SoC Blockset™ позволяет проводить постсимуляционный анализ диагностических данных памяти. Эти графики обеспечивают высокоуровневую эффективность диагностику системы памяти модели. Эти графики являются вычисленными измерениями из симуляции вашей модели. Он рассматривает тип данных, шаг расчета и тактовую частоту, чтобы вычислить полосу пропускания вашей модели памяти и рассматривает количество пакетов, выполняемых на каждый порт памяти.
Чтобы включить вход сигнала в симуляцию, выберите Hardware Implementation в диалоговом окне Параметров конфигурации. В разделе Hardware Board Settings > Target Hardware Resources > FPGA design (debug) выберите требуемый Memory channel diagnostic level.
Этот рисунок показывает карту данных от одного алгоритма FPGA к другому алгоритму FPGA через канал памяти.
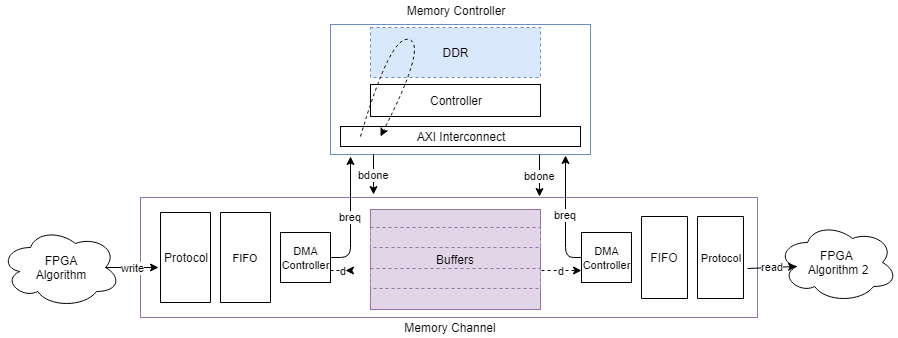
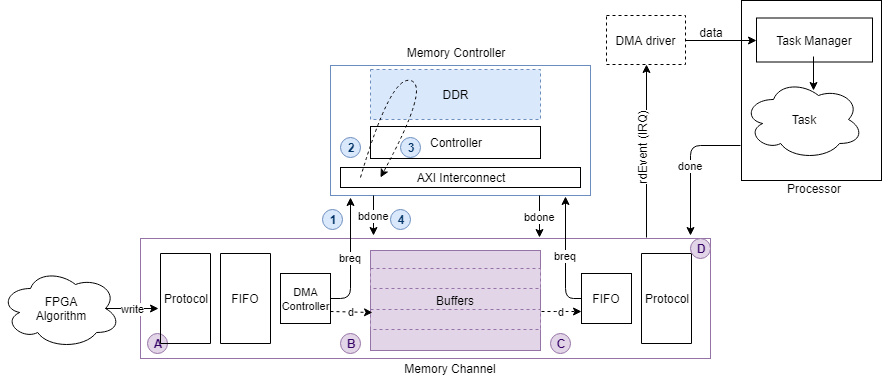
Можно просмотреть графики задержки канала для datapath (представленного A, B, C и D в изображении) из маски Memory Channel блока. Можно просмотреть пропускную способность памяти, количество пакетов и измерения задержки управления (представленные 1, 2, 3 и 4 в изображении) из маски Memory Controller блока.
Обмен данными от алгоритма FPGA к процессору обслуживается через драйвер DMA и процессор задач и проиллюстрирован на этом изображении.
Информация о задержке канала памяти доступна после симуляции на канал. После симуляции модели откройте маску Memory Channel блока. На вкладке Performance нажмите Launch performance plots. Это действие открывает новое окно с несколькими опциями управления, чтобы отобразить эти различные задержки:
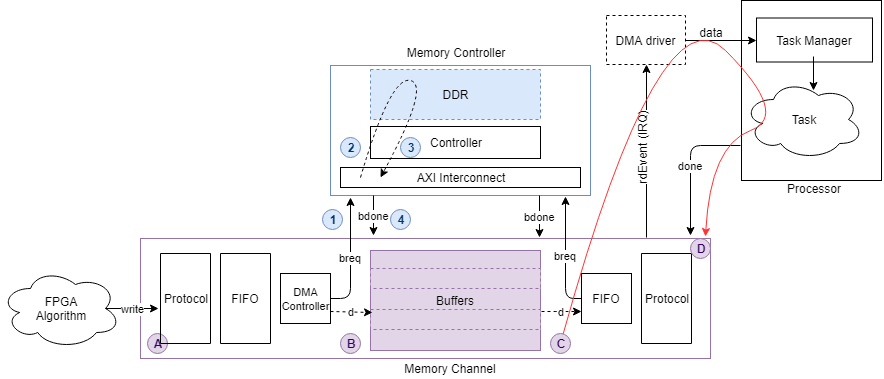
Buffer write complete - Эта опция показывает время, необходимое между отправкой запроса на запись, до момента полной записи буфера. Это путь между A и B на рисунке.
Buffer read complete - Эта опция показывает время, необходимое между отправкой запроса на чтение, когда буфер считан и снова доступен для записи. Это путь между C и D на рисунке. Эта опция доступна, только если считыватель является алгоритмом FPGA (не алгоритмом процессора). Если считыватель является алгоритмом процессора, это время показывает как нуль.
Buffer task execution complete - Эта опция показывает время, необходимое между отправкой запроса на чтение, когда буфер считан и снова доступен для записи. Это путь между C и D на рисунке. Эта опция доступна, только если считыватель является алгоритмом процессора (не алгоритмом FPGA). Если считыватель является алгоритмом FPGA, то это время показывает как нуль.
В Buffer task execution complete показано время, необходимое для того, чтобы эти события произошли:
Буфер записи полон.
Канал выдал процессор запрос на прерывание (IRQ).
Выполняется стандартная программа обработки прерывания (ISR).
Запланировано выполнение задачи.
Задача начала выполняться.
Задача считывает данные.
Задача необязательно обработала данные.
Задача отправляет done сигнал назад в канал.
Следующий рисунок показывает путь задержки для выполнения задачи в виде красной стрелы от C до D.
Averaging Window (s) - Задайте время (в секундах) для ширины окна усреднения. График отображается как скользящее среднее значение с использованием временного окна с заданной шириной. Можно также задать min, max, или auto.
min - Используйте это значение для просмотра данных без какого-либо усреднения. График общей задержки выровнен по Instantaneous Total Latency меткам.
max - Используйте это значение, чтобы увидеть общее среднее значение для всей симуляции.
auto - Используйте это значение, чтобы увидеть среднее по количеству буферов в вашем канале.
Instantaneous Total Latency - Это показывает дискретные общие измерения задержки на буфер.
Если вы добавляете Buffer write complete к Buffer read complete или Buffer task execution complete, график отображает полную задержку от средства записи до читателя. На этом изображении показан график общей задержки для примера Потоковые данные от оборудования к программному обеспечению.
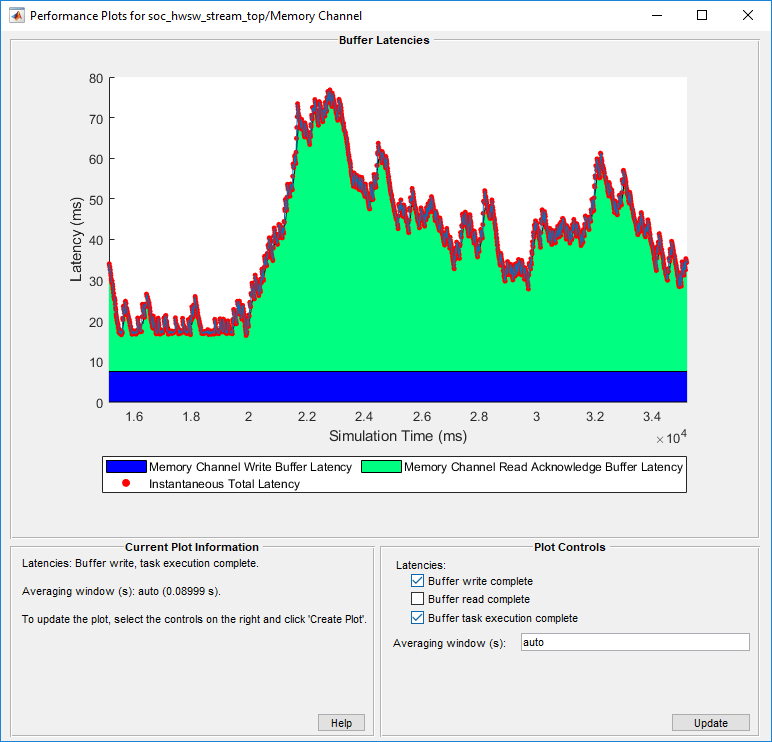
Обратите внимание, что задержки отображаются в окне усреднения за одну секунду. Мгновенная общая задержка показывает пик задержки 76,8267 мс. Используйте эту информацию для проверки модели на соответствие требованиям.
Информация о задержке контроллера памяти доступна после симуляции. После симуляции модели откройте маску Memory Controller блока. На вкладке Performance нажмите Launch performance plots. Это действие открывает новое окно с несколькими опциями управления для отображения показателей эффективности.
Этот рисунок показывает карту данных от одного алгоритма FPGA к другому алгоритму FPGA через канал памяти.
На вкладке Latencies выберите мастер, для которого необходимо построить график задержек. Выберите один из следующих опций:
Burst request to first transfer complete - Эта опция показывает время, которое требуется от момента, когда блок Memory Channel выдает запрос пакетной записи, до первой передачи данных. Эта задержка учитывает арбитражные или межсоединительные задержки. Это путь между 1 и 2 на рисунке.
Burst execution latency - Эта опция показывает время, которое требуется от первой передачи данных до того момента, когда пакет записывается в память. Это путь между 2 и 3 на рисунке.
Burst last transfer to complete latency - Эта опция показывает время, которое требуется от момента завершения пакета до того, когда блок Memory Controller выдает burst-done сигнал блоку Memory Channel. Это путь между 3 и 4 на рисунке.
Averaging Window (s) - Задайте время (в секундах) для ширины окна усреднения. График отображается как скользящее среднее значение с использованием временного окна с заданной шириной. Можно также задать min, max, или auto.
min - Используйте это значение для просмотра данных без какого-либо усреднения. График общей задержки выровнен по Instantaneous Total Latency меткам.
max - Используйте это значение, чтобы увидеть общее среднее значение для всей симуляции.
auto - Используйте это значение, чтобы увидеть среднее значение более 1% пакетов во время симуляции.
Instantaneous Total Latency - Эта опция показывает дискретные измерения общей задержки на пакет.
Щелкните Create Plot, чтобы увидеть задержку для выбранных мастеров в течение длительности симуляции. На этом изображении показана общая задержка для Master 2 в примере Analyze Memory Bandwidth Using Traffic Generators.
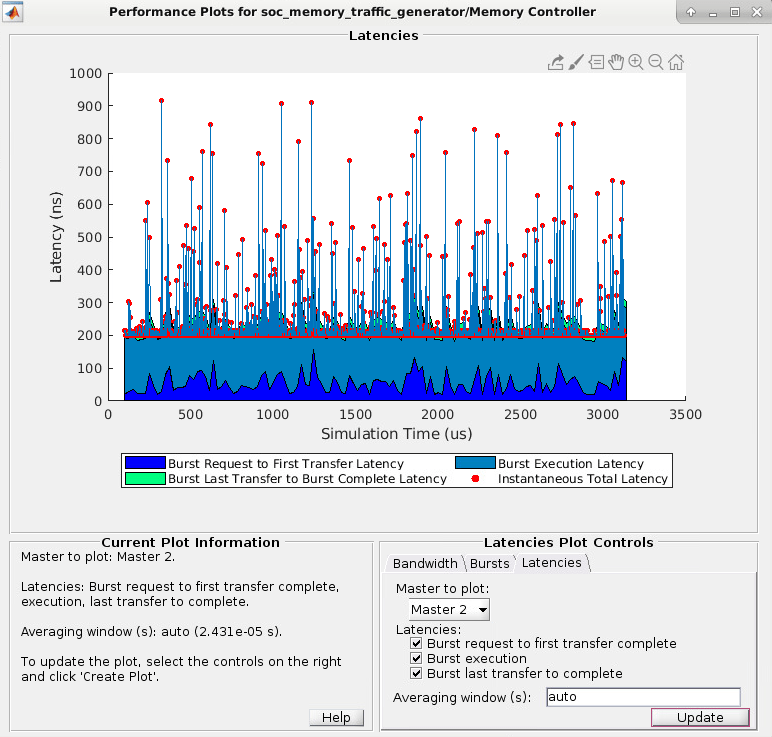
Примечание
Графики задержки контроллера памяти недоступны, когда мастер является процессором.
Затем можно масштабировать, чтобы проанализировать пиковую мгновенную задержку: 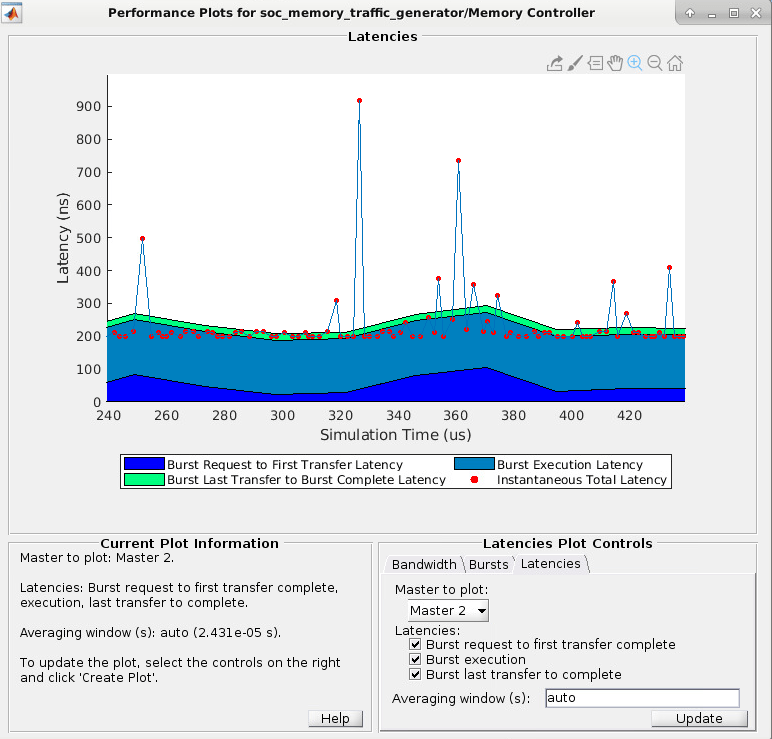
На вкладке Bandwidth выберите шаблоны, для которых необходимо построить график полосы пропускания. Щелкните Create Plot, чтобы увидеть пропускную способность в мегабайтах в секунду для выбранных мастеров за время симуляции. На этом изображении показана пропускная способность для примера Analyze Memory Bandwidth Using Traffic Generators.
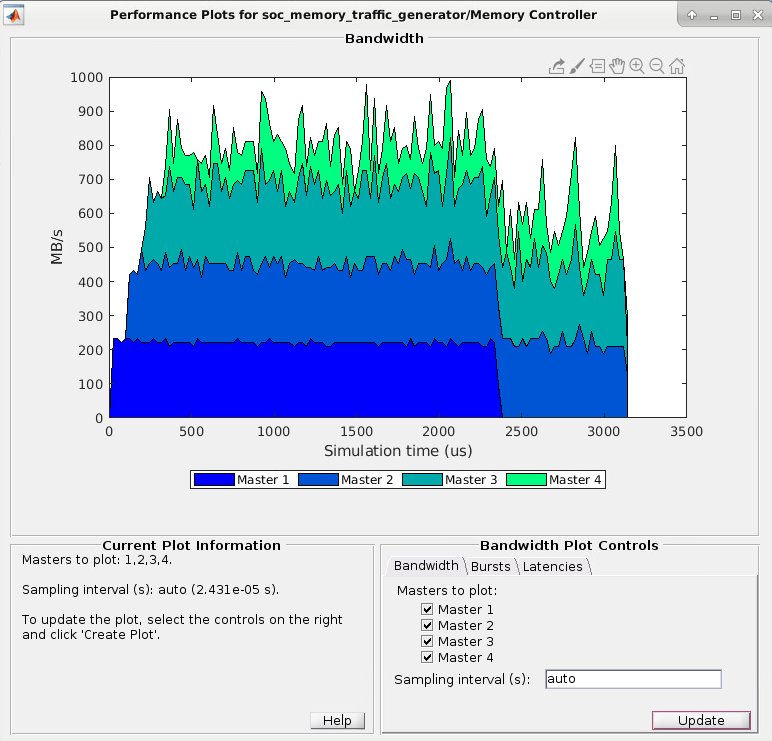
Примечание
Информация о пропускной способности не отображается, когда ведущий процессор является процессором.
На вкладке Bursts выберите шаблоны, для которых необходимо выполнить граф пакетов. Щелкните Create Plot, чтобы увидеть количество пакетов, выполненных для выбранного ведущего за время симуляции. На этом изображении показано количество пакетов для примера Analyze Memory Bandwidth Using Traffic Generators.
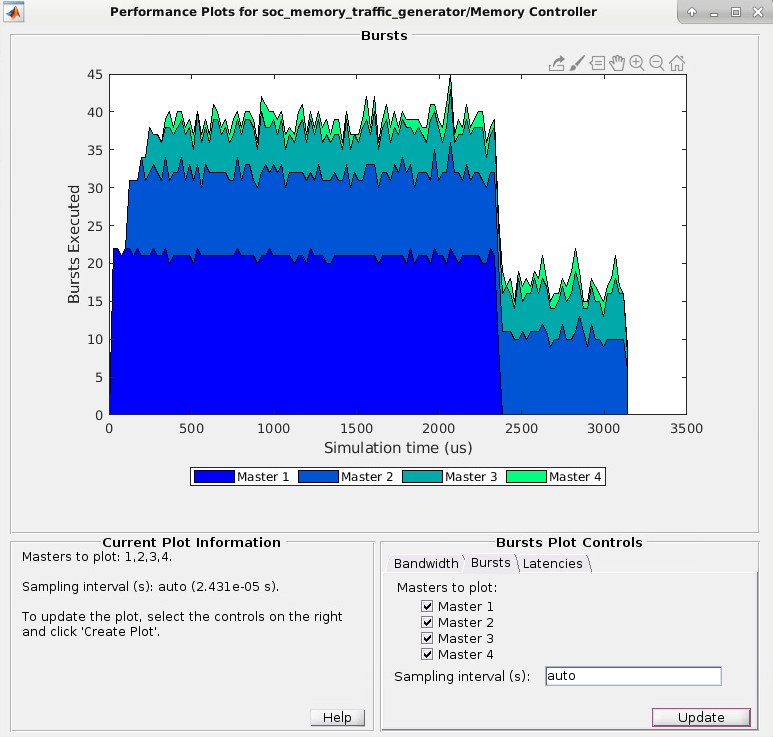
Примечание
Информация о пропускной способности не отображается, когда ведущий процессор является процессором.
Memory Channel | Memory Controller
