Класс: ClassificationLinear
Классификационные потери для линейных классификационных моделей
L = loss(Mdl,Tbl,ResponseVarName)Tbl и истинные метки классов в Tbl.ResponseVarName.
L = loss(___,Name,Value)
Загрузите набор данных NLP.
load nlpdataX является разреженной матрицей данных предиктора, и Y является категориальным вектором меток классов. В данных более двух классов.
Модели должны определять, получено ли количество слов на веб-странице из документации Statistics and Machine Learning Toolbox™. Итак, идентифицируйте метки, которые соответствуют веб-страницам документации Statistics and Machine Learning Toolbox™.
Ystats = Y == 'stats';Обучите двоичную, линейную модель классификации, которая может идентифицировать, является ли слово счетчиком на веб-странице документации из документации Statistics and Machine Learning Toolbox™. Задайте, чтобы задержать 30% наблюдений. Оптимизируйте целевую функцию с помощью SpaRSA.
rng(1); % For reproducibility CVMdl = fitclinear(X,Ystats,'Solver','sparsa','Holdout',0.30); CMdl = CVMdl.Trained{1};
CVMdl является ClassificationPartitionedLinear модель. Оно содержит свойство Trained, который является массивом ячеек 1 на 1, содержащим ClassificationLinear Модель, что программное обеспечение обучалось с использованием набора обучающих данных.
Извлеките обучающие и тестовые данные из определения раздела.
trainIdx = training(CVMdl.Partition); testIdx = test(CVMdl.Partition);
Оцените ошибку классификации обучающей и тестовой выборки.
ceTrain = loss(CMdl,X(trainIdx,:),Ystats(trainIdx))
ceTrain = 1.3572e-04
ceTest = loss(CMdl,X(testIdx,:),Ystats(testIdx))
ceTest = 5.2804e-04
Потому что есть одна сила регуляризации в CMdl, ceTrain и ceTest являются числовыми скалярами.
Загрузите набор данных NLP. Предварительно обработайте данные как в Estimate Test-Sample Classification Loss, и транспонируйте данные предиктора.
load nlpdata Ystats = Y == 'stats'; X = X';
Обучите двоичную, линейную модель классификации. Задайте, чтобы задержать 30% наблюдений. Оптимизируйте целевую функцию с помощью SpaRSA. Задайте, что наблюдения предиктора соответствуют столбцам.
rng(1); % For reproducibility CVMdl = fitclinear(X,Ystats,'Solver','sparsa','Holdout',0.30,... 'ObservationsIn','columns'); CMdl = CVMdl.Trained{1};
CVMdl является ClassificationPartitionedLinear модель. Оно содержит свойство Trained, который является массивом ячеек 1 на 1, содержащим ClassificationLinear Модель, что программное обеспечение обучалось с использованием набора обучающих данных.
Извлеките обучающие и тестовые данные из определения раздела.
trainIdx = training(CVMdl.Partition); testIdx = test(CVMdl.Partition);
Создайте анонимную функцию, которая измеряет линейные потери, то есть
- вес для наблюдения j, является ответом j (-1 для отрицательного класса и 1 в противном случае), и - необработанная классификационная оценка наблюдения j. Пользовательские функции потерь должны быть записаны в конкретную форму. Правила записи пользовательской функции потерь см. в LossFun аргумент пары "имя-значение".
linearloss = @(C,S,W,Cost)sum(-W.*sum(S.*C,2))/sum(W);
Оцените потери классификации обучающей и тестовой выборки с помощью функции линейных потерь.
ceTrain = loss(CMdl,X(:,trainIdx),Ystats(trainIdx),'LossFun',linearloss,... 'ObservationsIn','columns')
ceTrain = -7.8330
ceTest = loss(CMdl,X(:,testIdx),Ystats(testIdx),'LossFun',linearloss,... 'ObservationsIn','columns')
ceTest = -7.7383
Чтобы определить хорошую силу лассо-штрафа для линейной классификационной модели, которая использует учителя логистической регрессии, сравните частоты ошибок классификации тестовой выборки.
Загрузите набор данных NLP. Предварительно обработайте данные как в «Задать пользовательские классификационные потери».
load nlpdata Ystats = Y == 'stats'; X = X'; rng(10); % For reproducibility Partition = cvpartition(Ystats,'Holdout',0.30); testIdx = test(Partition); XTest = X(:,testIdx); YTest = Ystats(testIdx);
Создайте набор из 11 логарифмически разнесенных сильных сторон регуляризации через .
Lambda = logspace(-6,-0.5,11);
Обучите двоичные, линейные модели классификации, которые используют каждую из сильных сторон регуляризации. Оптимизируйте целевую функцию с помощью SpaRSA. Уменьшите допуск на градиент целевой функции, чтобы 1e-8.
CVMdl = fitclinear(X,Ystats,'ObservationsIn','columns',... 'CVPartition',Partition,'Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',Lambda,'GradientTolerance',1e-8)
CVMdl =
ClassificationPartitionedLinear
CrossValidatedModel: 'Linear'
ResponseName: 'Y'
NumObservations: 31572
KFold: 1
Partition: [1x1 cvpartition]
ClassNames: [0 1]
ScoreTransform: 'none'
Properties, Methods
Извлеките обученную модель линейной классификации.
Mdl = CVMdl.Trained{1}Mdl =
ClassificationLinear
ResponseName: 'Y'
ClassNames: [0 1]
ScoreTransform: 'logit'
Beta: [34023x11 double]
Bias: [1x11 double]
Lambda: [1x11 double]
Learner: 'logistic'
Properties, Methods
Mdl является ClassificationLinear объект модели. Потому что Lambda последовательность регуляризационных сильных сторон, вы можете думать о Mdl как 11 моделей, по одной на каждую силу регуляризации в Lambda.
Оцените ошибку классификации тестовой выборки.
ce = loss(Mdl,X(:,testIdx),Ystats(testIdx),'ObservationsIn','columns');
Потому что существует 11 сильных сторон регуляризации, ce является вектором классификационных ошибок 1 на 11.
Более высокие значения Lambda привести к разреженности переменной предиктора, которая является хорошим качеством классификатора. Для каждой силы регуляризации обучите линейную модель классификации, используя весь набор данных и те же опции, что и при перекрестной проверке моделей. Определите количество ненулевых коэффициентов на модель.
Mdl = fitclinear(X,Ystats,'ObservationsIn','columns',... 'Learner','logistic','Solver','sparsa','Regularization','lasso',... 'Lambda',Lambda,'GradientTolerance',1e-8); numNZCoeff = sum(Mdl.Beta~=0);
На том же рисунке постройте график частот ошибок тестовой выборки и частоты ненулевых коэффициентов для каждой силы регуляризации. Постройте график всех переменных по шкале журнала.
figure; [h,hL1,hL2] = plotyy(log10(Lambda),log10(ce),... log10(Lambda),log10(numNZCoeff + 1)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} classification error') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') title('Test-Sample Statistics') hold off

Выберите индекс силы регуляризации, который балансирует переменную разреженности предиктора и низкую ошибку классификации. В этом случае значение между кому должно быть достаточно.
idxFinal = 7;
Выберите модель из Mdl с выбранной прочностью на регуляризацию.
MdlFinal = selectModels(Mdl,idxFinal);
MdlFinal является ClassificationLinear модель, содержащая одну силу регуляризации. Чтобы оценить метки для новых наблюдений, передайте MdlFinal и новые данные для predict.
Classification loss функции измеряют прогнозирующую неточность классификационных моделей. Когда вы сравниваете один и тот же тип потерь среди многих моделей, более низкая потеря указывает на лучшую прогнозирующую модель.
Рассмотрим следующий сценарий.
L - средневзвешенные классификационные потери.
n - размер выборки.
Для двоичной классификации:
yj - наблюдаемая метка класса. Программное обеспечение кодирует его как -1 или 1, указывая на отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) является баллом классификации положительного класса для j наблюдений (строка) X данных предиктора.
mj = yj f (Xj) является классификационной оценкой для классификации j наблюдений в класс, относящийся к yj. Положительные значения mj указывают на правильную классификацию и не вносят большой вклад в средние потери. Отрицательные значения mj указывают на неправильную классификацию и вносят значительный вклад в среднюю потерю.
Для алгоритмов, которые поддерживают многоклассовую классификацию (то есть K ≥ 3):
yj* - вектор с K - 1 нулями, с 1 в положении, соответствующем истинному, наблюдаемому классу yj. Для примера, если истинный класс второго наблюдения является третьим классом и K = 4, то y 2* = [0 0 1 0]′. Порядок классов соответствует порядку в ClassNames свойство модели входа.
f (Xj) является вектором K длины счетов классов для j наблюдений X данных предиктора. Порядок счетов соответствует порядку классов в ClassNames свойство модели входа.
mj = yj*′ f (<reservedrangesplaceholder1>). Поэтому mj является скалярной классификационной оценкой, которую модель предсказывает для истинного наблюдаемого класса.
Вес для j наблюдения wj. Программа нормализует веса наблюдений так, чтобы они суммировались с соответствующей вероятностью предыдущего класса. Программное обеспечение также нормализует предыдущие вероятности, поэтому они равны 1. Поэтому,
С учетом этого сценария в следующей таблице описываются поддерживаемые функции потерь, которые можно задать при помощи 'LossFun' аргумент пары "имя-значение".
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Неверно классифицированный коэффициент в десятичных числах | 'classiferror' | - метка класса, соответствующая классу с максимальным счетом. I {·} является функцией индикации. |
| Потери перекрестной энтропии | 'crossentropy' |
Взвешенные потери перекрестной энтропии где веса нормированы в сумме к n вместо 1. |
| Экспоненциальные потери | 'exponential' | |
| Потеря шарнира | 'hinge' | |
| Логит потеря | 'logit' | |
| Минимальные ожидаемые затраты на неправильную классификацию | 'mincost' |
Программа вычисляет взвешенные минимальные ожидаемые затраты классификации, используя эту процедуру для наблюдений j = 1,..., n.
Взвешенное среднее значение минимальных ожидаемых потерь от неправильной классификации Если вы используете матрицу затрат по умолчанию (значение элемента которой 0 для правильной классификации и 1 для неправильной классификации), то |
| Квадратичные потери | 'quadratic' |
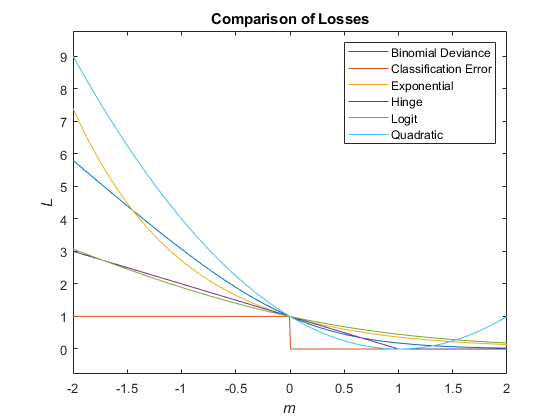
Этот рисунок сравнивает функции потерь (кроме 'crossentropy' и 'mincost') по счету m для одного наблюдения. Некоторые функции нормированы, чтобы пройти через точку (0,1).
По умолчанию веса наблюдений являются предшествующими вероятностями классов. Если вы поставляете веса, используя Weightsзатем программное обеспечение нормализует их, чтобы суммировать предыдущие вероятности в соответствующих классах. Программа использует перенормированные веса, чтобы оценить взвешенные классификационные потери.
