Оцените ключевые возможности по критериям отделимости класса
[IDX, Z]
= rankfeatures(X, Group)
[IDX, Z]
= rankfeatures(X, Group,
...'Criterion', CriterionValue, ...)
[IDX, Z]
= rankfeatures(X, Group,
...'CCWeighting', ALPHA, ...)
[IDX, Z]
= rankfeatures(X, Group,
...'NWeighting', BETA, ...)
[IDX, Z]
= rankfeatures(X, Group,
...'NumberOfIndices', N, ...)
[IDX, Z]
= rankfeatures(X, Group,
...'CrossNorm', CN, ...)
[ оценивает функции в IDX, Z]
= rankfeatures(X, Group)X с помощью независимого критерия оценки бинарной классификации. X является матрицей, где каждый столбец является наблюдаемым вектором, и количество строк соответствует исходному количеству функций. Group содержит метки класса.
IDX является списком индексов к строкам в X со старшими значащими функциями. Z является абсолютным значением используемого критерия (см. ниже).
Group может быть числовым вектором, массивом ячеек из символьных векторов или представить вектор в виде строки; numel(Group) совпадает с количеством столбцов в X, и numel(unique(Group)) равен 2.
[IDX, Z] = rankfeatures(X, Group, ...'PropertyName', PropertyValue, ...) rankfeatures с дополнительными свойствами, которые используют имя свойства / пары значения свойства. Можно задать одно или несколько свойств в любом порядке. Каждый PropertyName должен быть заключен в одинарные кавычки и нечувствительный к регистру. Это имя свойства / пары значения свойства следующие:
[ устанавливает критерий, используемый, чтобы оценить значение каждой функции разделения двух маркированных групп. Выбор:IDX, Z]
= rankfeatures(X, Group,
...'Criterion', CriterionValue, ...)
'ttest' (значение по умолчанию) — 2D демонстрационный t-тест абсолютного значения с объединенной оценкой отклонения.
'entropy' — Относительная энтропия, также известная как расстояние Kullback-Leibler или расхождение.
'bhattacharyya' — Минимальная достижимая ошибка классификации или Чернофф связаны.
'roc' — Область между эмпирической рабочей характеристикой получателя (ROC) изгибается и случайный наклон классификатора.
'wilcoxon' — Абсолютное значение стандартизированной u-статистической-величины 2D демонстрационного непарного теста Wilcoxon, также известного как Манна-Уитни.
'ttest', 'entropy' и 'bhattacharyya' принимают нормальные распределенные классы, в то время как 'roc' и 'wilcoxon' являются непараметрическими тестами. Все тесты являются независимой функцией.
[ информация о корреляции использования, чтобы перевесить значение IDX, Z]
= rankfeatures(X, Group,
...'CCWeighting', ALPHA, ...)Z потенциальных функций с помощью Z * (1-ALPHA*(RHO))RHO является средним значением абсолютных значений коэффициента взаимной корреляции между функцией кандидата и всеми ранее выбранными функциями. ALPHA устанавливает фактор взвешивания. Это - скалярное значение между 0 и 1. Когда ALPHA является 0 потенциальные функции (по умолчанию) не взвешиваются. Большое значение RHO (близко к 1) перевешивает статистическую величину значения; это означает, что показывает, которые высоко коррелируются с функциями, уже выбранными, менее вероятно, будут включены в список выводов.
[ использует региональную информацию, чтобы перевесить значение IDX, Z]
= rankfeatures(X, Group,
...'NWeighting', BETA, ...)Z потенциальных функций с помощью Z * (1-exp(-(DIST/BETA).^2))DIST является расстоянием (в строках) между функцией кандидата и ранее выбранными функциями. BETA устанавливает фактор взвешивания. Это больше, чем или равно 0. Когда BETA является 0 потенциальные функции (по умолчанию) не взвешиваются. Маленький DIST (близко к 0) перевешивает статистику значения только близких функций. Это означает, что показывает, которые являются близко к уже выбранным функциям, менее вероятно, будут включены в список выводов. Эта опция полезна для извлечения функций от временных рядов с временной корреляцией.
BETA может также быть функцией местоположения функции, заданное использование @ или анонимная функция. В обоих случаях rankfeatures передает положение строки функции к BETA() и ожидает назад значение, больше, чем или равный 0.
Можно использовать 'CCWeighting' и 'NWeighting' вместе.
[ определяет номер выходных индексов в IDX, Z]
= rankfeatures(X, Group,
...'NumberOfIndices', N, ...)IDX. Значение по умолчанию совпадает с количеством функций, когда ALPHA и BETA является 0 или 20 в противном случае.
[ применяет независимую нормализацию через наблюдения для каждой функции. Перекрестная нормализация гарантирует сопоставимость среди различных функций, несмотря на то, что это не всегда необходимо, потому что выбранный критерий может уже составлять это. Выбор:IDX, Z]
= rankfeatures(X, Group,
...'CrossNorm', CN, ...)
'none' (значение по умолчанию) — Интенсивность не перекрестный нормирована.
'meanvar' — x_new = (x - mean(x))/std(x)
'softmax' — x_new = (1+exp((mean(x)-x)/std(x)))^-1
'minmax' — x_new = (x - min(x))/(max(x)-min(x))
Найдите уменьшаемый набор генов, который достаточен для дифференциации ячеек рака молочной железы от всех других типов рака в t-матричном NCI60 наборе данных. Загрузка демонстрационных данных.
load NCI60tmatrixПолучите логический индексный вектор к ячейкам рака молочной железы.
BC = GROUP == 8;
Выберите функции.
I = rankfeatures(X,BC,'NumberOfIndices',12);Протестируйте функции с линейным дискриминантным классификатором.
C = classify(X(I,:)',X(I,:)',double(BC)); cp = classperf(BC,C); cp.CorrectRate
ans =
1Используйте взвешивание взаимной корреляции, чтобы далее сократить необходимое количество генов.
I = rankfeatures(X,BC,'CCWeighting',0.7,'NumberOfIndices',8); C = classify(X(I,:)',X(I,:)',double(BC)); cp = classperf(BC,C); cp.CorrectRate
ans =
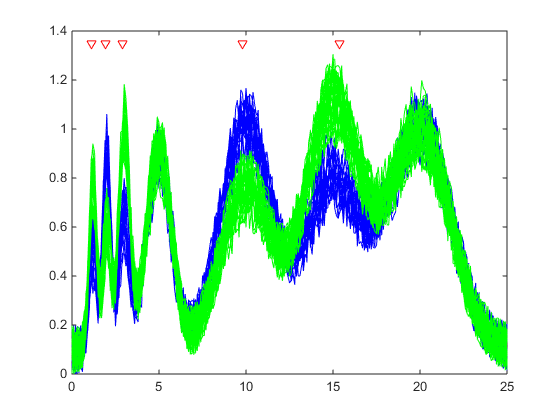
1Найдите дискриминантный peaks двух групп сигналов с Гауссовыми импульсами модулируемым двумя другими источниками.
load GaussianPulses f = rankfeatures(y',grp,'NWeighting',@(x) x/10+5,'NumberOfIndices',5); plot(t,y(grp==1,:),'b',t,y(grp==2,:),'g',t(f),1.35,'vr')
[1] Theodoridis, S. и Koutroumbas, K. (1999). Распознавание образов, Academic Press, 341-342.
[2] Лю, H., Motoda, H. (1998). Покажите выбор для открытия знаний и анализа данных, Kluwer академические издатели.
[3] Росс, D.T. et.al. (2000). Систематическое изменение в шаблонах экспрессии гена в человеческих линиях раковых клеток. Генетика природы. 24 (3), 227-235.
classify | classperf | crossvalind | randfeatures | sequentialfs
