Сравните прогнозирующие точности двух классификационных моделей
testcholdout статистически оценивает точности двух классификационных моделей. Функция сначала сравнивает их предсказанные метки с истинными метками, а затем обнаруживает, является ли различие между показателями неправильной классификации статистически значительной.
Можно оценить, отличаются ли точности классификационных моделей или одна классификационная модель работает лучше другой. testcholdout может провести несколько изменения теста McNemar, включая асимптотический тест, точный-условный тест и среднее p значение теста. Для чувствительной к затратам оценки доступные тесты включают тест хи-квадрат (требует лицензии Optimization Toolbox™) и тест коэффициента вероятности.
h = testcholdout(YHat1,YHat2,Y)метки классов YHat1 и YHat2 имеют равную точность для предсказания истинных меток классов Y. Альтернативная гипотеза заключается в том, что метки имеют неравную точность.
h = 1 указывает на отклонение нулевой гипотезы на уровне 5% значимости. h = 0 указывает, что не отклоняет гипотезу null на уровне 5%.
h = testcholdout(YHat1,YHat2,Y,Name,Value)Name,Value аргументы в виде пар. Для примера можно задать тип альтернативной гипотезы, тип теста или предоставить матрицу затрат.
McNemar Tests проверку гипотезы, которая сравнивает две пропорции населения при решении проблем, возникающих из двух зависимых выборок с совпадающими парами.
Один из способов сравнить прогнозирующие точности двух классификационных моделей:
Разделите данные на обучающие и тестовые наборы.
Обучите обе классификационные модели с помощью набора обучающих данных.
Спрогнозируйте метки классов с помощью тестового набора.
Суммируйте результаты в таблице два на два подобных этого рисунка.
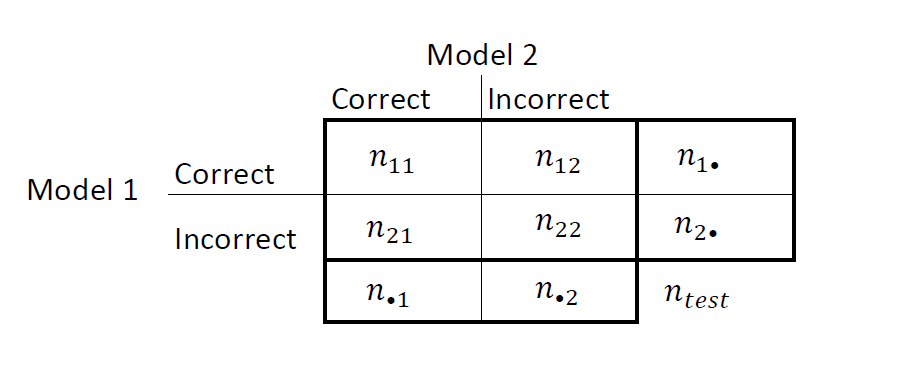
nii количество конкордантных пар, то есть количество наблюдений, которые обе модели классифицируют одинаково (правильно или неправильно). nij, i ≠ j, количество дискордантных пар, то есть количество наблюдений, которые модели классифицируют по-разному (правильно или неправильно).
Коэффициенты неправильной классификации для моделей 1 и 2 и , соответственно. Двусторонний тест для сравнения точности двух моделей
Нулевая гипотеза предполагает, что население проявляет маргинальную однородность, что уменьшает нулевую гипотезу до Кроме того, согласно нулевой гипотезе, N 12 ~ биномиальным (n 12 + n 21,0,5) [1].
Эти факты являются базисом для доступных вариантов теста McNemar: asymptotic, exact-conditional и mid-p-value тестов McNemar. Следующие определения суммируют доступные варианты.
Асимптотическая - асимптотическая статистика теста Макнемара и области отторжения (для α уровня значимости):
Для односторонних тестов тестовая статистика
Если где Φ - стандартный Гауссов cdf, затем отклоните H 0.
Для двусторонних тестов тестовая статистика
Если , где является χm2 cdf оценивают в x, затем отклоняют H 0.
Асимптотический тест требует теории с большой выборкой, в частности Гауссово приближение биномиальному распределению.
Общее количество дискордантных пар, , должно быть больше 10 ([1], ч. 10.1.4).
В целом асимптотические тесты не гарантируют номинального покрытия. Наблюдаемая вероятность ложного отклонения нулевой гипотезы может превысить α, как предполагалось в симуляционных исследованиях в [18]. Однако асимптотический тест Макнемара показывает хорошие результаты с точки зрения статистической степени.
Точная-Условная - Точная-условная статистика теста Макнемара и области отклонения (для α уровня значимости) являются ([36], [38]):
Для односторонних тестов тестовая статистика
Если , где является биномиальным cdf с размером выборки n и вероятность успеха p оценена в x, затем отклонить H 0.
Для двусторонних тестов тестовая статистика
Если , затем отклоните H 0.
Точно-условный тест всегда достигает номинального покрытия. Исследования симуляции в [18] показывают, что тест консервативен, а затем показывают, что тест не имеет статистической степени по сравнению с другими вариантами. Для небольших или сильно дискретных тестовых выборок рассмотрите использование теста mid- p -значение ([1], гл. 3.6.3).
Mid- p -value test - The mid- p -value McNemar test statistics and rejection regions (для уровня значимости α) are ([32]):
Для односторонних тестов тестовая статистика
Если , где и являются биномиальными cdf и pdf, соответственно, с n размера выборки и p вероятности успеха, оцененными в x, затем отклоняют H 0.
Для двусторонних тестов тестовая статистика
Если , затем отклоните H 0.
Тест middle p -значение адресован чрезмерно консервативному поведению точного условного теста. Исследования симуляции в [18] показывают, что этот тест достигает номинального охвата и имеет хорошую статистическую степень.
Это хорошая практика, чтобы получить предсказанные метки классов путем передачи любой обученной классификационной модели и новых данных предиктора в predict способ. Для примера для предсказанных меток из модели SVM смотрите predict.
Чувствительные к расходам тесты выполняют числовую оптимизацию, которая требует дополнительных вычислительных ресурсов. Тест коэффициента правдоподобия проводит числовую оптимизацию косвенно путем нахождения корня множителя Лагранжа в интервале. Для некоторых наборов данных, если корень лежит близко к контурам интервала, то метод может оказаться неудачным. Поэтому, если у вас есть лицензия Optimization Toolbox, рассмотрите проведение чувствительного к стоимости теста chi-квадрат вместо этого. Для получения дополнительной информации смотрите CostTest и чувствительное к расходам проверка.
[1] Agresti, A. Categorical Data Analysis, 2nd Ed. John Wiley & Sons, Inc.: Хобокен, Нью-Джерси, 2002.
[2] Fagerlan, M.W., S. Lydersen, and P. Laake. Тест МакНемара на двоичные совпадающие данные пар: Mid-p и Asymptotic лучше, чем точные условные. Методика медицинских исследований BMC. Том 13, 2013, стр. 1-8.
[3] Ланкастер, H.O. «Тесты значимости в дискретных распределениях». JASA, том 56, номер 294, 1961, стр. 223-234.
[4] McNemar, Q. «Примечание об ошибке дискретизации различий между коррелированными пропорциями или процентами». Психометрика, том 12, № 2, 1947, с. 153-157.
[5] Mosteller, F. «Некоторые статистические проблемы в измерении субъективного ответа на наркотики». Биометрия, том 8, № 3, 1952, с. 220-226.
