Если вы создали среду и агента обучения с подкреплением, можно обучить агента в среде с помощью train функция. Чтобы сконфигурировать ваше обучение, используйте rlTrainingOptions функция. Например, создайте набор опции обучения opt, и обучите агента agent в среде env.
opt = rlTrainingOptions(... 'MaxEpisodes',1000,... 'MaxStepsPerEpisode',1000,... 'StopTrainingCriteria',"AverageReward",... 'StopTrainingValue',480); trainStats = train(agent,env,opt);
Для получения дополнительной информации о создании агентов смотрите Агентов Обучения с подкреплением. Для получения дополнительной информации о создании сред смотрите, Создают Среды Обучения с подкреплением MATLAB и Создают Среды Обучения с подкреплением Simulink.
train обновляет агента, в то время как обучение прогрессирует. Чтобы сохранить исходные параметры агента для дальнейшего использования, сохраните агента в MAT-файл.
save("initialAgent.mat","agent")
Обучение завершает работу автоматически, когда условия вы задаете в StopTrainingCriteria и StopTrainingValue опции вашего rlTrainingOptions объекту удовлетворяют. Чтобы вручную отключить происходящее обучение, введите Ctrl+C или, в менеджере по Эпизоду Обучения с подкреплением, нажмите Stop Training. Поскольку train обновляет агента в каждом эпизоде, можно возобновить обучение путем вызова train(agent,env,trainOpts) снова, не теряя обученные параметры, изученные во время первого вызова train.
В общем случае обучение выполняет следующие шаги.
Инициализируйте агента.
Для каждого эпизода:
Сбросьте среду.
Получите начальное наблюдение s 0 средой.
Вычислите начальное действие a 0 = μ (s 0), где μ (s) является текущей политикой.
Установите текущее действие на начальное действие (a a0) и установите текущее наблюдение на начальное наблюдение (s s0).
В то время как эпизод не закончен или закончен, выполните следующие шаги.
Примените действие a к среде и получите следующее наблюдение s' 'and вознаграждение r.
Извлеките уроки из набора опыта (s, a, r, s').
Вычислите следующее действие a' = μ (s').
Обновите текущее действие со следующим действием (a ←a') и обновите текущее наблюдение со следующим наблюдением (s ←s').
Закончите эпизод, если условия завершения, заданные в среде, соблюдают.
Если учебное условие завершения соблюдают, оконечное обучение. В противном случае начните следующий эпизод.
Специфические особенности того, как программное обеспечение выполняет эти шаги, зависят от настройки агента и среды. Например, сброс среды в начале каждого эпизода может включать значения начального состояния рандомизации, если вы конфигурируете свою среду, чтобы сделать так. Для получения дополнительной информации об агентах и их алгоритмах настройки, смотрите Агентов Обучения с подкреплением. Чтобы использовать параллельную обработку и графические процессоры, чтобы ускорить обучение, смотрите, Обучают Агентов Используя Параллельные вычисления и графические процессоры.
По умолчанию, вызов train функция открывает менеджера по Эпизоду Обучения с подкреплением, который позволяет вам визуализировать процесс обучения. Менеджер по Эпизоду график показывает вознаграждение за каждый эпизод (EpisodeReward) и рабочее среднее премиальное значение (AverageReward). Кроме того, для агентов, которые имеют критиков, график показывает оценку критика обесцененного долгосрочного вознаграждения в начале каждого эпизода (EpisodeQ0). Менеджер по Эпизоду также отображает различный эпизод и учебную статистику. Можно также использовать train функционируйте, чтобы возвратить эпизод и учебную информацию.
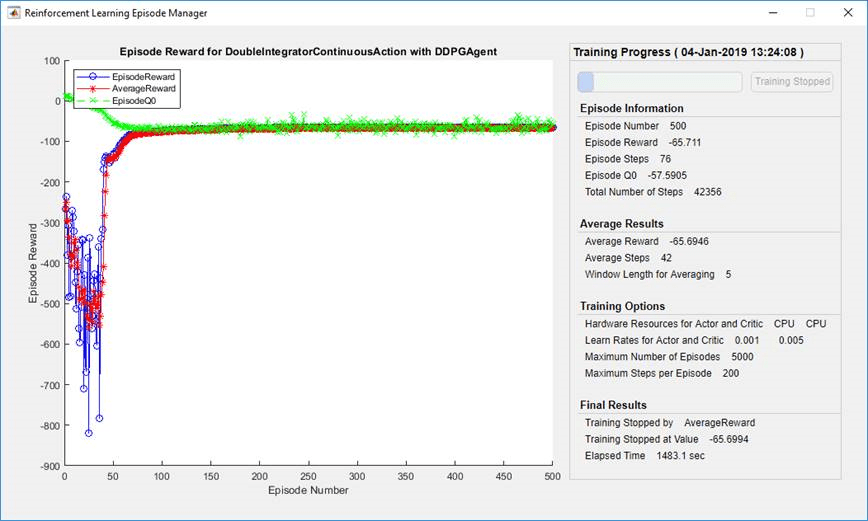
Для агентов с критиком Episode Q0 является оценкой обесцененного долгосрочного вознаграждения в начале каждого эпизода, учитывая начальное наблюдение за средой. В то время как обучение прогрессирует, если критик хорошо спроектирован. Episode Q0 приближается к истинному обесцененному долгосрочному вознаграждению, как показано на предыдущем рисунке.
Чтобы выключить менеджера по Эпизоду Обучения с подкреплением, установите Plots опция rlTrainingOptions к "none".
Во время обучения можно сохранить агентов кандидата, которые удовлетворяют условиям, которые вы задаете в SaveAgentCriteria и SaveAgentValue опции вашего rlTrainingOptions объект. Например, можно сохранить любого агента, вознаграждение эпизода которого превышает определенное значение, даже если полному условию для завершения обучения еще не удовлетворяют. Например, сохраните агентов, когда вознаграждение эпизода будет больше 100.
opt = rlTrainingOptions('SaveAgentCriteria',"EpisodeReward",'SaveAgentValue',100');
train хранит сохраненных агентов в MAT-файле в папке, вы задаете использование SaveAgentDirectory опция rlTrainingOptions. Сохраненные агенты могут быть полезными, например, чтобы протестировать агентов кандидата, сгенерированных во время продолжительного учебного процесса. Для получения дополнительной информации о сохранении критериев и сохранении местоположения, смотрите rlTrainingOptions.
После того, как обучение завершено, можно избавить обученного агента финала от MATLAB® рабочая область с помощью save функция. Например, сохраните агента myAgent к файлу finalAgent.mat в текущей рабочей директории.
save(opt.SaveAgentDirectory + "/finalAgent.mat",'agent')
По умолчанию, когда DDPG и агенты DQN сохранены, буферные данные об опыте не сохранены. Если вы планируете далее обучить своего сохраненного агента, можно начать обучение с буфера предыдущего опыта как начальная точка. В этом случае установите SaveExperienceBufferWithAgent опция к true. Для некоторых агентов, таких как те с большими буферами опыта и основанными на изображении наблюдениями, память, требуемая для сохранения буфера опыта, является большой. В этих случаях необходимо гарантировать, что достаточно памяти доступно для сохраненных агентов.
Чтобы подтвердить вашего обученного агента, можно симулировать агента в учебной среде с помощью sim функция. Чтобы конфигурировать моделирование, использовать rlSimulationOptions.
При проверке агента рассмотрите проверку, как агент обрабатывает следующее:
Изменения в начальных условиях симуляции — Чтобы изменить начальные условия модели, измените функцию сброса для среды. Например, сбросьте функции, смотрите, Создают Среду MATLAB Используя Пользовательские Функции, Создают Пользовательскую Среду MATLAB из Шаблона и Создают Среды Обучения с подкреплением Simulink.
Несоответствия между обучением и динамикой среды симуляции — Чтобы проверять такие несоответствия, создайте тестовые среды таким же образом, что вы создали учебную среду, изменив поведение среды.
Как с параллельным обучением, если у вас есть программное обеспечение Parallel Computing Toolbox™, можно запустить несколько параллельных симуляций на многоядерных компьютерах. Если у вас есть программное обеспечение MATLAB Parallel Server™, можно запустить несколько параллельных симуляций на ресурсах облака или компьютерных кластерах. Для получения дополнительной информации о конфигурировании вашего моделирования, чтобы использовать параллельные вычисления, смотрите UseParallel и ParallelizationOptions \in rlSimulationOptions.
Если ваша учебная среда реализует plot метод, можно визуализировать поведение среды во время обучения и симуляции. Если вы вызываете plot(env) перед обучением или симуляцией, где env ваш объект среды, затем обновления визуализации во время обучения позволить вам визуализировать прогресс каждого эпизода или симуляции.
Визуализация среды не поддерживается когда обучение или симуляция вашего агента с помощью параллельных вычислений.
Для пользовательских сред необходимо реализовать собственное plot метод. Для получения дополнительной информации о создании пользовательские среды с a plot функционируйте, смотрите, Создают Пользовательскую Среду MATLAB из Шаблона.
