Факторный анализ
factoran вычисляет оценку наибольшего правдоподобия (MLE) матрицы факторных нагрузок Λ в модели факторного анализа
где x является вектором из наблюдаемых переменных, μ является постоянным вектором из средних значений, Λ является постоянный d- m матрица факторных нагрузок, f является вектором из независимых, стандартизированных общих множителей, и e является вектором из независимых специфических факторов. x, μ и e у каждого есть длина d. f имеет длину m.
В качестве альтернативы модель факторного анализа может быть задана как
где d- d диагональная матрица определенных отклонений.
Для использования factoran и его отношение к pca, смотрите Выполняют Факторный анализ Классов Экзамена.
___ = factoran( изменяет подгонку модели и выходные параметры с помощью одного или нескольких аргументов пары "имя-значение", для любых выходных аргументов в предыдущих синтаксисах. Например, можно указать что X,m,Name,Value)X данные являются ковариационной матрицей.
Создайте некоторые псевдослучайные необработанные данные.
rng default % For reproducibility n = 100; X1 = 5 + 3*rand(n,1); % Factor 1 X2 = 20 - 5*rand(n,1); % Factor 2
Создайте шесть векторов данных из необработанных данных и добавьте случайный шум.
Y1 = 2*X1 + 3*X2 + randn(n,1); Y2 = 4*X1 + X2 + 2*randn(n,1); Y3 = X1 - X2 + 3*randn(n,1); Y4 = -2*X1 + 4*X2 + 4*randn(n,1); Y5 = 3*(X1 + X2) + 5*randn(n,1); Y6 = X1 - X2/2 + 6*randn(n,1);
Создайте матрицу данных из векторов данных.
X = [Y1,Y2,Y3,Y4,Y5,Y6];
Извлеките эти два фактора из матрицы зашумленных данных X использование factoran. Отобразите выводы.
m = 2; [lambda,psi,T,stats,F] = factoran(X,m); disp(lambda)
0.8666 0.4828
0.8688 -0.0998
-0.0131 -0.5412
0.2150 0.8458
0.7040 0.2678
-0.0806 -0.2883
disp(psi)
0.0159
0.2352
0.7070
0.2385
0.4327
0.9104
disp(T)
0.8728 0.4880
0.4880 -0.8728
disp(stats)
loglike: -0.0531
dfe: 4
chisq: 5.0335
p: 0.2839
disp(F(1:10,:))
1.8845 -0.6568
-0.1714 -0.8113
-1.0534 2.0743
1.0390 -1.1784
0.4309 0.9907
-1.1823 0.6570
-0.2129 1.1898
-0.0844 -0.7421
0.5854 -1.1379
0.8279 -1.9624
Просмотрите корреляционную матрицу данных.
corrX = corr(X)
corrX = 6×6
1.0000 0.7047 -0.2710 0.5947 0.7391 -0.2126
0.7047 1.0000 0.0203 0.1032 0.5876 0.0289
-0.2710 0.0203 1.0000 -0.4793 -0.1495 0.1450
0.5947 0.1032 -0.4793 1.0000 0.3752 -0.2134
0.7391 0.5876 -0.1495 0.3752 1.0000 -0.2030
-0.2126 0.0289 0.1450 -0.2134 -0.2030 1.0000
Сравните corrX к его соответствующим значениям, возвращенным factoran, lambda*lambda' + diag(psi).
C0 = lambda*lambda' + diag(psi)
C0 = 6×6
1.0000 0.7047 -0.2726 0.5946 0.7394 -0.2091
0.7047 1.0000 0.0426 0.1023 0.5849 -0.0413
-0.2726 0.0426 1.0000 -0.4605 -0.1542 0.1571
0.5946 0.1023 -0.4605 1.0000 0.3779 -0.2611
0.7394 0.5849 -0.1542 0.3779 1.0000 -0.1340
-0.2091 -0.0413 0.1571 -0.2611 -0.1340 1.0000
factoran получает lambda и psi это соответствует тесно корреляционной матрице исходных данных.
Просмотрите результаты, не используя вращение.
[lambda,psi,T,stats,F] = factoran(X,m,'Rotate','none'); disp(lambda)
0.9920 0.0015
0.7096 0.5111
-0.2755 0.4659
0.6004 -0.6333
0.7452 0.1098
-0.2111 0.2123
disp(psi)
0.0159
0.2352
0.7070
0.2385
0.4327
0.9104
disp(T)
1 0
0 1
disp(stats)
loglike: -0.0531
dfe: 4
chisq: 5.0335
p: 0.2839
disp(F(1:10,:))
1.3243 1.4929
-0.5456 0.6245
0.0928 -2.3246
0.3318 1.5356
0.8596 -0.6544
-0.7114 -1.1504
0.3947 -1.1424
-0.4358 0.6065
-0.0444 1.2789
-0.2350 2.1169
Вычислите факторы с помощью только ковариационную матрицу X.
X2 = cov(X); [lambda2,psi2,T2,stats2] = factoran(X2,m,'Xtype','covariance','Nobs',n)
lambda2 = 6×2
0.8666 0.4828
0.8688 -0.0998
-0.0131 -0.5412
0.2150 0.8458
0.7040 0.2678
-0.0806 -0.2883
psi2 = 6×1
0.0159
0.2352
0.7070
0.2385
0.4327
0.9104
T2 = 2×2
0.8728 0.4880
0.4880 -0.8728
stats2 = struct with fields:
loglike: -0.0531
dfe: 4
chisq: 5.0335
p: 0.2839
Результаты эквивалентны с необработанными данными, кроме factoran не может вычислить факторную матрицу баллов F для данных о ковариации.
Загрузите выборочные данные.
load carbigЗадайте переменную матрицу.
X = [Acceleration Displacement Horsepower MPG Weight]; X = X(all(~isnan(X),2),:);
Оцените факторные нагрузки с помощью минимального предсказания среднеквадратической ошибки для факторного анализа с двумя общими множителями.
[Lambda,Psi,T,stats,F] = factoran(X,2,'Scores','regression'); inv(T'*T); % Estimated correlation matrix of F, == eye(2) Lambda*Lambda' + diag(Psi); % Estimated correlation matrix Lambda*inv(T); % Unrotate the loadings F*T'; % Unrotate the factor scores
Создайте побочную сюжетную линию двух факторов.
biplot(Lambda,'LineWidth',2,'MarkerSize',20)

Оцените факторные нагрузки с помощью ковариации (или корреляция) матрица.
[Lambda,Psi,T] = factoran(cov(X),2,'Xtype','covariance')
Lambda = 5×2
-0.2432 -0.8500
0.8773 0.3871
0.7618 0.5930
-0.7978 -0.2786
0.9692 0.2129
Psi = 5×1
0.2184
0.0804
0.0680
0.2859
0.0152
T = 2×2
0.9476 0.3195
0.3195 -0.9476
(Вы могли вместо этого использовать corrcoef(X) вместо cov(X) создать данные для factoran.) Несмотря на то, что оценки являются тем же самым, использование ковариационной матрицы, а не необработанных данных препятствует тому, чтобы вы запросили уровень значения или баллы.
Используйте промакс. вращение.
[Lambda,Psi,T,stats,F] = factoran(X,2,'Rotate','promax','power',4); inv(T'*T) % Estimated correlation of F, no longer eye(2)
ans = 2×2
1.0000 -0.6391
-0.6391 1.0000
Lambda*inv(T'*T)*Lambda'+diag(Psi) % Estimated correlation of Xans = 5×5
1.0000 -0.5424 -0.6893 0.4309 -0.4167
-0.5424 1.0000 0.8979 -0.8078 0.9328
-0.6893 0.8979 1.0000 -0.7730 0.8647
0.4309 -0.8078 -0.7730 1.0000 -0.8326
-0.4167 0.9328 0.8647 -0.8326 1.0000
Постройте невращаемые переменные с наклонными наложенными осями.
invT = inv(T); Lambda0 = Lambda*invT; figure() line([-invT(1,1) invT(1,1) NaN -invT(2,1) invT(2,1)], ... [-invT(1,2) invT(1,2) NaN -invT(2,2) invT(2,2)], ... 'Color','r','LineWidth',2) grid on hold on biplot(Lambda0,'LineWidth',2,'MarkerSize',20) xlabel('Loadings for unrotated Factor 1') ylabel('Loadings for unrotated Factor 2')

Постройте вращаемые переменные против наклонных осей.
figure() biplot(Lambda,'LineWidth',2,'MarkerSize',20)

[1] Харман, Гарри Гораций. Современный факторный анализ. 3-й Эд. Чикаго: нажатие Чикагского университета, 1976.
[2] Jöreskog, K. G. “Некоторые Вклады в Факторный анализ Наибольшего правдоподобия”. Psychometrika 32, № 4 (декабрь 1967): 443–82. https://doi.org/10.1007/BF02289658
[3] Lawley, D. N. и А. Э. Максвелл. Факторный анализ как статистический метод. 2-й Эд. Нью-Йорк: American Elsevier Publishing Co., 1971.
pcacov и factoran не работайте непосредственно над длинными массивами. Вместо этого используйте C = gather(cov(X)) вычислить ковариационную матрицу длинного массива. Затем можно использовать pcacov или factoran работать над ковариационной матрицей в оперативной памяти. В качестве альтернативы можно использовать pca непосредственно на длинном массиве.
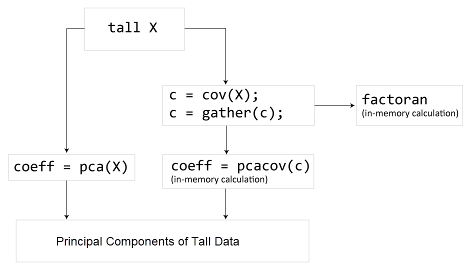
Для получения дополнительной информации смотрите Длинные массивы для Данных, которые не помещаются в память.
biplot | pca | procrustes | pcacov | rotatefactors | statset
