Классификационные потери для Гауссовой модели классификации ядра
L = loss(Mdl,Tbl,ResponseVarName)Mdl использование данных предиктора в Tbl и истинные метки классов в Tbl.ResponseVarName.
L = loss(___,Name,Value)loss возвращает взвешенные классификационные потери с помощью указанной функции потерь.
Classification loss функции измеряют прогнозирующую неточность классификационных моделей. Когда вы сравниваете один и тот же тип потерь среди многих моделей, более низкая потеря указывает на лучшую прогнозирующую модель.
Предположим следующее:
L - средневзвешенные классификационные потери.
n - размер выборки.
yj - наблюдаемая метка класса. Программное обеспечение кодирует его как -1 или 1, указывая на отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) является баллом классификации положительного класса для j наблюдений (строка) X данных предиктора.
mj = yj f (Xj) является классификационной оценкой для классификации j наблюдений в класс, относящийся к yj. Положительные значения mj указывают на правильную классификацию и не вносят большой вклад в средние потери. Отрицательные значения mj указывают на неправильную классификацию и вносят значительный вклад в среднюю потерю.
Вес для j наблюдения wj. Программа нормализует веса наблюдений так, чтобы они суммировались с соответствующей вероятностью предыдущего класса. Программное обеспечение также нормализует предыдущие вероятности, так что они равны 1. Поэтому,
В этой таблице описываются поддерживаемые функции потерь, которые можно задать с помощью 'LossFun' аргумент имя-значение.
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Экспоненциальные потери | 'exponential' | |
| Неверно классифицированный коэффициент в десятичных числах | 'classiferror' | - метка класса, соответствующая классу с максимальным счетом. I {·} является функцией индикации. |
| Потеря шарнира | 'hinge' | |
| Логит потеря | 'logit' | |
| Минимальные ожидаемые затраты на неправильную классификацию | 'mincost' |
Программа вычисляет взвешенные минимальные ожидаемые затраты классификации, используя эту процедуру для наблюдений j = 1,..., n.
Взвешенное среднее значение минимальных ожидаемых потерь от неправильной классификации Если вы используете матрицу затрат по умолчанию (значение элемента которой 0 для правильной классификации и 1 для неправильной классификации), то |
| Квадратичные потери | 'quadratic' |
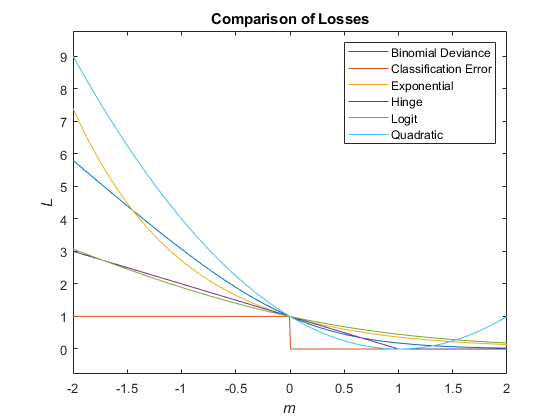
Этот рисунок сравнивает функции потерь (кроме 'mincost') по счету m для одного наблюдения. Некоторые функции нормированы, чтобы пройти через точку (0,1).