Найдите выбросы в данных
TF = isoutlier(A)true когда выброс обнаруживается в соответствующем элементе A. По умолчанию выброс является значением, которое является больше чем тремя масштабируемыми средними абсолютными отклонениями (MAD) далеко от медианы. Если A матрица или таблица, затем isoutlier работает с каждым столбцом отдельно. Если A многомерный массив, затем isoutlier действует по первому измерению, размер которого не равняется 1.
TF = isoutlier(A,movmethod,window)window. Например, isoutlier(A,'movmedian',5) возвращает true для всех элементов больше чем три локальных масштабированных MAD от локальной медианы в раздвижном окне, содержащем пять элементов.
TF = isoutlier(___,Name,Value)isoutlier(A,'SamplePoints',t) обнаруживает выбросы в A относительно соответствующих элементов временного вектора t.
Найдите выбросы в векторе из данных. Логическая единица в выходе указывает на местоположение выброса.
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57]; TF = isoutlier(A)
TF = 1x15 logical array
0 0 0 1 0 0 0 0 1 0 0 0 0 0 0
Задайте выбросы как точки больше чем три стандартных отклонения от среднего значения и найдите местоположения выбросов в векторе.
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57];
TF = isoutlier(A,'mean')TF = 1x15 logical array
0 0 0 0 0 0 0 0 1 0 0 0 0 0 0
Создайте вектор из данных, содержащих локальный выброс.
x = -2*pi:0.1:2*pi; A = sin(x); A(47) = 0;
Создайте временной вектор, который соответствует данным в A.
t = datetime(2017,1,1,0,0,0) + hours(0:length(x)-1);
Задайте выбросы как точки больше чем три локальных масштабированных MAD далеко от локальной медианы в раздвижном окне. Найдите местоположения выбросов в A относительно точек в t с размером окна 5 часов. Отобразите на графике данные и обнаруженные выбросы.
TF = isoutlier(A,'movmedian',hours(5),'SamplePoints',t); plot(t,A,t(TF),A(TF),'x') legend('Data','Outlier')

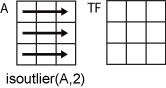
Найдите выбросы для каждой строки матрицы.
Создайте матрицу данных, содержащих выбросы по диагонали.
A = magic(5) + diag(200*ones(1,5))
A = 5×5
217 24 1 8 15
23 205 7 14 16
4 6 213 20 22
10 12 19 221 3
11 18 25 2 209
Найдите местоположения выбросов на основе данных в каждой строке.
TF = isoutlier(A,2)
TF = 5x5 logical array
1 0 0 0 0
0 1 0 0 0
0 0 1 0 0
0 0 0 1 0
0 0 0 0 1
Создайте вектор из данных, содержащих выброс. Найдите и постройте местоположение выброса, и пороги и центральное значение, определенное методом выброса. Центральное значение является медианой данных, и верхние и более низкие пороги являются тремя масштабируемыми MAD выше и ниже медианы.
x = 1:10; A = [60 59 49 49 58 100 61 57 48 58]; [TF,L,U,C] = isoutlier(A); plot(x,A,x(TF),A(TF),'x',x,L*ones(1,10),x,U*ones(1,10),x,C*ones(1,10)) legend('Original Data','Outlier','Lower Threshold','Upper Threshold','Center Value')

A — Входные данныеВходные данные в виде вектора, матрицы, многомерного массива, таблицы или расписания.
Если A таблица, затем ее переменные должны иметь тип double или single, или можно использовать 'DataVariables' пара "имя-значение", чтобы перечислить double или single переменные явным образом. Определение переменных полезно, когда вы работаете с таблицей, которая содержит переменные с типами данных кроме double или single.
Если A расписание, затем isoutlier работает только с табличными элементами. Времена строки должны быть уникальными и перечислены в порядке возрастания.
Типы данных: double | single | table | timetable
method — Метод для обнаружения выбросов'median' (значение по умолчанию) | 'mean' | 'quartiles' | 'grubbs' | 'gesd'Метод для обнаружения выбросов в виде одного из следующего:
| Метод | Описание |
|---|---|
'median' | Возвращает true для элементов больше чем три масштабируемых MAD от медианы. Масштабированный MAD задан как c*median(abs(A-median(A))), где c=-1/(sqrt(2)*erfcinv(3/2)). |
'mean' | Возвращает true для элементов больше чем три стандартных отклонения от среднего значения. Этот метод быстрее, но менее устойчив, чем 'median'. |
'quartiles' | Возвращает true для элементов больше чем 1,5 межквартильных размаха выше верхнего квартиля или ниже более низкого квартиля. Этот метод полезен когда данные в A не нормально распределено. |
'grubbs' | Применяет тест Граббса для выбросов, который удаляет один выброс на итерацию на основе тестирования гипотезы. Этот метод принимает что данные в A нормально распределено. |
'gesd' | Применяется обобщенные экстремальные Studentized отклоняют тест для выбросов. Этот итерационный метод похож на 'grubbs', но может выполнить лучше, когда существует несколько выбросов, маскирующих друг друга. |
threshold — Пороги процентилиПороги процентили в виде двухэлементного вектора-строки, элементы которого находятся в интервале [0,100]. Первый элемент указывает на более низкий порог процентили, и второй элемент указывает на верхний порог процентили. Например, порог [10 90] задает выбросы как точки ниже 10-й процентили и выше 90-й процентили. Первый элемент threshold должен быть меньше второго элемента.
movmethod — Движущийся метод'movmedian' | 'movmean'Движущийся метод для обнаружения выбросов в виде одного из следующего:
| Метод | Описание |
|---|---|
'movmedian' | Возвращает true для элементов больше чем три локальных масштабированных MAD от локальной медианы по длине окна заданы window. Этот метод также известен как Hampel filter. |
'movmean' | Возвращает true для элементов больше чем три локальных стандартных отклонения от локального среднего значения по длине окна заданы window. |
window — Длина окнаДлина окна в виде положительного целочисленного скаляра, двухэлементного вектора из положительных целых чисел, положительного скаляра длительности или двухэлементного вектора из положительной длительности.
Когда window положительный целочисленный скаляр, окно сосредоточено о текущем элементе и содержит window-1 граничение с элементами. Если window является четным, затем окно сосредоточено о текущих и предыдущих элементах.
Когда window двухэлементный вектор из положительных целых чисел [b f], окно содержит текущий элемент, b элементы назад и f элементы вперед.
Когда A расписание или 'SamplePoints' задан как datetime или duration вектор, затем window должен иметь тип duration, и окна вычисляются относительно точек выборки.
Типы данных: double | single | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | duration
dim — Размерность, которая задает направление расчетаВеличина для работы, заданная как положительный целый скаляр. Если значение не задано, то по умолчанию это первый размер массива, не равный 1.
Рассмотрите матричный A.
isoutlier(A,1) обнаруживает выбросы на основе данных в каждом столбце A.

isoutlier(A,2) обнаруживает выбросы на основе данных в каждой строке A.
Когда A таблица или расписание, dim не поддерживается. isoutlier действует вдоль каждой переменной таблицы или расписания отдельно.
Типы данных: double | single | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Задайте дополнительные разделенные запятой пары Name,Value аргументы. Name имя аргумента и Value соответствующее значение. Name должен появиться в кавычках. Вы можете задать несколько аргументов в виде пар имен и значений в любом порядке, например: Name1, Value1, ..., NameN, ValueN.
isoutlier(A,'mean','ThresholdFactor',4)rmoutliers | ischange | islocalmax | islocalmin | filloutliers | ismissing | Чистые данные о выбросе
