Ускоренные графическим процессором вычисления следуют гетерогенной модели программирования. Сильно параллелизируемые фрагменты программного обеспечения отображаются в ядра, которые выполняются на физически отдельном графическом процессоре, в то время как остальная часть последовательного кода все еще работает на центральном процессоре. Каждому ядру выделяется несколько рабочих процессов или потоков, которые организованы в блоки и сетки. Каждый поток в ядре выполняется одновременно относительно друг друга.
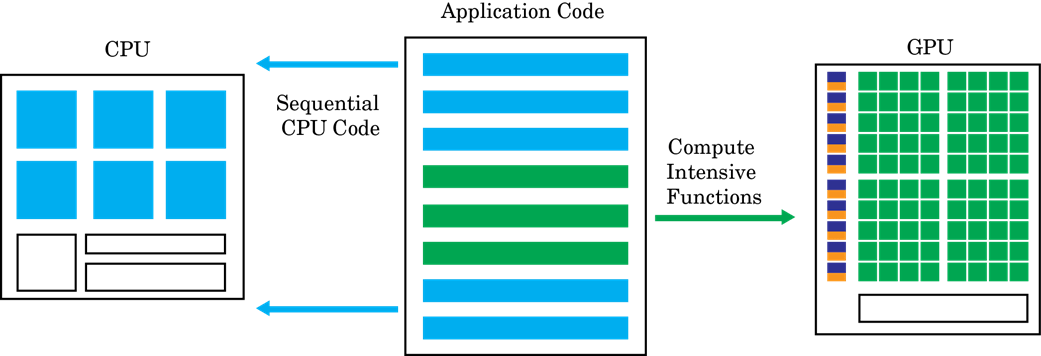
Цель GPU Coder™ состоит в том, чтобы взять последовательный MATLAB® программировать и генерировать секционированные, оптимизированные CUDA® код из него. Этот процесс включает в себя:
Секционирование CPU/GPU - идентификация сегментов кода, выполняемых на центральный процессор, и сегментов, выполняемых на графический процессор. Для различных способов, как GPU Coder идентифицирует ядра CUDA, смотрите Создание ядра. Затраты на передачу памяти между CPU и GPU являются существенным фактором в алгоритме создания ядра.
После завершения разделения ядра GPU Coder анализирует зависимость данных между разделами CPU и GPU. Данные, которые являются общими между центральным процессором и графическим процессором, выделяются на памяти GPU (при помощи cudaMalloc или cudaMallocManaged API). Анализ также определяет минимальный набор местоположений, где данные должны быть скопированы между центральным процессором и графическим процессором при помощи cudaMemcpy. Если использовать Unified Memory в CUDA, то тот же анализ проходит также определяет минимальные местоположения в коде, где cudaDeviceSync Чтобы получить правильное функциональное поведение, необходимо вставить вызовы.
Затем в каждом ядре GPU Coder может принять решение сопоставить данные с общей памятью или постоянной памятью. При разумном использовании эти памяти являются частью структуры иерархии памяти графический процессор и потенциально могут привести к большей пропускной способности памяти. Для получения информации о том, как GPU Coder выбирает сопоставление с общей памятью, смотрите Обработку трафарета. Для получения информации о том, как GPU Coder решает сопоставить с постоянной памятью, смотрите coder.gpu.constantMemory.
Как только имеются операторы выделения и передачи памяти, GPU Coder генерирует код CUDA, который следует решениям о разделении и выделении памяти. Сгенерированный исходный код может быть скомпилирован в целевой объект MEX, вызываемый из MATLAB, или в общую библиотеку, которая будет интегрирована с внешним проектом. Для получения дополнительной информации смотрите Генерация кода Используя Интерфейс командной строки.
