Цель обучения с подкреплением состоит в том, чтобы настроить агента для выполнения задачи в неопределенном окружении. Агент получает наблюдения и вознаграждение от окружения и посылает туда действия. Вознаграждение является мерой того, насколько успешно действие относительно выполнения цели задачи.
Агент содержит два компонента: политика и алгоритм обучения.
Политика является отображением, которое выбирает действия на основе наблюдений от среды. Как правило, политика представляет собой аппроксимирующую функцию с настраиваемыми параметрами, например, глубокую нейронную сеть.
Алгоритм обучения постоянно обновляет параметры политики на основе действий, наблюдений и вознаграждений. Цель алгоритма обучения состоит в том, чтобы найти оптимальную политику, которая максимизирует ожидаемое совокупное долгосрочное вознаграждение, полученное во время задачи.
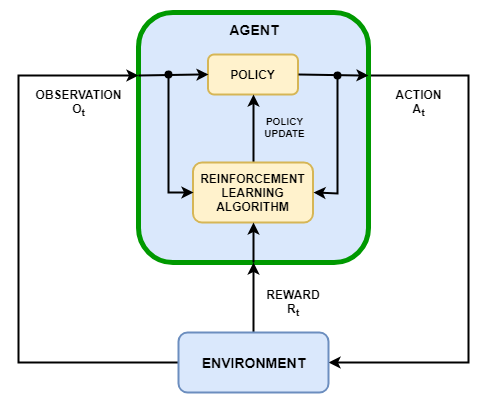
В зависимости от алгоритма обучения агент поддерживает одну или несколько параметризованных функциональных аппроксимаций для настройки политики. Аппроксимации могут использоваться двумя способами.
Критики — Для заданного наблюдения и действия, критик возвращает, как выведено ожидаемое значение совокупного долгосрочного вознаграждения за задачу.
Агент — Для заданного наблюдения, агент возвращает, как выведено действие, которое максимизирует ожидаемое совокупное долгосрочное вознаграждение.
Агенты, которые используют только критиков, чтобы выбрать их действия, используют косвенное представление политики. Эти агенты также упоминаются как основанные на значении, и они используют аппроксимацию, чтобы представлять функцию ценности или Q-функцию-ценности. В общем случае эти агенты работают лучше с дискретными пространствами действий, но могут стать в вычислительном отношении дорогими для непрерывных пространств действий.
Агенты, которые используют только агентов, чтобы выбрать их действия, используют прямое представление политики. Эти агенты также упоминаются как основанные на политике. Политика может быть или детерминированной или стохастической. В общем случае эти агенты более просты и могут обработать непрерывные пространства действий, хотя алгоритм настройки может быть чувствителен к шумному измерению и может сходиться на локальных минимумах.
Агенты, которые используют и агента и критика, упоминаются как агенты критика агента. В этих агентах, во время обучения, агент изучает лучшее действие, чтобы взять обратную связь использования от критика (вместо того, чтобы использовать вознаграждение непосредственно). В то же время критик узнает о функции ценности из вознаграждений так, чтобы она могла правильно подвергнуть критике агента. В общем случае эти агенты могут обработать и дискретный и непрерывные пространства действий.
Программное обеспечение Reinforcement Learning Toolbox™ предоставляет следующих встроенных агентов. Можно обучить этих агентов в средах или с непрерывными или с дискретными пространствами наблюдений и следующими пространствами действий.
Следующие таблицы обобщают типы, пространства действий и представления для всех встроенных агентов. Для каждого агента пространство наблюдений может быть или дискретным или непрерывным.
Встроенные агенты: тип и пространство действий
| Агент | Ввод | Пространство действий |
|---|---|---|
| Агенты Q-обучения (Q) | Основанный на значении | Дискретный |
| Глубокие агенты Q-сети (DQN) | Основанный на значении | Дискретный |
| Агенты SARSA | Основанный на значении | Дискретный |
| Агенты градиента политики (PG) | Основанный на политике | Дискретный или непрерывный |
| Агенты критика агента (AC) | Критик агента | Дискретный или непрерывный |
| Ближайшие агенты оптимизации политики (PPO) | Критик агента | Дискретный или непрерывный |
| Доверительные агенты оптимизации политики области | Критик агента | Дискретный или непрерывный |
| Глубоко детерминированные агенты градиента политики (DDPG) | Критик агента | Непрерывный |
| Задержанный близнецами глубоко детерминированные агенты градиента политики (TD3) | Критик агента | Непрерывный |
| Мягкие агенты критика агента (SAC) | Критик агента | Непрерывный |
Встроенные Агенты: Представления, которые Необходимо Использовать с Каждым Агентом
| Представление | Q, DQN, SARSA | PG | AC, PPO, TRPO | МЕШОЧЕК | DDPG, TD3 |
|---|---|---|---|---|---|
V критика функции ценности (S), который вы создаете использование | X (если базовая линия используется), | X | |||
Q критика Q-функции-ценности (S, A), который вы создаете использование | X | X | X | ||
Детерминированный π агента политики (S), который вы создаете использование | X | ||||
Стохастический π агента политики (S), который вы создаете использование | X | X | X |
Агент с сетями по умолчанию — Все агенты кроме агентов Q-обучения и SARSA поддерживает сети по умолчанию для агентов и критиков. Можно создать агента с представлениями актёра и критика по умолчанию на основе спецификаций наблюдений и спецификаций действия от среды. Для этого в MATLAB® командная строка, выполните следующие шаги.
Создайте спецификации наблюдений для своей среды. Если у вас уже есть объект интерфейса среды, можно получить эти технические требования использование getObservationInfo.
Технические требования действия по созданию для вашей среды. Если у вас уже есть объект интерфейса среды, можно получить эти технические требования использование getActionInfo.
В случае необходимости задайте количество нейронов в каждом learnable слое или использовать ли слой LSTM. Для этого создайте объект опции инициализации агента использование rlAgentInitializationOptions.
В случае необходимости задайте опции агента путем создания набора объекта опций для определенного агента.
Создайте агента с помощью соответствующей функции создания агента. Получившийся агент содержит соответствующие представления актёра и критика, перечисленные в таблице выше. Агент и критик используют специфичные для агента глубокие нейронные сети по умолчанию в качестве внутренних аппроксимаций.
Для получения дополнительной информации о создании функциональных аппроксимаций актёра и критика смотрите, Создают Представления Функции ценности и политика.
Можно использовать приложение Reinforcement Learning Designer, чтобы импортировать существующую среду и в интерактивном режиме спроектировать DQN, DDPG, PPO или агентов TD3. Приложение позволяет вам обучать и симулировать агента в своей среде, анализировать результаты симуляции, совершенствовать параметры агента и экспортировать агента в рабочее пространство MATLAB для дальнейшего использования и развертывания. Для получения дополнительной информации смотрите, Создают Агентов Используя Reinforcement Learning Designer.
При выборе агента лучшая практика должна запуститься с более простого (и быстрее обучаться) алгоритм, который совместим с пространствами действий и пространствами наблюдений. Можно затем попробовать прогрессивно более сложные алгоритмы, если более простые единицы не выполняют, как желаемый.
Дискретное действие и пространства наблюдений — Для сред с дискретным действием и пространствами наблюдений, агенты Q-обучения и SARSA являются самым простым совместимым агентом, сопровождаемым DQN, PPO и TRPO.

Дискретное пространство действий и непрерывное пространство наблюдений — Для сред с дискретным пространством действий и непрерывным пространством наблюдений, DQN является самым простым совместимым агентом, сопровождаемым PPO и затем TRPO.

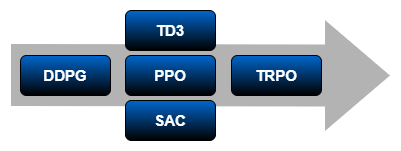
Непрерывное пространство действий — Для сред и с непрерывным действием и с пространством наблюдений, DDPG является самым простым совместимым агентом, сопровождаемым TD3, PPO и SAC, которые затем сопровождаются TRPO. Для таких сред попробуйте DDPG сначала. В целом:
TD3 является улучшенной, более комплексной версией DDPG.
PPO имеет более устойчивые обновления, но требует большего количества обучения.
SAC является улучшенной, более комплексной версией DDPG, который генерирует стохастические политики.
TRPO является более комплексной версией PPO, который более устойчив для детерминированных сред с меньшим количеством наблюдений.
Можно также обучить политики с помощью других алгоритмов обучения путем создания пользовательского агента. Для этого вы создаете подкласс пользовательского класса агента и задаете поведение агента с помощью набора необходимых и дополнительных методов. Для получения дополнительной информации смотрите, Создают Пользовательских Агентов Обучения с подкреплением.
rlACAgent | rlDDPGAgent | rlDQNAgent | rlPGAgent | rlPPOAgent | rlQAgent | rlSACAgent | rlSARSAAgent | rlTD3Agent | rlTRPOAgent
