reproducible расчета является таким, который дает одинаковые результаты каждый раз, когда он запускается. Воспроизводимость важна для:
Отладка - Чтобы исправить аномальный результат, нужно воспроизвести результат.
Доверие - когда можно воспроизвести результаты, можно исследовать и понять их.
Изменение существующего кода - Когда вы изменяете существующий код, вы хотите убедиться, что вы ничего не нарушаете.
Как правило, вам не нужно обеспечивать воспроизводимость для вашего расчета. Часто, когда вы хотите воспроизводимости, самый простой метод - запускать последовательно, а не параллельно. В последовательных расчетах можно просто вызвать rng функционировать следующим образом:
s = rng % Obtain the current state of the random stream % run the statistical function rng(s) % Reset the stream to the previous state % run the statistical function again, obtain identical results
В этом разделе рассматривается случай, когда ваша функция использует случайные числа, и вы хотите, чтобы воспроизводимые результаты были параллельными. В этом разделе также рассматривается случай, когда необходимо, чтобы те же результаты были параллельными, как и в последовательной системе.
Чтобы запустить Statistics and Machine Learning Toolbox™ функционируйте воспроизводимо:
Установите UseSubstreams опция для true использование statset.
Установите Streams опция типа, поддерживающего субпотоки: 'mlfg6331_64' или 'mrg32k3a'. Для получения информации об этих потоках смотрите RandStream.list.
Чтобы вычислить параллельно, установите UseParallel опция для true.
Для параллельной подгонки ансамбля с помощью fitcensemble или fitrensemble, создайте шаблон дерева с 'Reproducible' Пара "имя-значение" установлена на true:
t = templateTree('Reproducible',true); ens = fitcensemble(X,Y,'Method','bag','Learners',t,... 'Options',options);
Вызовите функцию со структурой опций.
Чтобы воспроизвести расчеты, сбросьте поток, а затем снова вызовите функцию.
Чтобы понять, почему этот метод дает воспроизводимость, смотрите, Как Субпотоки Включают Воспроизводимые Параллельные Расчеты.
Например, чтобы использовать 'mlfg6331_64' поток для воспроизводимых расчетов:
Создайте соответствующую структуру опций:
s = RandStream('mlfg6331_64'); options = statset('UseParallel',true, ... 'Streams',s,'UseSubstreams',true);
Выполните параллельные расчеты. Для получения инструкций смотрите Quick Start Parallel Computing for Statistics and Machine Learning Toolbox.
Сброс случайного потока:
reset(s);
Повторите параллельные расчеты. Вы получаете одинаковые результаты.
Для примеров параллельных расчетов, выполняемых этим воспроизводимым способом, смотрите Воспроизводимые Параллельные Бутстрап и Train Classification Ensemble in Parallel.
substream является фрагментом случайного потока, который RandStream может получить быстрый доступ. Существует число M таким, что для любого положительного целого числа k, RandStream может перейти в kMномер псевдослучайного числа в потоке. С этой точки RandStream может сгенерировать последующие значения в потоке. В настоящее время, RandStream имеет M = 272, около 5e21 или более.
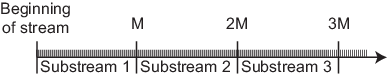
Записи в различных субпотоках имеют хорошие статистические свойства, сходные со свойствами записей в одном потоке: независимость и отсутствие k корреляции при различных лагах. Субпотоки настолько длинны, что можно рассматривать субпотоки как независимые потоки, как на следующей картине.

Два RandStream типы потоков поддерживают субпотоки: 'mlfg6331_64' и 'mrg32k3a'.
Когда MATLAB® выполняет расчеты параллельно с parforкаждый рабочий процесс получает итерации цикла в непредсказуемом порядке. Поэтому вы не можете предсказать, какой рабочий получает итерацию, поэтому не можете определить случайные числа, сопоставленные с каждой итерацией.
Субпотоки позволяют MATLAB связывать каждую итерацию с определенной последовательностью случайных чисел. parfor задает каждой итерации индекс. Итерация использует индекс в качестве номера субпотока. Поскольку случайные числа связаны с итерациями, а не с рабочими, все расчеты воспроизводимы.
Чтобы получить воспроизводимые результаты, просто сбросьте поток, и все субпотоки генерируют идентичные случайные числа при повторном вызове. Этот метод удаётся, когда все рабочие используют один и тот же поток, и поток поддерживает субпотоки. Это завершает обсуждение того, как процедура в Running Reproducible Parallel Computations дает воспроизводимые параллельные результаты.
Несколько функций генерируют случайные числа на клиенте, прежде чем распределять их параллельным рабочим. Рабочие не используют случайные числа, поэтому работают чисто детерминированно. Для этих функций можно запустить параллельные расчеты воспроизводимо, используя любой тип случайного потока.
Функции, которые работают таким образом, включают:
Чтобы получить одинаковые результаты, сбросьте случайный поток на клиенте или случайный поток, который вы передаете клиенту. Для примера:
s = rng % Obtain the current state of the random stream % run the statistical function rng(s) % Reset the stream to the previous state % run the statistical function again, obtain identical results
Хотя этот метод позволяет вам запускать воспроизводимо параллельно, результаты могут отличаться от последовательных расчетов. Причина различия в том, parfor циклы выполняются в обратном порядке от for циклы. Поэтому последовательные расчеты могут генерировать случайные числа в другом порядке, чем параллельные расчеты. Для однозначной воспроизводимости используйте метод в Running Reproducible Parallel Computations.
Для проверки или сравнения с помощью определенных алгоритмов случайных чисел необходимо задать генераторы случайных чисел. Как вы устанавливаете эти генераторы параллельно или инициализируете потоки на каждом рабочем месте определенным образом? Или можно хотеть запустить расчет, используя другую последовательность случайных чисел, чем любой другой, который вы запустили. Как можно убедиться, что используемая последовательность статистически независима?
Функции Parallel Statistics and Machine Learning Toolbox позволяют вам задать случайные потоки на каждом рабочем месте явным образом. Для получения информации о создании нескольких потоков введите help RandStream/create в командной строке. Чтобы создать четыре независимых потока с помощью 'mrg32k3a' генератор:
s = RandStream.create('mrg32k3a','NumStreams',4,...
'CellOutput',true);Передайте эти потоки в статистическую функцию с помощью Streams опция. Для примера:
parpool(4) % if you have at least 4 cores
s = RandStream.create('mrg32k3a','NumStreams',4,...
'CellOutput',true); % create 4 independent streams
paroptions = statset('UseParallel',true,...
'Streams',s); % set the 4 different streams
x = [randn(700,1); 4 + 2*randn(300,1)];
latt = -4:0.01:12;
myfun = @(X) ksdensity(X,latt);
pdfestimate = myfun(x);
B = bootstrp(200,myfun,x,'Options',paroptions);Этот метод распределения потоков дает каждому рабочему потоку другой поток для расчетов. Однако он не допускает воспроизводимых расчетов, потому что рабочие выполняют 200 загрузок в непредсказуемом порядке. Если вы хотите выполнить воспроизводимые расчеты, используйте субпотоки, как описано в Running Reproducible Parallel Computations.
Если вы задаете UseSubstreams опция для true, затем установите Streams опция к одному случайному потоку типа, который поддерживает субпотоки ('mlfg6331_64' или 'mrg32k3a'). Эта настройка дает воспроизводимые расчеты.
