Дискриминантный анализ
| Быстро | Малый для линейных, большой для квадратичных | Легкий |
|
Логистическая регрессия
| Быстро | Среда | Легкий |
| Наивные байесовские классификаторы
| Средний для простых дистрибутивов Медленный для распределений ядра или высокоразмерных данных | Малый для простых дистрибутивов Носитель для распределения ядра или высокоразмерных данных | Легкий |
| Среда для линейного Медленный для других | Среда для линейных. Все остальные: средний для мультикласса, большой для бинарного. | Простота для линейного SVM. Трудно для всех других типов ядра. | |
|
Классификаторы ближайших соседей
| Медленный для кубических Средний для других | Среда | Трудно |
|
Классификаторы ансамблей
| Быстрый и средний в зависимости от выбора алгоритма | От низкого до высокого в зависимости от выбора алгоритма | Трудно |
|
Классификаторы нейронных сетей
| Быстро | Среда | Трудно |
Таблицы на этой странице описывают общие характеристики скорости и использования памяти для всех неоптимизируемых предварительно установленных классификаторов. Классификаторы были протестированы с различными наборами данных (до 7000 наблюдений, 80 предикторов и 50 классов), и результаты определяют следующие группы:
Скорость
Быстрый 0,01 сек.
Средняя 1 секунда
Медленный 100 секунд
Память
Малые 1MB
Средняя 4MB
Большие 100MB
Эти таблицы содержат общее руководство. Результаты зависят от данных и скорости машины.
Чтобы прочитать описание каждого классификатора в Classification Learner, перейдите к ракурсу подробных данных.
Совет
После выбора типа классификатора (например, дерева решений) попробуйте провести обучение с использованием каждого из классификаторов. Неоптимизируемые опции в галерее Тип модели (Model Type) являются начальными точками с различными настройками. Попробуйте их все, чтобы увидеть, какой вариант создает лучшую модель с вашими данными.
Инструкции по работе см. в разделе Модели классификации поездов в приложении Classification Learner App.
В Classification Learner в галерее Model Type отображаются доступные типы классификаторов, которые поддерживают выбранные данные.
| Классификатор | Все предикторы числовые | Все предикторы категоричны | Некоторые категориальные, некоторые числовые |
|---|---|---|---|
| Деревья принятия решений | Да | Да | Да |
| Дискриминантный анализ | Да | Нет | Нет |
| Логистическая регрессия | Да | Да | Да |
| Наивный Байес | Да | Да | Да |
| SVM | Да | Да | Да |
| Ближайший сосед | Только евклидово расстояние | Только расстояние хэмминга | Нет |
| Ансамбли | Да | Да, за исключением дискриминанта подпространства | Да, за исключением любого подпространства |
| Нейронные сети | Да | Да | Да |
Деревья принятия решений легко интерпретировать, быстро подгонять и прогнозировать и недостаточно использовать память, но они могут иметь низкую точность прогнозирования. Старайтесь выращивать более простые деревья, чтобы предотвратить переоборудование. Управление глубиной осуществляется с помощью параметра Максимальное количество разбиений (Maximum number of splits).
Совет
Гибкость модели увеличивается с параметром Максимальное количество разбиений (Maximum number of splits).
| Тип классификатора | Скорость прогнозирования | Использование памяти | Интерпретируемость | Гибкость модели |
|---|---|---|---|---|
| Грубое дерево | Быстро | Маленький | Легкий | Низко Мало листьев для проведения грубых различий между классами (максимальное количество расщеплений - 4). |
| Среднее дерево | Быстро | Маленький | Легкий | Среда Среднее количество листьев для более тонких различий между классами (максимальное количество делений - 20). |
| Тонкое дерево | Быстро | Маленький | Легкий | Высоко Многие оставляют много тонких различий между классами (максимальное количество расщеплений - 100). |
Совет
В галерее Тип модели (Model Type) щелкните Все деревья (All Trees), чтобы попробовать каждый из неоптимизируемых вариантов дерева решений. Обучите их всем, чтобы увидеть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models). Чтобы попытаться улучшить модель, попробуйте выбрать элемент, а затем изменить некоторые дополнительные параметры.
Вы обучаете деревья классификации предсказывать ответы на данные. Чтобы предсказать ответ, следуйте решениям в дереве от корневого (начального) узла до конечного узла. Конечный узел содержит ответ. Деревья Toolbox™ статистики и машинного обучения являются двоичными. Каждый шаг в прогнозе включает в себя проверку значения одного предсказателя (переменной). Например, вот простое дерево классификации:
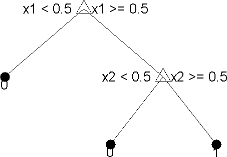
Это дерево предсказывает классификации на основе двух предикторов, x1 и x2. Чтобы предсказать, начните с верхнего узла. При каждом решении проверьте значения предикторов, чтобы решить, за какой ветвью следует. Когда ветви достигают конечного узла, данные классифицируются как тип 0 или 1.
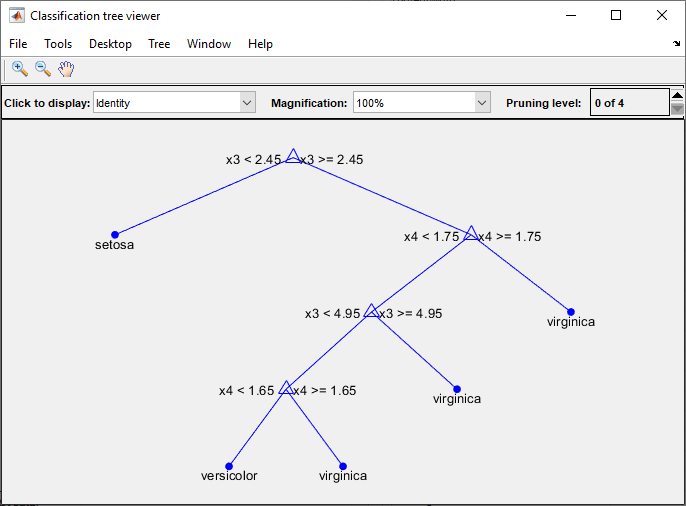
Модель дерева решений можно визуализировать, экспортировав модель из приложения и введя следующие данные:
view(trainedModel.ClassificationTree,'Mode','graph')
fisheriris данные.
Совет
Пример см. в разделе Подготовка деревьев принятия решений с помощью приложения Classification Learner.
Деревья классификации в Classification Learner используют fitctree функция. Можно задать следующие параметры:
Максимальное количество разбиений
Укажите максимальное количество точек разделения или ответвления для управления глубиной дерева. Когда вы выращиваете дерево решений, учитывайте его простоту и прогностическую силу. Чтобы изменить количество разделений, нажмите кнопки или введите положительное целое значение в поле Максимальное число разделений.
Тонкое дерево со множеством листьев обычно очень точно на тренировочных данных. Однако дерево может не показывать сопоставимую точность на независимом тестовом наборе. Листовое дерево имеет тенденцию перетренироваться, и его точность проверки часто намного ниже, чем точность обучения (или повторного замещения).
В противоположность этому грубое дерево не достигает высокой точности тренировки. Но грубое дерево может быть более надежным, поскольку его точность обучения может приблизиться к точности репрезентативного набора тестов. Кроме того, грубое дерево легко интерпретировать.
Критерий разделения
Укажите критерий разделения для принятия решения о том, когда разделять узлы. Попробуйте каждую из трех настроек, чтобы увидеть, улучшают ли они модель с вашими данными.
Опции критерия разделения: Gini's diversity index, Twoing rule, или Maximum deviance reduction (также известная как перекрестная энтропия).
Дерево классификации пытается оптимизировать до чистых узлов, содержащих только один класс. Индекс разнообразия Джини (по умолчанию) и примесь узла измерения критерия отклонения. Двоякое правило - это другая мера для решения, как разделить узел, где максимизация выражения двоякого правила увеличивает чистоту узла.
Подробные сведения об этих критериях разделения см. в разделе ClassificationTree
Подробнее.
Разделение суррогатного решения - только для отсутствующих данных.
Укажите использование суррогата для разделения решений. При наличии данных с отсутствующими значениями используйте суррогатные разделения для повышения точности прогнозов.
Если задано разделение суррогатного решения на Onдерево классификации находит не более 10 суррогатных разбиений в каждом узле ветви. Чтобы изменить число, нажмите кнопки или введите положительное целое значение в поле Максимальное количество суррогатов на узел.
Если задано разделение суррогатного решения на Find Allдерево классификации находит все суррогатные разделения в каждом узле ветви. Find All установка может использовать значительное время и память.
Можно также разрешить приложению автоматически выбирать некоторые из этих параметров модели с помощью оптимизации гиперпараметров. См. раздел Оптимизация гиперпараметров в приложении Classification Learner.
Дискриминантный анализ является популярным первым алгоритмом классификации, который нужно попробовать, потому что он быстрый, точный и простой в интерпретации. Дискриминантный анализ хорош для широких наборов данных.
Дискриминантный анализ предполагает, что различные классы генерируют данные на основе различных гауссовых распределений. Для обучения классификатора аппроксимирующая функция оценивает параметры гауссова распределения для каждого класса.
| Тип классификатора | Скорость прогнозирования | Использование памяти | Интерпретируемость | Гибкость модели |
|---|---|---|---|---|
| Линейный дискриминант | Быстро | Маленький | Легкий | Низко Создание линейных границ между классами. |
| Квадратичный дискриминант | Быстро | Большой | Легкий | Низко Создает нелинейные границы между классами (эллипс, парабола или гипербола). |
Дискриминантный анализ в Classification Learner использует fitcdiscr функция. Для линейных и квадратичных дискриминантов можно изменить опцию структуры ковариации. Если у вас есть предикторы с нулевой дисперсией или если какая-либо из ковариационных матриц ваших предикторов является сингулярной, обучение может завершиться неудачей, используя значение по умолчанию, Full ковариационная структура. Если обучение завершается неуспешно, выберите Diagonal вместо этого ковариационная структура.
Можно также разрешить приложению автоматически выбирать некоторые из этих параметров модели с помощью оптимизации гиперпараметров. См. раздел Оптимизация гиперпараметров в приложении Classification Learner.
Если у вас есть 2 класса, логистическая регрессия является популярным простым алгоритмом классификации, чтобы попытаться, потому что это легко интерпретировать. Классификатор моделирует вероятности классов как функцию линейной комбинации предикторов.
| Тип классификатора | Скорость прогнозирования | Использование памяти | Интерпретируемость | Гибкость модели |
|---|---|---|---|---|
| Логистическая регрессия | Быстро | Среда | Легкий | Низко Изменение параметров для управления гибкостью модели невозможно. |
Логистическая регрессия в Classification Learner использует fitglm функция. В приложении нельзя задать параметры этого классификатора.
Наивные байесовские классификаторы легко интерпретировать и полезны для мультиклассовой классификации. Наивный алгоритм Байеса использует теорему Байеса и делает предположение, что предикторы условно независимы, учитывая класс. Используйте эти классификаторы, если это предположение о независимости справедливо для предикторов в данных. Однако алгоритм все еще работает хорошо, когда предположение о независимости недействительно.
Для наивных классификаторов Bayes ядра можно управлять более плавным типом ядра с помощью параметра Kernel Type и управлять поддержкой плотности сглаживания ядра с помощью параметра Support.
| Тип классификатора | Скорость прогнозирования | Использование памяти | Интерпретируемость | Гибкость модели |
|---|---|---|---|---|
| Гауссов Наивный Байес | Среда Медленный для высокоразмерных данных | Маленький Носитель для высокоразмерных данных | Легкий | Низко Изменение параметров для управления гибкостью модели невозможно. |
| Кернел наивный Байес | Медленный | Среда | Легкий | Среда Можно изменить настройки типа ядра и поддержки, чтобы управлять тем, как классификатор моделирует распределения предикторов. |
Наивный Байес в классификации ученик использует fitcnb функция.
Для наивных классификаторов Байеса ядра можно задать следующие опции:
Тип ядра - укажите более плавный тип ядра. Попробуйте настроить каждую из этих опций, чтобы увидеть, улучшают ли они модель с вашими данными.
Параметры типа ядра: Gaussian, Box, Epanechnikov, или Triangle.
Поддержка - укажите поддержку плотности сглаживания ядра. Попробуйте настроить каждую из этих опций, чтобы увидеть, улучшают ли они модель с вашими данными.
Варианты поддержки: Unbounded (все реальные значения) или Positive (все положительные реальные значения).
Можно также разрешить приложению автоматически выбирать некоторые из этих параметров модели с помощью оптимизации гиперпараметров. См. раздел Оптимизация гиперпараметров в приложении Classification Learner.
Для получения дополнительной информации о моделях обучения см. раздел Модели классификации поездов в приложении Classification Learner App.
В Classification Learner можно обучать SVM, если данные имеют два или более класса.
| Тип классификатора | Скорость прогнозирования | Использование памяти | Интерпретируемость | Гибкость модели |
|---|---|---|---|---|
| Линейный SVM | Двоичный: Быстрый Мультикласс: Средний | Среда | Легкий | Низко Выполняет простое линейное разделение между классами. |
| Квадратичный SVM | Двоичный: Быстрый Мультикласс: Медленно | Двоичный: Средний Мультикласс: Большой | Трудно | Среда |
| Кубический SVM | Двоичный: Быстрый Мультикласс: Медленно | Двоичный: Средний Мультикласс: Большой | Трудно | Среда |
| Тонкий гауссов SVM | Двоичный: Быстрый Мультикласс: Медленно | Двоичный: Средний Мультикласс: Большой | Трудно | Высокий - уменьшается при установке масштаба ядра. Проводит детальное различие между классами, при этом для шкалы ядра установлено значение sqrt(P)/4. |
| Средний гауссов SVM | Двоичный: Быстрый Мультикласс: Медленно | Двоичный: Средний Мультикласс: Большой | Трудно | Среда Средние различия, для шкалы ядра установлено значение sqrt(P). |
| Крупный гауссов SVM | Двоичный: Быстрый Мультикласс: Медленно | Двоичный: Средний Мультикласс: Большой | Трудно | Низко Делает грубые различия между классами, при этом для шкалы ядра установлено значение sqrt(P)*4, где P - количество предикторов. |
Совет
Попробуйте обучить каждую из неоптимизируемых опций машины вектора поддержки в галерее Тип модели. Обучите их всем, чтобы увидеть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models). Чтобы попытаться улучшить модель, попробуйте выбрать элемент, а затем изменить некоторые дополнительные параметры.
SVM классифицирует данные, находя лучшую гиперплоскость, которая отделяет точки данных одного класса от точек данных другого класса. Лучшая гиперплоскость для SVM означает гиперплоскость с наибольшим запасом между двумя классами. Поле означает максимальную ширину перекрытия, параллельного гиперплоскости, не имеющей внутренних точек данных.
Векторы поддержки являются точками данных, ближайшими к разделительной гиперплоскости; эти точки находятся на границе перекрытия. На следующем рисунке показаны эти определения с + указывающими точками данных типа 1 и - указывающими точками данных типа -1.
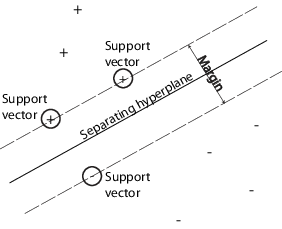
SVM также могут использовать мягкое поле, что означает гиперплоскость, разделяющую многие, но не все точки данных.
Пример см. в разделе Подготовка векторных машин поддержки с помощью приложения Classification Learner App.
Если у вас ровно два класса, Classification Learner использует fitcsvm функция для обучения классификатора. Если у вас более двух классов, приложение использует fitcecoc функция для уменьшения проблемы классификации мультиклассов до набора двоичных подпроблем классификации с одним учеником SVM для каждой подпроблемы. Чтобы проверить код для двоичных и мультиклассовых типов классификаторов, можно создать код из обученных классификаторов в приложении.
В приложении можно задать следующие параметры:
Функция ядра
Укажите функцию Kernel для вычисления классификатора.
Линейное ядро, легче всего интерпретировать
Ядро гауссовой или радиальной базовой функции (RBF)
Квадратный
Кубический
Уровень ограничения прямоугольника
Задайте ограничение поля, чтобы сохранить допустимые значения множителей Лагранжа в поле, ограниченной области.
Чтобы настроить классификатор SVM, попробуйте увеличить уровень ограничения поля. Нажмите кнопки или введите положительное скалярное значение в поле Уровень ограничения бокса (Box constraint level). Увеличение уровня ограничения поля может уменьшить число векторов поддержки, но также может увеличить время обучения.
Параметр Box Constraint представляет собой штраф мягкой границы, известный как C в первичных уравнениях, и является жестким ограничением «box» в двойственных уравнениях.
Режим масштабирования ядра
При необходимости укажите масштабирование ядра вручную.
При установке для режима масштаба ядра значения Autoзатем программа использует эвристическую процедуру для выбора значения масштаба. Эвристическая процедура использует субдискретизацию. Поэтому для воспроизведения результатов установите начальное число случайного числа, используя rng перед обучением классификатора.
При установке для режима масштаба ядра значения Manual, можно указать значение. Нажмите кнопки или введите положительное скалярное значение в поле Масштаб ядра вручную. Программное обеспечение делит все элементы матрицы предиктора на значение шкалы ядра. Затем программное обеспечение применяет соответствующую норму ядра для вычисления матрицы Gram.
Совет
Гибкость модели уменьшается с настройкой масштаба ядра.
Многоклассовый метод
Только для данных с 3 или более классами. Этот метод сводит проблему мультиклассовой классификации к набору двоичных подпроблем классификации с одним учеником SVM для каждой подпроблемы. One-vs-One обучает по одному ученику для каждой пары классов. Учится отличать один класс от другого. One-vs-All обучает по одному ученику для каждого класса. Учится отличать один класс от всех остальных.
Стандартизация данных
Укажите, следует ли масштабировать каждое координатное расстояние. Если предикторы имеют широко различные масштабы, стандартизация может улучшить подгонку.
Можно также разрешить приложению автоматически выбирать некоторые из этих параметров модели с помощью оптимизации гиперпараметров. См. раздел Оптимизация гиперпараметров в приложении Classification Learner.
Ближайшие соседние классификаторы обычно имеют хорошую точность прогнозирования в малых измерениях, но могут не иметь высоких измерений. Они имеют высокое использование памяти, и их нелегко интерпретировать.
Совет
Гибкость модели уменьшается с параметром Количество соседей (Number of neighbors).
| Тип классификатора | Скорость прогнозирования | Использование памяти | Интерпретируемость | Гибкость модели |
|---|---|---|---|---|
| Тонкая КНН | Среда | Среда | Трудно | Тонко детализированные различия между классами. Число соседей равно 1. |
| Среднее KNN | Среда | Среда | Трудно | Средние различия между классами. Число соседей устанавливается равным 10. |
| Грубый KNN | Среда | Среда | Трудно | Грубые различия между классами. Количество соседей устанавливается равным 100. |
| Косинус KNN | Среда | Среда | Трудно | Средние различия между классами с использованием метрики расстояния косинуса. Число соседей устанавливается равным 10. |
| Кубический KNN | Медленный | Среда | Трудно | Средние различия между классами с использованием кубической метрики расстояния. Число соседей устанавливается равным 10. |
| Взвешенный KNN | Среда | Среда | Трудно | Средние различия между классами с использованием веса расстояния. Число соседей устанавливается равным 10. |
Совет
Попробуйте обучить каждую из неоптимизируемых опций ближайшего соседа в галерее Тип модели (Model Type). Обучите их всем, чтобы увидеть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models). Чтобы попытаться улучшить модель, попробуйте выбрать элемент, а затем (дополнительно) попробуйте изменить некоторые дополнительные опции.
Что такое k-ближайшая соседняя классификация? Категоризация точек запроса на основе их расстояния до точек (или соседей) в обучающем наборе данных может быть простым, но эффективным способом классификации новых точек. Для определения расстояния можно использовать различные метрики. Учитывая набор X из n точек и функцию расстояния, поиск k-ближайшего соседа (kNN) позволяет найти k ближайших точек в X к точке запроса или набору точек. Алгоритмы на основе kNN широко используются в качестве эталонных правил машинного обучения.
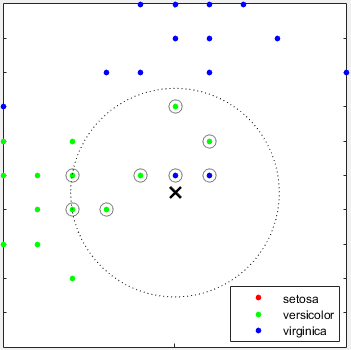
Пример см. в разделе Обучение классификаторов ближайших соседей с помощью приложения Classification Learner App.
Ближайшие классификаторы соседей в Classification Learner используют fitcknn функция. Можно задать следующие параметры:
Число соседей
Укажите число ближайших соседей для классификации каждой точки при прогнозировании. Укажите мелкий (низкий номер) или грубый классификатор (высокий номер), изменив число соседей. Например, точное KNN использует одного соседа, а грубое KNN использует 100. Многие соседи могут занять много времени.
Метрика расстояния
Для определения расстояния до точек можно использовать различные метрики. Определения см. в описании класса ClassificationKNN.
Вес дистанции
Укажите функцию взвешивания расстояния. Вы можете выбрать Equal (без весов), Inverse (вес равен 1/расстояние), или Squared Inverse (вес - 1/дистанцие2).
Стандартизация данных
Укажите, следует ли масштабировать каждое координатное расстояние. Если предикторы имеют широко различные масштабы, стандартизация может улучшить подгонку.
Можно также разрешить приложению автоматически выбирать некоторые из этих параметров модели с помощью оптимизации гиперпараметров. См. раздел Оптимизация гиперпараметров в приложении Classification Learner.
Классификаторы ансамблей слили результаты от многих слабых учеников в одну качественную модель ансамбля. Качества зависят от выбора алгоритма.
Совет
Гибкость модели увеличивается с параметром Количество обучающихся.
Все классификаторы ансамблей, как правило, медленно подходят, потому что им часто нужно много учеников.
| Тип классификатора | Скорость прогнозирования | Использование памяти | Интерпретируемость | Метод ансамбля | Гибкость модели |
|---|---|---|---|---|---|
| Усиленные деревья | Быстро | Низко | Трудно | AdaBoost, с Decision Tree ученики | Среднее или высокое - увеличивается с помощью параметра Количество учащихся или Максимальное количество разделений.
Совет Улучшенные деревья обычно могут работать лучше, чем пакетированные, но могут потребовать настройки параметров и большего количества учеников
|
| Фасованные деревья | Среда | Высоко | Трудно | Случайный лесBag, с Decision Tree ученики | High - увеличивается с установкой количества обучающихся.
Совет Сначала попробуйте использовать этот классификатор.
|
| Дискриминант подпространства | Среда | Низко | Трудно | Subspace, с Discriminant ученики | Средний - увеличивается с настройкой Количество обучающихся. Хорошо для многих предикторов |
| Подпространство KNN | Среда | Среда | Трудно | Subspace, с Nearest Neighbor ученики | Средний - увеличивается с настройкой Количество обучающихся. Хорошо для многих предикторов |
| Деревья RUSBoost | Быстро | Низко | Трудно | RUSBoost, с Decision Tree ученики | Среднее - увеличивается с помощью параметра Количество учащихся или Максимальное количество разделений. Хорошо подходит для искаженных данных (с большим количеством наблюдений 1 класса) |
| GentleBoost или LogitBoost - недоступны в коллекции типов моделей. При наличии данных 2 классов выберите вручную. | Быстро | Низко | Трудно | GentleBoost или LogitBoost, с Decision Tree ученикиВыбирать Boosted Trees и изменить на GentleBoost способ. | Среднее - увеличивается с помощью параметра Количество учащихся или Максимальное количество разделений. Только для двоичной классификации |
Фасованные деревья используют Breiman's 'random forest' алгоритм. Для справки см. Breiman, L. Random Forests. Машинное обучение 45, стр. 5-32, 2001.
Совет
Сначала попробуйте фасованные деревья. Усиленные деревья обычно могут работать лучше, но могут потребовать поиска многих значений параметров, что занимает много времени.
Попробуйте обучить каждую из неоптимизируемых опций классификатора ансамбля в галерее Тип модели (Model Type). Обучите их всем, чтобы увидеть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models). Чтобы попытаться улучшить модель, попробуйте выбрать элемент, PCA, а затем (дополнительно) попробуйте изменить некоторые дополнительные опции.
Для повышения ансамблевых методов можно получить тонкую детализацию с более глубокими деревьями или большим количеством мелководных деревьев. Как и в случае классификаторов отдельных деревьев, глубокие деревья могут вызвать переоборудование. Нужно поэкспериментировать, чтобы выбрать лучшую глубину дерева для деревьев в ансамбле, чтобы скомпоновать данные, вписывающиеся в сложность дерева. Используйте параметры Количество обучающихся и Максимальное количество разделений.
Пример см. в разделе Классификаторы составов поездов с помощью приложения Classification Learner.
Классификаторы ансамблей в Classification Learner используют fitcensemble функция. Можно задать следующие параметры:
Для получения справки по выбору метода Ensemble и типа учащегося см. таблицу Ensemble. Сначала попробуйте использовать стили.
Максимальное количество разбиений
Для усиления методов ансамбля укажите максимальное количество разделений или точек ответвления для управления глубиной обучающихся на дереве. Многие ветви, как правило, перегружаются, и более простые деревья могут быть более надежными и легко интерпретировать. Эксперимент по выбору лучшей глубины дерева для деревьев в ансамбле.
Число обучающихся
Попробуйте изменить число обучающихся, чтобы узнать, можно ли улучшить модель. Многие ученики могут производить высокую точность, но это может занять много времени. Начните с нескольких десятков учеников, а затем проверьте производительность. Ансамбль с хорошей прогностической силой может нуждаться в нескольких сотнях учеников.
Уровень обучения
Укажите скорость обучения для усадки. Если установить скорость обучения меньше 1, ансамбль требует больше итераций обучения, но часто достигает лучшей точности. 0,1 - популярный выбор.
Измерение подпространства
Для ансамблей подпространства укажите количество предикторов для выборки у каждого учащегося. Приложение выбирает случайное подмножество предикторов для каждого учащегося. Подмножества, выбранные разными учениками, независимы.
Можно также разрешить приложению автоматически выбирать некоторые из этих параметров модели с помощью оптимизации гиперпараметров. См. раздел Оптимизация гиперпараметров в приложении Classification Learner.
Модели нейронных сетей обычно имеют хорошую точность прогнозирования и могут использоваться для мультиклассовой классификации; однако их нелегко интерпретировать.
Гибкость модели увеличивается с размером и количеством полностью соединенных слоев в нейронной сети.
Совет
В галерее Тип модели (Model Type) щелкните Все нейронные сети (All Neural Networks
), чтобы попробовать каждый из![]() предустановленных параметров нейронной сети и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
предустановленных параметров нейронной сети и посмотреть, какие настройки создают лучшую модель с вашими данными. Выберите лучшую модель на панели Модели (Models) и попробуйте улучшить эту модель с помощью выбора элемента и изменения некоторых дополнительных опций.
| Тип классификатора | Скорость прогнозирования | Использование памяти | Интерпретируемость | Гибкость модели |
|---|---|---|---|---|
| Узкая нейронная сеть | Быстро | Среда | Трудно | Средний - увеличивается с размером каждого полностью подключенного слоя |
| Средненейронная сеть | Быстро | Среда | Трудно | Средний - увеличивается с размером каждого полностью подключенного слоя |
| Широкая нейронная сеть | Быстро | Среда | Трудно | Средний - увеличивается с размером каждого полностью подключенного слоя |
| Билайерная нейронная сеть | Быстро | Среда | Трудно | Высокий - увеличивается с размером каждого полностью подключенного слоя |
| Трилайерная нейронная сеть | Быстро | Среда | Трудно | Высокий - увеличивается с размером каждого полностью подключенного слоя |
Каждая модель является прямой, полностью связанной нейронной сетью для классификации. Первый полностью связанный уровень нейронной сети имеет соединение от сетевого входа (данные предиктора), а каждый последующий уровень имеет соединение от предыдущего уровня. Каждый полностью связанный слой умножает входной сигнал на весовую матрицу и затем добавляет вектор смещения. За каждым полностью подключенным уровнем следует функция активации. Конечный полностью подключенный уровень и последующая функция активации softmax дают выход сети, а именно оценки классификации (апостериорные вероятности) и предсказанные метки. Дополнительные сведения см. в разделе Структура нейронной сети.
Пример см. в разделе Подготовка классификаторов нейронных сетей с помощью приложения Classification Learner App.
Классификаторы нейронных сетей в Classification Learner используют fitcnet функция. Можно задать следующие параметры:
Количество полностью соединенных слоев - количество полностью соединенных слоев в нейронной сети, исключая конечный полностью связанный слой для классификации. Можно выбрать максимум три полностью соединенных слоя.
Размер каждого полностью подключенного слоя - укажите размер каждого полностью подключенного слоя, исключая конечный полностью подключенный слой. Если выбрана нейронная сеть с несколькими полностью соединенными слоями, попробуйте задать слои с уменьшающимися размерами.
Активация (Activation) - указывает функцию активации для всех полностью подключенных слоев, исключая конечный полностью подключенный слой. Функция активации для последнего полностью подключенного уровня всегда является softmax. Выберите из следующих функций активации: ReLU, Tanh, Sigmoid, и None.
Предел итерации - укажите максимальное количество итераций обучения.
Сила термина «регуляризация» - укажите срок штрафа за регуляризацию гребня (L2).
Стандартизировать данные - укажите, следует ли стандартизировать числовые предикторы. Если предикторы имеют широко различные масштабы, стандартизация может улучшить подгонку. Настоятельно рекомендуется стандартизировать данные.
