Этот пример показывает, как преобразовать алгоритм с плавающей точкой в фиксированную точку, а затем сгенерировать код С для алгоритма. В примере используются следующие лучшие практики:
Отделите алгоритм от тестового файла.
Подготовьте свой алгоритм для инструментирования и генерации кода.
Управляйте типами данных и управляйте ростом разрядности.
Отделите определения типов данных от алгоритмического кода путем создания таблицы описаний данных.
Полный список передовых практик см. в Руководстве по преобразованию с фиксированной точкой Лучшие практики.
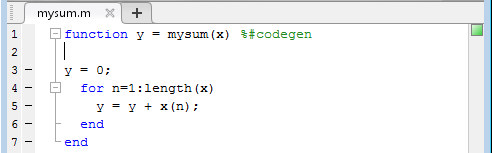
Написание MATLAB® функция, mysum, который суммирует элементы массива вектора.
function y = mysum(x) y = 0; for n = 1:length(x) y = y + x(n); end end
Поскольку вам нужно только преобразовать алгоритмический фрагмент в фиксированную точку, более эффективно структурировать ваш код так, чтобы алгоритм, в котором вы делаете обработку ядра, был отделен от тестового файла.
В тестовом файле создайте ваши входы, вызовите алгоритм и постройте график результатов.
Написание скрипта MATLAB, mysum_test, который проверяет поведение вашего алгоритма с помощью двойных типов данных.
n = 10; rng default x = 2*rand(n,1)-1; % Algorithm y = mysum(x); % Verify results y_expected = sum(double(x)); err = double(y) - y_expected
rng default помещает настройки генератора случайных чисел, используемого функцией rand, в значение по умолчанию, так что он выдает те же случайные числа, как если бы вы перезапустили MATLAB.
Запустите тестовый скрипт.
mysum_test
err =
0Результаты, полученные с помощью mysum совпадают с полученными с помощью MATLAB sum функция.
Для получения дополнительной информации см. Раздел «Создание тестового файла»
В вашем алгоритме после подписи функции добавьте %#codegen директива компиляции, чтобы указать, что вы намерены инструментализировать алгоритм и сгенерировать Код С для него. Добавление этой директивы предписывает анализатору кода MATLAB помочь вам диагностировать и исправить нарушения, которые привели бы к ошибкам во время инструментирования и генерации кода.
function y = mysum(x) %#codegen y = 0; for n = 1:length(x) y = y + x(n); end end
Для этого алгоритма индикатор анализатора кода в правом верхнем углу окна редактора остается зеленым, что говорит вам, что он не обнаружил никаких проблем.
Для получения дополнительной информации смотрите Подготовим Алгоритм для Ускорения Кода или Генерации Кода.
Сгенерируйте код С для исходного алгоритма, чтобы убедиться, что алгоритм подходит для генерации кода, и увидеть код С с плавающей точкой. Используйте codegen (MATLAB Coder) функция (требует MATLAB Coder™) для генерации библиотеки на C.
Добавьте следующую линию в конец тестового скрипта, чтобы сгенерировать код С для mysum.
codegen mysum -args {x} -config:lib -report
Еще раз запустите тестовый скрипт.
MATLAB Coder генерирует код С для mysum и предоставляет ссылку на отчет генерации кода.
Щелкните ссылку, чтобы открыть отчет генерации кода и просмотреть сгенерированный код C для mysum.
/* Function Definitions */
double mysum(const double x[10])
{
double y;
int n;
y = 0.0;
for (n = 0; n < 10; n++) {
y += x[n];
}
return y;
}Поскольку C не разрешает индексы с плавающей точкой, счетчик цикла n, автоматически объявляется как целый тип. Вам не нужно преобразовывать n в фиксированную точку.
Входные x и выход y объявлены как double.
Протестируйте алгоритм с синглами, чтобы проверить несоответствия типов
Измените свой тестовый файл так, чтобы тип данных x является одиночным.
n = 10; rng default x = single(2*rand(n,1)-1); % Algorithm y = mysum(x); % Verify results y_expected = sum(double(x)); err = double(y) - y_expected codegen mysum -args {x} -config:lib -report
Еще раз запустите тестовый скрипт.
mysum_test
err = -4.4703e-08 ??? This assignment writes a 'single' value into a 'double' type. Code generation does not support changing types through assignment. Check preceding assignments or input type specifications for type mismatches.
Генерация кода прекращается, сообщается о несоответствии типа данных в линии y = y + x(n);.
Чтобы просмотреть ошибку, откройте отчет.
В докладе о линии y = y + x(n), в отчете освещается y на левой стороне назначения красным цветом, что указывает на наличие ошибки. Проблема в том, что y объявляется как двойной, но назначается синглу. y + x(n) - сумма двойки и сингла, которая является синглом. При наведении курсора на переменные и выражения в отчете можно увидеть информацию об их типах. Здесь видно, что выражение, y + x(n) является синглом.

Чтобы исправить несоответствие типов, обновите алгоритм, используя подписанное назначение для суммы элементов. Изменение y = y + x(n) на y(:) = y + x(n).
function y = mysum(x) %#codegen y = 0; for n = 1:length(x) y(:) = y + x(n); end end
Используя подписанное назначение, вы также препятствуете росту разрядности, которое является поведением по умолчанию при добавлении номеров с фиксированной точкой. Для получения дополнительной информации смотрите Рост разрядности. Предотвращение роста разрядности важно, потому что вы хотите поддерживать свои фиксированные точки во всем коде. Для получения дополнительной информации смотрите Управление Ростом разрядности.
Перегенерируйте код С и откройте отчет генерации кода. В коде С результат теперь приведен к удвоению, чтобы устранить несоответствие типов.
Используйте buildInstrumentedMex функция для измерения вашего алгоритма для логгирования минимальных и максимальных значений всех именованных и промежуточных переменных. Используйте showInstrumentationResults функция для предложения типов данных с фиксированной точкой на основе этих записанных значений. Позже вы используете эти предлагаемые фиксированные точки, чтобы протестировать свой алгоритм.
Обновите тестовый скрипт:
После того, как вы объявите n, добавить buildInstrumentedMex mySum —args {zeros(n,1)} -histogram.
Изменение x назад к double. Замените x = single(2*rand(n,1)-1); с x = 2*rand(n,1)-1;
Вместо вызова исходного алгоритма вызовите сгенерированную MEX-функцию. Изменение y = mysum(x) на y=mysum_mex(x).
После вызова MEX-функции добавьте showInstrumentationResults mysum_mex -defaultDT numerictype(1,16) -proposeFL. The -defaultDT numerictype(1,16) -proposeFL флаги указывают, что вы хотите предложить длины дробей для 16-битного размера слова.
Вот обновленный тестовый скрипт.
%% Build instrumented mex n = 10; buildInstrumentedMex mysum -args {zeros(n,1)} -histogram %% Test inputs rng default x = 2*rand(n,1)-1; % Algorithm y = mysum_mex(x); % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x} -config:lib -report
Еще раз запустите тестовый скрипт.
showInstrumentationResults функция предлагает типы данных и открывает отчет для отображения результатов.
В отчете щелкните вкладку Variables. showInstrumentationResults предлагает длину дроби 13 для y и 15 для x.

В отчете можно:
Просмотрите минимальное и максимальное значения симуляции для входа x и выход y.
Просмотрите предложенные типы данных для x и y.
Просмотрите информацию для всех переменных, промежуточных результатов и выражений в коде.
Чтобы просмотреть эту информацию, наведите курсор на переменную или выражение в отчете.
Смотрите данные гистограммы для x и y чтобы помочь вам идентифицировать любые значения, которые находятся вне области значений или ниже точности на основе текущего типа данных.
Чтобы просмотреть гистограмму для конкретной переменной, щелкните значок ее гистограммы,.![]()
Вместо того, чтобы вручную изменять алгоритм, чтобы исследовать поведение для каждого типа данных, отделите определения типов данных от алгоритма.
Изменение mysum так, что он принимает параметр входа, T, которая является структурой, которая определяет типы данных входных и выходных данных. Когда y сначала определяется, используйте cast функция, подобная синтаксису - cast(x,'like',y) - бросить x к требуемому типу данных.
function y = mysum(x,T) %#codegen y = cast(0,'like',T.y); for n = 1:length(x) y(:) = y + x(n); end end
Написание функции, mytypes, который определяет различные типы данных, которые вы хотите использовать, чтобы протестировать ваш алгоритм. В таблице типов данных включены типы двойных, одинарных и масштабированных двойных данных, а также типы данных с фиксированной точкой, предложенные ранее. Перед преобразованием вашего алгоритма в фиксированную точку рекомендуется:
Протестируйте соединение между таблицей определения типов и вашим алгоритмом с помощью doubles.
Протестируйте алгоритм с синглами, чтобы найти несоответствия типов данных и другие проблемы.
Запустите алгоритм, используя масштабированные двойки, чтобы проверить на переполнения.
function T = mytypes(dt) switch dt case 'double' T.x = double([]); T.y = double([]); case 'single' T.x = single([]); T.y = single([]); case 'fixed' T.x = fi([],true,16,15); T.y = fi([],true,16,13); case 'scaled' T.x = fi([],true,16,15,... 'DataType','ScaledDouble'); T.y = fi([],true,16,13,... 'DataType','ScaledDouble'); end end
Для получения дополнительной информации смотрите Отдельные определения типов данных из алгоритма.
Обновите тестовый скрипт, mysum_test, для использования таблицы типов.
Для первого запуска проверьте соединение между таблицей и алгоритмом с помощью doubles. Прежде чем вы объявите n, добавить T = mytypes('double');
Обновите вызов на buildInstrumentedMex для использования типа T.x заданные в таблице типов данных: buildInstrumentedMex mysum -args {zeros(n,1,'like',T.x),T} -histogram
Приведение x для использования типа T.x заданные в таблице: x = cast(2*rand(n,1)-1,'like',T.x);
Вызовите MEX-функцию, проходящий внутрь T: y = mysum_mex(x,T);
Звонить codegen прохождение в T: codegen mysum -args {x,T} -config:lib -report
Вот обновленный тестовый скрипт.
%% Build instrumented mex T = mytypes('double'); n = 10; buildInstrumentedMex mysum ... -args {zeros(n,1,'like',T.x),T} -histogram %% Test inputs rng default x = cast(2*rand(n,1)-1,'like',T.x); % Algorithm y = mysum_mex(x,T); % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x,T} -config:lib -report
Запустите тестовый скрипт и щелкните ссылку, чтобы открыть отчет генерации кода.
Сгенерированный код C аналогичен коду, сгенерированному для исходного алгоритма. Потому что переменная T используется для определения типов, и эти типы являются постоянными во время генерации кода; T не используется во время исполнения и не отображается в сгенерированном коде.
Обновите тестовый скрипт, чтобы использовать фиксированные точки, предложенную ранее, и просмотреть сгенерированный код C.
Обновите тестовый скрипт, чтобы использовать фиксированные точки. Замените T = mytypes('double'); с T = mytypes('fixed'); а затем сохраните скрипт.
Запустите тестовый скрипт и просмотрите сгенерированный код C.
Эта версия кода С не очень эффективна; он содержит много обработки переполнения. Следующим шагом является оптимизация типов данных, чтобы избежать переполнения.
Масштабированные двойки являются гибридом между числами с плавающей точкой и с фиксированной точкой. Fixed-Point Designer™ сохраняет их как двойные с сохраненной информацией о масштабировании, знаке и размере слова. Поскольку вся арифметика выполняется с двойной точностью, можно увидеть любые переполнения, которые происходят.
Обновите тестовый скрипт, чтобы использовать масштабированные двойки. Замените T = mytypes('fixed'); с T = mytypes('scaled');
Еще раз запустите тестовый скрипт.
Тест запускается с использованием масштабированных двойных значений и отображает отчет. Переполнения не обнаружены.
До сих пор вы запустили тестовый скрипт с помощью случайных входов, что означает, что маловероятно, что тест выполнил полную рабочую область значений алгоритма.
Найдите полную область значений входов.
range(T.x)
-1.000000000000000 0.999969482421875
DataTypeMode: Fixed-point: binary point scaling
Signedness: Signed
WordLength: 16
FractionLength: 15Обновите скрипт, чтобы проверить отрицательный случай ребра. Выполняйте mysum_mex с исходным случайным входом и входом, который проверяет полную область значений и агрегирует результаты.
%% Build instrumented mex T = mytypes('scaled'); n = 10; buildInstrumentedMex mysum ... -args {zeros(n,1,'like',T.x),T} -histogram %% Test inputs rng default x = cast(2*rand(n,1)-1,'like',T.x); y = mysum_mex(x,T); % Run once with this set of inputs y_expected = sum(double(x)); err = double(y) - y_expected % Run again with this set of inputs. The logs will aggregate. x = -ones(n,1,'like',T.x); y = mysum_mex(x,T); y_expected = sum(double(x)); err = double(y) - y_expected % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x,T} -config:lib -report
Еще раз запустите тестовый скрипт.
Тестовые запуски и y переполнение области значений типа данных с фиксированной точкой. showInstrumentationResults предлагает новую длину дроби 11 для y.

Обновите тестовый скрипт, чтобы использовать масштабированные двойки с новым предлагаемым типом для y. В myTypes.m, для 'scaled' корпус, T.y = fi([],true,16,11,'DataType','ScaledDouble')
Перезапустите тестовый скрипт.
Переполнения теперь нет.
Обновите таблицу типов данных, чтобы использовать предложенный тип с фиксированной точкой и сгенерировать код.
В myTypes.m, для 'fixed' корпус, T.y = fi([],true,16,11)
Обновите тестовый скрипт, mysum_test, для использования T = mytypes('fixed');
Запустите тестовый скрипт, а затем щелкните ссылку View Report, чтобы просмотреть сгенерированный код C.
short mysum(const short x[10])
{
short y;
int n;
int i;
int i1;
int i2;
int i3;
y = 0;
for (n = 0; n < 10; n++) {
i = y << 4;
i1 = x[n];
if ((i & 1048576) != 0) {
i2 = i | -1048576;
} else {
i2 = i & 1048575;
}
if ((i1 & 1048576) != 0) {
i3 = i1 | -1048576;
} else {
i3 = i1 & 1048575;
}
i = i2 + i3;
if ((i & 1048576) != 0) {
i |= -1048576;
} else {
i &= 1048575;
}
i = (i + 8) >> 4;
if (i > 32767) {
i = 32767;
} else {
if (i < -32768) {
i = -32768;
}
}
y = (short)i;
}
return y;
}По умолчанию fi арифметика использует насыщение при переполнении и ближайшем округлении, что приводит к неэффективному коду.
Чтобы сделать сгенерированный код более эффективным, используйте математику с фиксированной точкой (fimath) настройки, которые более подходят для генерации кода C: перенос при переполнении и округлении пола.
В myTypes.m, добавить 'fixed2' случай:
case 'fixed2'
F = fimath('RoundingMethod', 'Floor', ...
'OverflowAction', 'Wrap', ...
'ProductMode', 'FullPrecision', ...
'SumMode', 'KeepLSB', ...
'SumWordLength', 32, ...
'CastBeforeSum', true);
T.x = fi([],true,16,15,F);
T.y = fi([],true,16,11,F);
Совет
Вместо ввода вручную fimath Свойства можно использовать РЕДАКТОРА MATLAB Insert fimath опции. Для получения дополнительной информации см. раздел Создание конструкторов объектов fimath в графическом интерфейсе пользователя.
Обновите тестовый скрипт, чтобы использовать 'fixed2'запустите скрипт, а затем просмотрите сгенерированный код C.
short mysum(const short x[10])
{
short y;
int n;
y = 0;
for (n = 0; n < 10; n++) {
y = (short)(((y << 4) + x[n]) >> 4);
}
return y;
}Сгенерированный код эффективнее, но y смещен так, чтобы выровняться со x и теряет 4 бита точности.
Чтобы исправить эту потерю точности, обновите размер слова y до 32 бит и сохраните 15 бит точности, чтобы соответствовать x.
В myTypes.m, добавить 'fixed32' случай:
case 'fixed32'
F = fimath('RoundingMethod', 'Floor', ...
'OverflowAction', 'Wrap', ...
'ProductMode', 'FullPrecision', ...
'SumMode', 'KeepLSB', ...
'SumWordLength', 32, ...
'CastBeforeSum', true);
T.x = fi([],true,16,15,F);
T.y = fi([],true,32,15,F);
Обновите тестовый скрипт, чтобы использовать 'fixed32' и запустите скрипт, чтобы сгенерировать код снова.
Теперь сгенерированный код очень эффективен.
int mysum(const short x[10])
{
int y;
int n;
y = 0;
for (n = 0; n < 10; n++) {
y += x[n];
}
return y;
}Для получения дополнительной информации смотрите Оптимизируйте свой алгоритм.
