Можно сгенерировать одну инструкцию, несколько данных (SIMD) код от определенных блоков Simulink при помощи Intel SSE и, если у вас есть Embedded Coder®, Intel технология AVX. SIMD является вычислительной парадигмой, в которой одна инструкция обрабатывает несколько данных. Много современных процессоров имеют инструкции SIMD, которые, например, выполняют несколько сложений или умножения целиком. Для в вычислительном отношении интенсивных действий на поддерживаемых блоках внутренние параметры SIMD могут значительно улучшать производительность сгенерированного кода на платформах Intel.
Когда определенные условия соблюдают, можно сгенерировать код SIMD при помощи Intel SSE или Intel технология AVX. Эта таблица приводит блоки та поддержка генерация кода SIMD. Таблица также детализирует условия, при которых поддержка доступна.
| Блок | Условия |
|---|---|
| Add |
|
| Subtract |
|
| Product |
|
| Gain |
|
| Divide | Входной сигнал имеет тип данных single или double. |
| Sqrt | Входной сигнал имеет тип данных single или double. |
| Ceil |
|
| Floor |
|
| MinMax |
|
| MATLAB Function | Код MATLAB удовлетворяет условиям, заданным в этой теме: Сгенерируйте Код SIMD для функций MATLAB. |
| For Each Subsystem |
|
Если у вас есть DSP System Toolbox™, можно также сгенерировать код SIMD от определенных блоков DSP System Toolbox. Для получения дополнительной информации смотрите блоки Simulink в DSP System Toolbox который Поддержка Генерация кода SIMD (DSP System Toolbox).
В данном примере создайте простую модель simdDemo это имеет блок Subtract и блок Divide. Блок Subtract имеет входной сигнал, который имеет размерность 240 и тип входных данных single. Блок Divide имеет входной сигнал, который имеет размерность 140 и тип входных данных double.
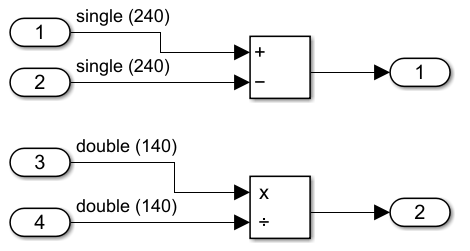
Простой сгенерированный код C для этой модели:
void simdDemo_step(void)
{
int32_T i;
for (i = 0; i < 240; i++) {
simdDemo_Y.Out1[i] = simdDemo_U.In1[i] - simdDemo_U.In2[i];
}
for (i = 0; i < 140; i++) {
simdDemo_Y.Out2[i] = simdDemo_U.In3[i] / simdDemo_U.In4[i];
}
}Сгенерировать код SIMD:
Откройте приложение Simulink Coder или приложение Embedded Coder.
Нажмите Settings> Hardware Implementation.
Установите параметр поставщика Устройства на Intel или AMD.
Установите параметр Типа устройства на x86-64(Windows 64) или x86-64(Linux 64).
На панели Optimization, для параметра расширений системы команд целевого компьютера Рычагов, выбирают расширение системы команд, которое поддерживает ваш процессор. Например, выберите SSE2. Если вы используете Embedded Coder, можно также выбрать из систем команд SSE, SSE4.1, AVX, AVX2, FMA, и AVX512F. Для получения дополнительной информации см. https://www.intel.com/content/www/us/en/support/articles/000005779/processors.html.
Сгенерируйте код из модели.
void simdDemo_step(void)
{
int32_T i;
for (i = 0; i <= 236; i += 4) {
_mm_storeu_ps(&simdDemo_Y.Out1[i], _mm_sub_ps(_mm_loadu_ps(&simdDemo_U.In1[i]),
_mm_loadu_ps(&simdDemo_U.In2[i])));
}
for (i = 0; i <= 138; i += 2) {
_mm_storeu_pd(&simdDemo_Y.Out2[i], _mm_div_pd(_mm_loadu_pd(&simdDemo_U.In3[i]),
_mm_loadu_pd(&simdDemo_U.In4[i])));
}
}
Этот код для SSE2 расширение системы команд. Инструкции SIMD являются встроенными функциями, которые начинают с идентификатора _mm. Эти функции обрабатывают несколько данных в одной итерации цикла, потому что цикл постепенно увеличивается четыре для одного типов данных и два для двойных типов данных. Для моделей, которые обрабатывают больше данных и в вычислительном отношении более интенсивны, чем этот, присутствие инструкций SIMD может значительно ускорить время выполнения кода.
Для списка Intel встроенные функции для поддерживаемых блоков Simulink см. https://software.intel.com/sites/landingpage/IntrinsicsGuide/.
Сгенерированный код не оптимизирован через SIMD если:
Код в блоке MATLAB Function содержит скалярные типы данных вне тела циклов. Например, если a,b, и c скаляры, сгенерированный код не оптимизирует операцию, такую как c=a+b.
Код в блоке MATLAB Function содержит косвенно индексные массивы или матрицы. Например, если A,B,C, и D векторы, сгенерированный код не векторизован для операции, такой как D(A)=C(A)+B(A).
Блоки в допускающей повторное использование подсистеме не могут быть оптимизированы.
Если код в блоке MATLAB Function содержит параллельные циклы for (parfor), parfor цикл не оптимизирован с кодом SIMD, но циклами в теле parfor цикл может быть оптимизирован с кодом SIMD.
Polyspace® не поддерживает анализ сгенерированного кода, который включает инструкции SIMD. Отключите генерацию кода SIMD путем установки параметра Leverage target hardware instruction set extensions на None.
