Используйте рабочий процесс на этой странице, если вы разработали эксперимент, собрали данные и хотите использовать эти данные для подгонки моделей. Мастер подгонки моделей поможет вам выполнить эти шаги. Можно также перестроить существующие модели к новым данным с помощью Мастера подгонки моделей.
Если вы хотите подгонять модели к данным и не имеете существующего плана тестирования в проекте, используйте Import Data рабочий процесс общей задачи. Следуйте шагам в Model Set Up.
Настройте план тестирования для проектов путем следования шагам в Set Up Design Inputs. После сбора данных вернитесь в Model Browser, чтобы импортировать данные и подгонять модели. В любом плане тестирования, чтобы выбрать новые данные для подгонки моделей, выполните одно из следующих действий:
В представлении Model Browser плана тестирования на панели Common Tasks щелкните Fit models или выберите TestPlan > Fit Models.
Дважды кликните блок Responses в схеме плана тестирования.
Откроется мастер подгонки моделей.
Выберите набор данных, для которого будут соответствовать модели. Выберите набор данных в проекте из списка или нажмите кнопку, чтобы загрузить новый набор данных, если это необходимо. Если вы загружаете новые данные, установите флажок Open Data Editor on completion, чтобы просмотреть или отредактировать данные перед моделированием.
Если план тестирования содержит какие-либо проекты, выберите, использовать ли весь набор данных или соответствовать данным проекту. При соответствии проекту выберите проект в списке.
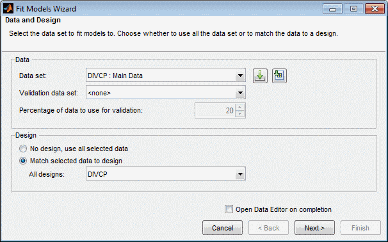
Выберите входные сигналы для модели (на всех этапах иерархической модели) из списка сигналов данных справа и сопоставьте их с правильными переменными модели с помощью большой кнопки со стрелой. Дважды кликните элемент в списке сигналов данных, чтобы выбрать этот сигнал для текущего выбранного входного фактора, а затем перейдите к следующему входу.
Если вы ввели правильное имя сигнала на этапе настройки модели, соответствующий сигнал автоматически выбирается, когда выбирается каждый входной коэффициент модели. Это может быть экономией времени, если в наборе данных много сигналов данных. Если имя сигнала неверно, необходимо щелкнуть, чтобы выбрать правильную переменную для каждого входа.
Если вы хотите использовать область значений сигналов данных для входных областей значений модели, вместо областей значений, установленных в проектных входах, установите флажок Use data ranges for all inputs.
Чтобы продолжить выбор моделей отклика, нажмите Next.
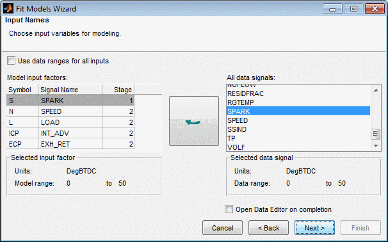
Используйте следующие элементы управления для настройки моделей:
Если начнем с пустого списка Responses, выберите требуемый ответ в списке Unused data signals и нажмите Add.
Если вы используете шаблон плана тестирования или выбираете новые данные в плане тестирования, ответы могут быть уже заданы в списке Responses. Если вы хотите изменить ответ, выберите сигнал и нажмите большую кнопку со стрелой, чтобы заменить текущий выбранный ответ. Предыдущий ответ появляется в скобках, чтобы сообщить вам, что изменилось.
Когда в списке уже есть ответ, нажатие кнопки Add не заменяет выбор, но увеличивает количество ответов. Кнопка замены (со стрелой) недоступна, если поле с Responses пусто.
Можно использовать Delete для удаления выбранных ответов.
Можно выбрать Модели данной величины (Datum) (если локальная модель поддерживает их), и можно использовать кнопки Set Up, чтобы изменить локальную и глобальную модели. Для получения дополнительной информации смотрите Исследования типов локальных моделей, Исследования типов глобальных моделей и Опорные модели.
Чтобы создать краевую модель, оставьте флажок Fit boundary model установленным.
Чтобы продолжить:
Щелкните Finish, чтобы подогнать модели.
Если необходимо задать тестовые группы для двухэтапных моделей или моделей «точка за точкой», откроется диалоговое окно «Тестовые группы». Проверьте или измените тестовые группы и нажатие кнопки OK, чтобы продолжить подбор кривой модели. См. «Определение тестовых групп».
Если флажок установлен Open Data Editor on completion, откроется Редактор данных (Data Editor) для просмотра или редактирования данных перед моделированием. Для следующих шагов работы с данными смотрите Использование данных. Модели устанавливаются после закрытия редактора данных.
Для следующих шагов оценки ваших моделей смотрите Оценка модели.
Если вы подбираете данные к проекту, нажмите Next. См. Шаг 4. Установка допусков.
Вы можете достичь шага 4 только, если вы совпадаете с данными проекта. Установка допусков релевантна только в случае соответствия данных проекту. Можно сопоставить данные только с проектами для глобальных моделей.
Можно также отредактировать допуски позже с помощью контекстного меню в окне Редактор. Определения кластеров см. в редакторе допусков.
Установите Input factor tolerances для каждой переменной, чтобы определить размер допуска в каждой размерности. Это используется для выбора данных. Допуск в каждой размерности определяет размер «кластеров» с центром на каждой проектной точке. Точки данных, которые находятся в пределах допуска к проекту, включены в этот кластер. Точки данных, которые попадают в допуск более чем одной точки проекта, образуют один кластер, содержащий все эти точки проекта и данных. Если никакие точки данных не попадают в допуск конкретной точки проекта, они остаются несопоставленными. Значения допуска по умолчанию связаны с переменными областями значений.
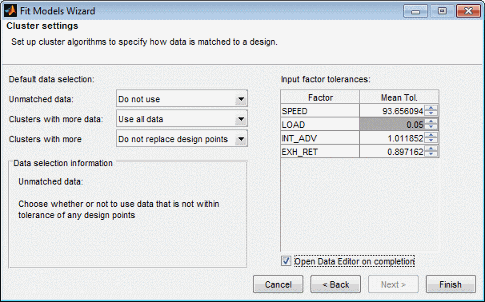
Варианты, которые вы делаете в опциях Default data selection, определяют, как алгоритм кластера сначала запускается, чтобы выбрать соответствующие данные и проектировать точки. Это влияет только на состояние флажков для данных и проекта точек, когда вы впервые видите представление Проекта Match в редакторе данных. Результаты этого всегда можно изменить позже в списке Соответствие проекту (Design Match), где можно вручную выбрать данные и проектные точки, которые необходимо использовать.
Когда вы выходите из редактора данных, эти выборки определяют, какие данные используются для моделирования и как точки проекта дополняются и заменяются. Выбранные данные используются для моделирования и добавляются к проекту. Данные, которые вы решили исключить, не используются для моделирования или добавляются к проекту.
Unmatched data — Use или Do not use
Данные, которые не находятся в пределах допуска какой-либо проектной точки, не совпадают. Вы можете решить, что с ними делать. Если вы выбираете Use, эти данные выбираются для моделирования и добавляются к вашему проекту.
Если вы выбираете Do not use, затем несопоставленные данные не используются для моделирования или не добавляются к проекту; это исключенные данные.
Clusters with more data — Use all data или Use closest match only
Это относится к кластерам, содержащим больше точек данных, чем точек проекта. Если вы выбираете Use all dataвсе точки данных в этих кластерах выбираются для моделирования и добавляются к проекту, заменяя точки проектирования в этих кластерах.
Если вы выбираете Use closest match only, затем выбирается соответствие один к одному ближайшей к каждой точке проекта точки данных, и это единственные точки, которые выбираются для моделирования и добавляются к проекту (замена каждой точки проекта).
Cluster with more design — Do not replace design points или Replace design with closest
Все данные из этих кластеров выбираются для моделирования. Настройка здесь влияет только на выбор проекта.
Там, где кластеры содержат больше проектных точек, чем точек данных, можно принять решение оставить проект неизменным, выбрав Do not replace design points.
Если вы выбираете Replace design with closest, это заменяет проектные точки, где это возможно, ближайшей точкой данных и оставляет остальные проектные точки неизменными.
Помните, что вы можете переопределить любой из этих вариантов выбора вручную в редакторе данных; изменения применяются только при закрытии редактора данных после соответствия. Представление Design Match в окне Редактор появляется по умолчанию, когда вы закрываете мастер подгонки моделей во время соответствия данных проектам. См. «Соответствие данных проектам».
