Чтобы интегрировать сгенерированное ядро процессора IP глубокого обучения в ваш системный исходный проект, используйте compile метод выходные параметры. compile метод:
Генерирует таблицу адресов внешней памяти.
Оптимизирует слоя сети для развертывания.
Сети разделений в меньшие серийные сети вызвали участки для развертывания.
Уменьшайте время, чтобы интегрировать сгенерированное ядро процессора IP глубокого обучения в ваш исходный проект при помощи compile таблица адресов внешней памяти метода. Используйте таблицу адресов для:
Загрузите входные параметры к ядру процессора IP глубокого обучения.
Загрузите инструкции по ядру процессора IP глубокого обучения.
Загрузите сетевые веса и смещения.
Получите результаты предсказания.
Таблица адресов внешней памяти состоит из этих смещений адреса:
InputDataOffset — Смещение адреса, где входные изображения загружаются.
OutputResultOffset — Выведите результаты, записаны, начав при этом смещении адреса.
SchedulerDataOffset — Смещение адреса, где данные об активации времени выполнения планировщика записаны. Данные об активации во время выполнения включают информацию те, которые передают между различными ядрами процессора глубокого обучения, инструкциями для различных ядер процессора глубокого обучения, и так далее.
SystemBufferOffset — Не используйте адрес памяти, запускающийся при этом смещении и заканчивающийся в начале InstructionDataOffset.
InstructionDataOffset — Все инструкции по настройке слоя (LC) записаны, начав при этом смещении адреса.
ConvWeightDataOffset — Все conv обработка весов модуля записаны, начав при этом смещении адреса.
FCWeightDataOffset — Весь полностью соединенный (FC), обрабатывающий веса модуля, записан, начав при этом смещении адреса.
EndOffset — Конец памяти DDR возмещен для сгенерированного процессора IP глубокого обучения.
Для примера сгенерированной таблицы адресов внешней памяти смотрите Компиляцию dagnet сетевой объект. Пример отображает карту внешней памяти, сгенерированную для сети распознавания ResNet-18 изображений и Xilinx® Zynq® Макетная плата UltraScale +™ MPSoC ZCU102 FPGA.
Оптимизируйте свое пользовательское развертывание нейронной сети для глубокого обучения путем идентификации слоев, которые можно выполнить в одной операции на оборудовании путем плавления этих слоев вместе. compile метод выполняет эти сплавы слоя и оптимизацию:
Слой нормализации партии. (batchNormalizationLayer) и 2D слой свертки (convolution2dLayer).
2D нулевой дополнительный слой (nnet.keras.layer.ZeroPadding2dLayer) и 2D слой свертки (convolution2dLayer).
2D нулевой дополнительный слой (nnet.keras.layer.ZeroPadding2dLayer) и 2D макс. слой опроса (maxPooling2dLayer).
Этот код выход является компиляторной оптимизацией в качестве примера в журнале компилятора.
Optimizing series network: Fused 'nnet.cnn.layer.BatchNormalizationLayer' into 'nnet.cnn.layer.Convolution2DLayer'
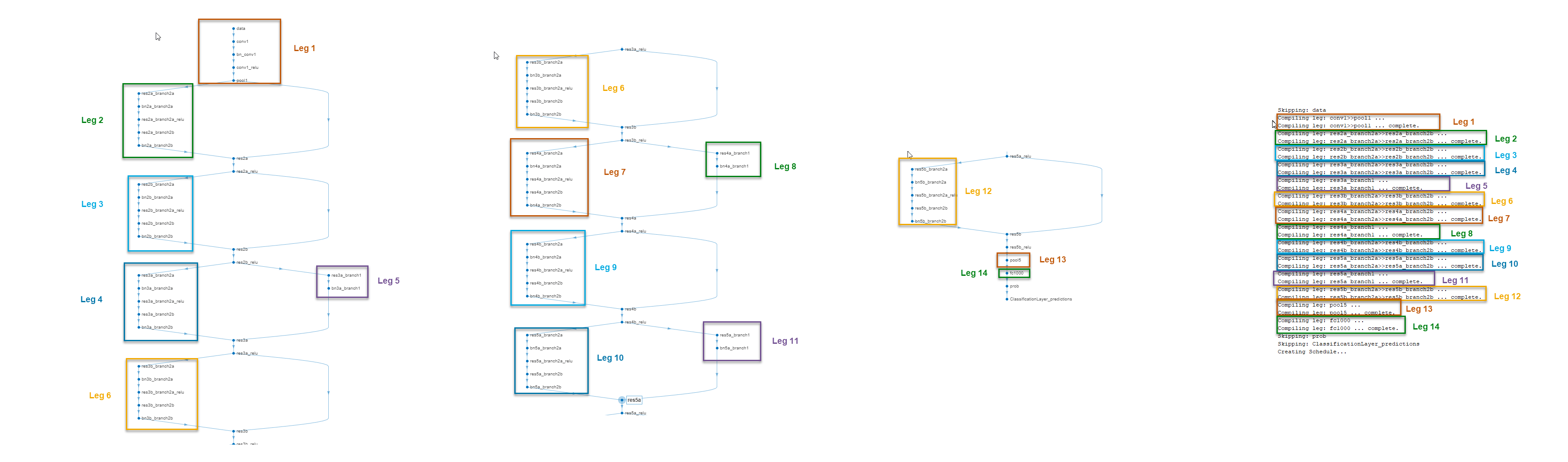
Идентифицируйте подмножества своих нейронных сетей для глубокого обучения, которые могли быть разделены в меньшие серийные сети, при помощи compile метод сгенерировал участки. Участок является подмножеством сети DAG, которую можно преобразовать в серийную сеть. compile функциональные группы участки на основе выходного формата слоев. Выходной формат слоя задан как формат данных процессорного модуля глубокого обучения, это обрабатывает тот слой. Выходной формат слоя является conv, ФК или сумматором. Например, в этом изображении, compile функциональные группы все слои в Leg 2 вместе, потому что у них есть conv выходной формат. Чтобы узнать о выходных форматах слоя, смотрите Поддерживаемые Слои.
Это изображение показывает участки сети ResNet-18, созданной compile функционируйте и те участки, подсвеченные на архитектуре слоя ResNet-18.