После обучения классификаторов в Classification Learner можно сравнивать модели на основе показателей точности, визуализировать результаты путем построения прогнозов классов и проверять производительность с помощью матрицы путаницы и кривой ROC.
Если вы используете k-кратную перекрестную проверку, то приложение вычисляет оценки точности, используя наблюдения в k складках проверки и сообщает о средней ошибке перекрестной проверки. Он также делает прогнозы по наблюдениям в этих валидационных складках и вычисляет матрицу путаницы и кривую ROC на основе этих прогнозов.
Примечание
При импорте данных в приложение, если вы принимаете значения по умолчанию, приложение автоматически использует перекрестную проверку. Дополнительные сведения см. в разделе Выбор схемы проверки.
Если вы используете проверку на удержание, приложение вычисляет оценки точности, используя наблюдения в валидации, и делает прогнозы по этим наблюдениям. Приложение также вычисляет матрицу путаницы и кривую ROC на основе этих прогнозов.
Если используется проверка повторного замещения, оценка представляет собой точность повторного замещения на основе всех данных обучения, а прогнозы представляют собой прогнозы повторного замещения.
После обучения модели в Classification Learner проверьте панель Модели, чтобы узнать, какая модель имеет лучшую общую точность в процентах. Наилучший показатель точности (проверки) выделен в рамке. Эта оценка является точностью проверки. Оценка точности проверки оценивает производительность модели на новых данных по сравнению с данными обучения. Используйте оценку, чтобы выбрать лучшую модель.
Для перекрестной проверки оценка представляет собой точность всех наблюдений, считая каждое наблюдение, когда оно находилось в задержанном (валидационном) масштабе.
Для проверки отсутствия оценки оценка является точностью по задержанным наблюдениям.
Для проверки повторной субституции оценка представляет собой точность повторной субституции по сравнению со всеми наблюдениями обучающих данных.
Лучший общий балл может быть не лучшей моделью для вашего гола. Модель с немного меньшей общей точностью может быть лучшим классификатором для вашей цели. Например, ложные срабатывания в определенном классе могут быть важны для вас. Возможно, потребуется исключить некоторые предикторы, для которых сбор данных является дорогостоящим или затруднительным.
Чтобы узнать, как классификатор работал в каждом классе, изучите матрицу путаницы.
Можно просмотреть метрики модели на панели Сводка текущей модели (Current Model Summary) и использовать эти метрики для оценки и сравнения моделей. Метрики результатов обучения рассчитываются на наборе проверки. Метрики Результаты тестирования (Test Results), если они отображаются, рассчитываются на импортированном наборе тестов. Дополнительные сведения см. в разделе Оценка производительности модели тестового набора.
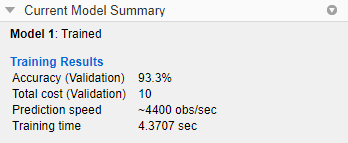
Чтобы скопировать информацию на панели Сводка текущей модели (Current Model Summary), можно щелкнуть правой кнопкой мыши на панели и выбрать Копировать текст (Copy text).
Метрики модели
| Метрика | Описание | Совет |
|---|---|---|
| Точность | Процент правильно классифицированных наблюдений | Ищите большие значения точности. |
| Общая стоимость | Общая стоимость неправильной классификации | Найдите меньшие значения общих затрат. Убедитесь, что значение точности по-прежнему велико. |
Можно сортировать модели по различным метрикам модели. Чтобы выбрать метрику для сортировки модели, используйте список Сортировать по (Sort by) в верхней части панели Модели (Models).
Можно также удалить нежелательные модели, перечисленные на панели Модели (Models). Выберите модель, которую требуется удалить, и нажмите кнопку Удалить выбранную модель (Delete selected model) в верхней правой части панели или щелкните модель правой кнопкой мыши и выберите Удалить модель (Delete model). Нельзя удалить последнюю оставшуюся модель на панели Модели (Models).
На графике разброса просмотрите результаты классификатора. После обучения классификатора график рассеяния переключается с отображения данных на отображение прогнозов модели. Если вы используете удержание или перекрестную проверку, то эти прогнозы являются прогнозами по задержанным (проверке) наблюдениям. Другими словами, каждый прогноз получают с использованием модели, которая была обучена без использования соответствующего наблюдения. Чтобы исследовать результаты, используйте элементы управления справа. Вы можете:
Выберите, следует ли выводить на печать прогнозы модели или только данные.
Отображение или скрытие правильных или неправильных результатов с помощью флажков в разделе Прогнозы модели (Model predictions).
Выберите элементы для печати с помощью списков X и Y в разделе Предикторы.
Визуализируйте результаты по классам, показывая или скрывая определенные классы с помощью флажков в разделе Показать.
Измените порядок размещения классов на графике, выбрав класс в разделе «Классы» и нажав «Переместить на передний план».
Увеличьте и уменьшите изображение или выполните панорамирование на графике. Чтобы включить масштабирование или панорамирование, наведите курсор мыши на график рассеяния и нажмите соответствующую кнопку на панели инструментов, которая отображается над правой верхней частью графика.
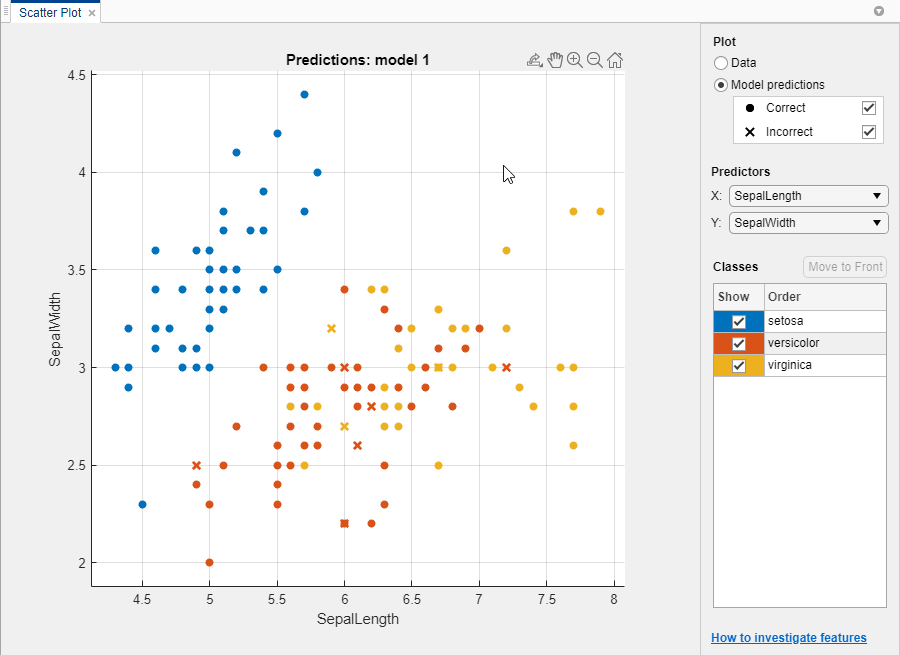
См. также раздел Исследование элементов на графике рассеяния.
Чтобы экспортировать растровые графики, созданные в приложении, в фигуры, см. раздел Экспорт графиков в приложении Classification Learner App.
Используйте график матрицы путаницы, чтобы понять, как выбранный в данный момент классификатор работает в каждом классе. Чтобы просмотреть матрицу путаницы после обучения модели, нажмите «Матрица путаницы» и выберите «Данные проверки» в разделе «Графики» вкладки «Классификатор». Матрица путаницы помогает определить области, в которых классификатор работает плохо.
При открытии графика строки показывают истинный класс, а столбцы - прогнозируемый класс. Если используется удержание или перекрестная проверка, матрица путаницы вычисляется с использованием прогнозов по задержанным (проверке) наблюдениям. Диагональные ячейки показывают, где совпадают истинный класс и прогнозируемый класс. Если эти диагональные ячейки голубые, классификатор классифицирует наблюдения этого истинного класса правильно классифицируется.
В представлении по умолчанию отображается количество наблюдений в каждой ячейке.
Чтобы увидеть, как классификатор выполняется для класса, в разделе График выберите опцию Истинные положительные ставки (TPR), Ложные отрицательные ставки (FNR). TPR - это доля правильно классифицированных наблюдений по истинному классу. FNR - это доля неправильно классифицированных наблюдений на истинный класс. На графике в двух последних столбцах справа показаны сводки по истинным классам.
Совет
Ищите области, где классификатор работает плохо, исследуя клетки с диагонали, которые показывают высокие проценты и оранжевые. Чем выше процент, тем темнее оттенок цвета ячейки. В этих оранжевых ячейках истинный класс и прогнозируемый класс не совпадают. Точки данных имеют неправильную классификацию.
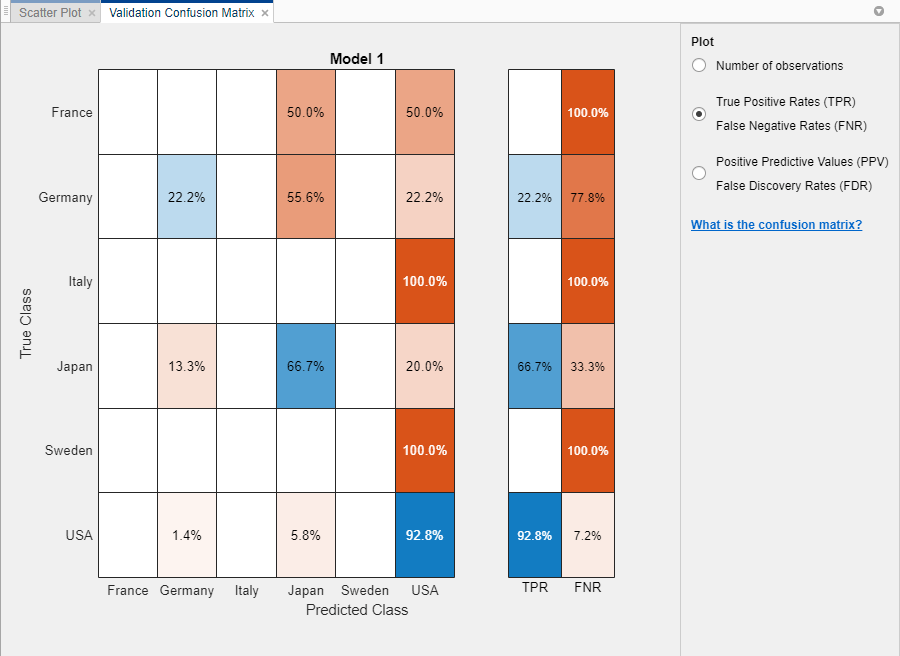
В этом примере используется carsmall набор данных, вторая строка сверху показывает все автомобили с истинным классом Германия. В столбцах отображаются прогнозируемые классы. 22,2% автомобилей из Германии правильно классифицированы, поэтому 22,2% - это истинный положительный показатель для правильно классифицированных точек этого класса, показанный в синей ячейке в столбце TPR.
Остальные автомобили в ряду «Германия» неправильно классифицированы: 55,6% автомобилей неправильно классифицированы как из Японии, а 22,2% - как из США. Ложноотрицательная ставка для неправильно классифицированных баллов этого класса составляет 77,8%, показанная в оранжевой ячейке в столбце FNR.
Если вы хотите увидеть количество наблюдений (автомобилей, в этом примере) вместо процентов, в разделе График (Plot) выберите Количество наблюдений (Number of observations).
Если в задаче классификации важны ложные положительные результаты, постройте график результатов для прогнозируемого класса (вместо истинного класса), чтобы исследовать частоту ложных обнаружений. Чтобы увидеть результаты для прогнозируемого класса, в разделе График выберите параметр Положительные прогнозируемые значения (PPV), Ложные скорости обнаружения (FDR). PPV - это доля правильно классифицированных наблюдений на прогнозируемый класс. FDR - это доля неправильно классифицированных наблюдений на прогнозируемый класс. Если этот параметр выбран, матрица путаницы теперь включает сводные строки под таблицей. Положительные прогностические значения показаны синим цветом для правильно предсказанных точек в каждом классе, а ложные показатели обнаружения показаны оранжевым цветом для неправильно предсказанных точек в каждом классе.
Если вы решили, что в интересующих классах слишком много точек с неправильной классификацией, попробуйте изменить настройки классификатора или выбрать элемент для поиска лучшей модели.
Чтобы экспортировать графики матрицы путаницы, созданные в приложении, в фигуры, см. раздел Экспорт графиков в приложении Classification Learner App.
Чтобы просмотреть ROC-кривую после обучения модели, на вкладке Ученик по классификации (Classification Learner) в разделе Графики (Plots) щелкните ROC-кривая (ROC Curve) и выберите Данные проверки (Validation Data). Просмотрите кривую рабочей характеристики приемника (ROC), показывающую истинную и ложноположительную скорости. Кривая ROC показывает истинную положительную скорость в сравнении с ложноположительной скоростью для выбранного в настоящее время обученного классификатора. Можно выбрать различные классы для печати.
Маркер на графике показывает производительность выбранного в данный момент классификатора. Маркер показывает значения ложноположительной скорости (FPR) и истинной положительной скорости (TPR) для выбранного в данный момент классификатора. Например, ложноположительный коэффициент (FPR) 0,2 указывает на то, что текущий классификатор присваивает 20% наблюдений неверно положительному классу. Истинный положительный коэффициент 0,9 указывает на то, что текущий классификатор правильно присваивает 90% наблюдений положительному классу.
Идеальным результатом без неправильной классификации точек является правый угол в верхнем левом углу графика. Плохой результат, который не лучше случайного, - это линия при 45 градусах. Число «Площадь под кривой» является показателем общего качества классификатора. Значения параметра «Большая площадь под кривой» указывают на лучшую производительность классификатора. Сравните классы и обученные модели, чтобы увидеть, работают ли они по-разному в кривой ROC.
Дополнительные сведения см. в разделе perfcurve.
Чтобы экспортировать графики кривой ROC, созданные в приложении, в фигуры, см. раздел Экспорт графиков в приложении Classification Learner App.
После обучения модели в Classification Learner можно оценить производительность модели на наборе тестов в приложении. Этот процесс позволяет проверить, обеспечивает ли точность проверки хорошую оценку производительности модели на новых данных.
Импорт набора тестовых данных в Classification Learner.
Если набор тестовых данных находится в рабочей области MATLAB ®, то в разделе Тестирование на вкладке Классификатор щелкните Тестовые данные и выберите Из рабочей области.
Если набор тестовых данных находится в файле, то в разделе Тестирование щелкните Тестовые данные и выберите Из файла. Выберите тип файла в списке, например электронную таблицу, текстовый файл или разделенные запятыми значения (.csv) файл или выберите «Все файлы» для поиска других типов файлов, таких как .dat.
В диалоговом окне Import Test Data выберите набор тестовых данных из списка Test Data Set Variable. Набор тестов должен иметь те же переменные, что и предикторы, импортированные для обучения и проверки. Уникальные значения в переменной ответа теста должны быть подмножеством классов в переменной полного ответа.
Вычислите метрики тестового набора.
Чтобы вычислить метрики теста для одной модели, выберите обученную модель на панели Модели (Models). На вкладке Classification Learner в разделе Testing нажмите Test All и выберите Test Selected.
Чтобы вычислить метрики теста для всех обученных моделей, щелкните Проверить все (Test All) и выберите Проверить все (Test All) в разделе Тестирование (Testing).
Приложение вычисляет производительность тестового набора каждой модели, обученной на полном наборе данных, включая данные обучения и проверки.
Сравните точность проверки с точностью теста.
На панели Сводка по текущей модели приложение отображает метрики проверки и показатели тестирования в разделах Результаты обучения и Результаты тестирования соответственно. Можно проверить, дает ли точность проверки хорошую оценку точности теста.
Можно также визуализировать результаты теста с помощью графиков.
Отображение матрицы путаницы. В разделе «Графики» на вкладке «Классификатор» нажмите «Матрица путаницы» и выберите «Тестовые данные».
Отображение кривой ROC. В разделе Графики (Plots) щелкните ROC Кривая (ROC Curve) и выберите Тестовые данные (Test Data).
Пример см. в разделе Проверка производительности классификатора с помощью тестового набора в приложении Classification Learner App. Пример использования метрик тестового набора в рабочем процессе оптимизации гиперпараметров см. в разделе Использование гиперпараметрового классификационного классификатора в приложении Classification Learner.
