Назначьте обнаружения трекам для отслеживания мультиобъектов
[ Присвоения обнаружения треков в контексте сопровождения нескольких объектов с помощью варианта Джеймса Мункреса венгерского алгоритма назначения. Он также определяет, какие треки отсутствуют и какие обнаружения должны начать новые треки. Он возвращает индексы назначенных и неназначенных треков и неназначенных обнаружений. The assignments,unassignedTracks,unassignedDetections]
= assignDetectionsToTracks(costMatrix,costOfNonAssignment)costMatrix должна быть M -by - N матрицей. В этой матрице M представляет количество треков, а N - количество обнаружений. Каждое значение представляет собой стоимость присвоения Nth обнаружение в Mth трек. Чем ниже стоимость, тем больше вероятность того, что обнаружение назначается дорожке. The costOfNonAssignment скалярный вход представляет стоимость дорожки или обнаружения, оставшегося неназначенным.
[ определяет стоимость неназначенных дорожек и обнаружений отдельно. The assignments,unassignedTracks,unassignedDetections]
= assignDetectionsToTracks(costMatrix, unassignedTrackCost,unassignedDetectionCost)unassignedTrackCost должно быть скалярным значением или M элементом, где M представляет количество дорожек. Для вектора M-element каждый элемент представляет стоимость не назначения никакого обнаружения этой дорожке. The unassignedDetectionCost должно быть скалярным значением или N элементом, где N представляет количество обнаружений.
В этом примере показано, как назначить обнаружение дорожке для одного видеокадра.
Установите предсказанные местоположения объектов в текущей системе координат. Получите предсказания с помощью Фильтра Калмана Системного объекта.
predictions = [1,1;2,2];
Установите местоположения объектов, обнаруженных в текущей системе координат. В данном примере существует 2 трека и 3 новых обнаружения. Таким образом, по меньшей мере одно из обнаружений не совпадает, что может указывать на новую дорожку.
detections = [1.1,1.1;2.1,2.1;1.5,3];
Предварительно выделите матрицу затрат.
cost = zeros(size(predictions,1),size(detections,1));
Вычислите стоимость каждого предсказания, соответствующего обнаружению. Стоимость здесь, определяется как евклидово расстояние между предсказанием и обнаружением.
for i = 1:size(predictions, 1) diff = detections - repmat(predictions(i,:),[size(detections,1),1]); cost(i, :) = sqrt(sum(diff .^ 2,2)); end
Связать обнаружение с предсказаниями. Обнаружение 1 должно совпадать с дорожкой 1, а обнаружение 2 должно совпадать с дорожкой 2. Обнаружение 3 должно быть несопоставленным.
[assignment,unassignedTracks,unassignedDetections] = ... assignDetectionsToTracks(cost,0.2); figure; plot(predictions(:,1),predictions(:,2),'*',detections(:,1),... detections(:,2),'ro'); hold on; legend('predictions','detections'); for i = 1:size(assignment,1) text(predictions(assignment(i, 1),1)+0.1,... predictions(assignment(i,1),2)-0.1,num2str(i)); text(detections(assignment(i, 2),1)+0.1,... detections(assignment(i,2),2)-0.1,num2str(i)); end for i = 1:length(unassignedDetections) text(detections(unassignedDetections(i),1)+0.1,... detections(unassignedDetections(i),2)+0.1,'unassigned'); end xlim([0,4]); ylim([0,4]);

costMatrix - Стоимость назначения обнаружения для отслеживанияСтоимость назначения обнаружения дорожке, заданная как M -by - N матрица, где M представляет количество дорожек, а N - количество обнаружений. Значение матрицы затрат должно быть вещественным, непатентованным и числовым. Чем ниже стоимость, тем больше вероятность того, что обнаружение назначается дорожке. Каждое значение представляет собой стоимость присвоения Nth обнаружение в Mth трек. Если нет вероятности назначения между обнаружением и дорожкой, costMatrix для входов задано значение Inf. Внутренне эта функция заполняет матрицу затрат фиктивными строками и столбцами, чтобы учесть возможность неназначенных треков и обнаружений. Заполненные строки представляют обнаружения, не назначенные никаким трекам. Заполненные столбцы представляют дорожки, не связанные с обнаружениями. Функция применяет венгерский алгоритм назначения к заполненной матрице.
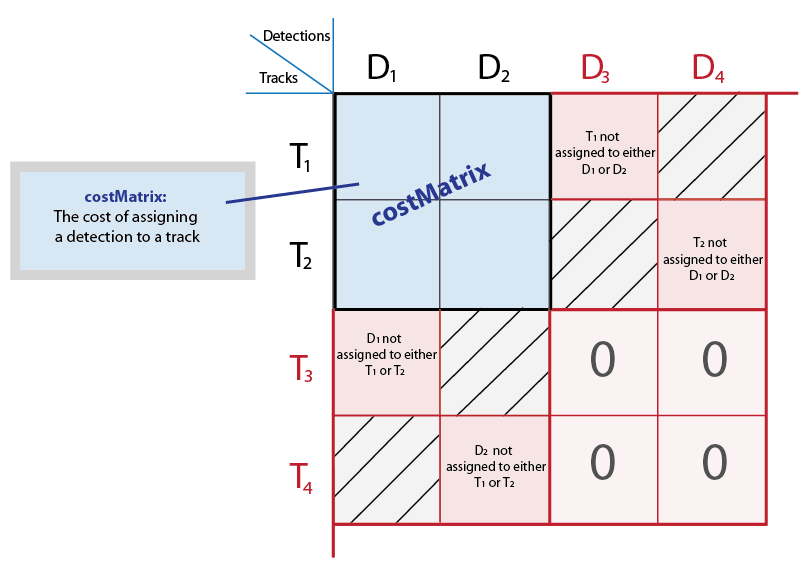
Типы данных: int8 | uint8 | int16 | uint16 | int32 | uint32 | single | double
costOfNonAssignment - Стоимость не присвоения обнаружения какой-либо дорожке или дорожке любому обнаружениюСтоимость не назначения обнаружения какой-либо дорожке или дорожке для обнаружения. Можно задать это значение как скалярное значение, представляющее стоимость дорожки или обнаружения, оставшегося неназначенным. Неназначенное обнаружение может стать началом новой дорожки. Если дорожка не назначена, объект не отображается. Чем выше costOfNonAssignment Значение, чем выше вероятность того, что каждой дорожке будет назначено обнаружение.
Внутренне эта функция заполняет матрицу затрат фиктивными строками и столбцами, чтобы учесть возможность неназначенных треков и обнаружений. Заполненные строки представляют обнаружения, не назначенные никаким трекам. Заполненные столбцы представляют дорожки, не связанные с обнаружениями. Чтобы применить одно и то же значение ко всем элементам как в строках, так и в столбцах, используйте синтаксис с costOfNonAssignment вход. Чтобы изменить значения для различных обнаружений или треков, используйте синтаксис с unassignedTrackCost и unassignedDetectionCost входы.
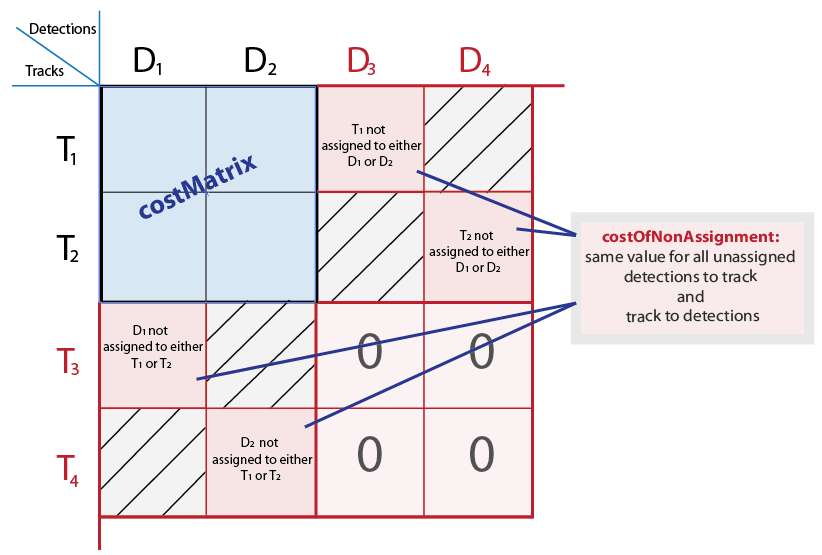
Типы данных: int8 | uint8 | int16 | uint16 | int32 | uint32 | single | double
unassignedTrackCost - Стоимость или вероятность неназначенного трекаСтоимость или вероятность неназначенного трека. Можно задать это значение как скалярное значение или M элемент, где M представляет количество дорожек. Для вектора M-element каждый элемент представляет стоимость не назначения никакого обнаружения этой дорожке. Скалярный вход представляет ту же стоимость неназначения для всех треков. Стоимость может варьироваться в зависимости от того, что вы знаете о каждом треке и сцене. Для примера, если объект собирается покинуть поле зрения, стоимость соответствующей дорожки, не назначенной, должна быть низкой.
Внутренне эта функция заполняет матрицу затрат фиктивными строками и столбцами, чтобы учесть возможность неназначенных треков и обнаружений. Заполненные строки представляют обнаружения, не назначенные никаким трекам. Заполненные столбцы представляют дорожки, не связанные с обнаружениями. Чтобы изменить значения для различных обнаружений или треков, используйте синтаксис с unassignedTrackCost и unassignedDetectionCost входы. Чтобы применить одно и то же значение ко всем элементам как в строках, так и в столбцах, используйте синтаксис с costOfNonAssignment вход.
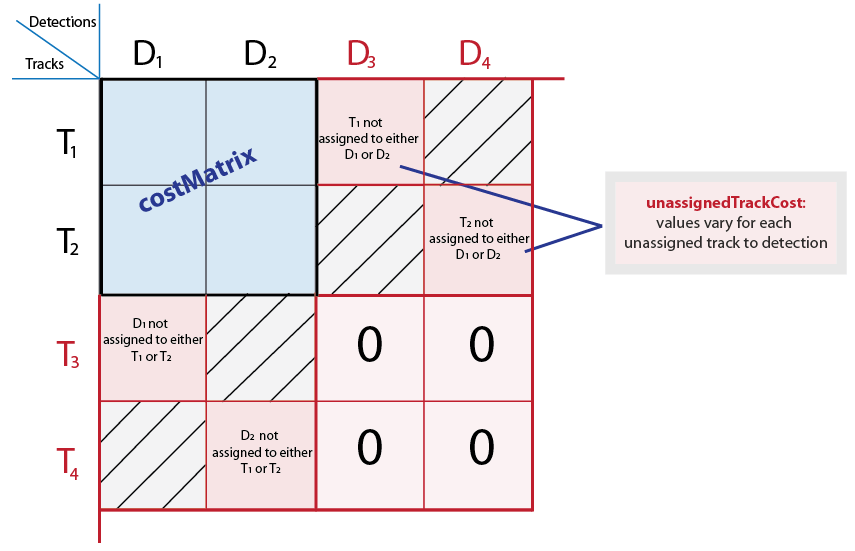
Типы данных: int8 | uint8 | int16 | uint16 | int32 | uint32 | single | double
unassignedDetectionCost - Стоимость неназначенного обнаруженияСтоимость неназначенного обнаружения, заданная в виде скалярного значения или вектора N-element, где N представляет количество обнаружений. Для вектора N - элемента каждый элемент представляет стоимость запуска новой дорожки для этого обнаружения. Скалярный вход представляет ту же стоимость неназначения для всех треков. Стоимость может варьироваться в зависимости от того, что вы знаете о каждом обнаружении и сцене. Для примера, если обнаружение появляется близко к ребру изображения, это, скорее всего, будет новый объект.
Внутренне эта функция заполняет матрицу затрат фиктивными строками и столбцами, чтобы учесть возможность неназначенных треков и обнаружений. Заполненные строки представляют обнаружения, не назначенные никаким трекам. Заполненные столбцы представляют дорожки, не связанные с обнаружениями. Чтобы изменить значения для различных обнаружений или треков, используйте синтаксис с unassignedTrackCost и unassignedDetectionCost входы. Чтобы применить одно и то же значение ко всем элементам как в строках, так и в столбцах, используйте синтаксис с costOfNonAssignment вход.
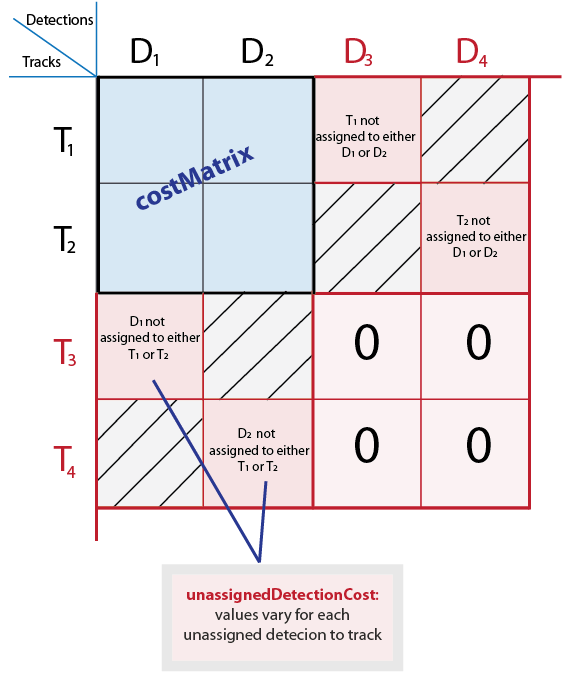
Типы данных: int8 | uint8 | int16 | uint16 | int32 | uint32 | single | double
[1] Miller, Matt L., Harold S. Stone, and Ingemar J. Cox, «Optimizing Method's Ranged Assignment Method», IEEE Transactions on Aerospace and Electronic Systems, 33 (3), 1997.
[2] Munkres, James, «Algorithms for Assignment and Transport Problems», Journal of the Society for Industrial and Applied Mathematics, Volume 5, Number 1, March, 1957.
