Подходящие модели мультикласса для машин вектора поддержки или других классификаторов
Mdl = fitcecoc(Tbl,ResponseVarName)Mdl = fitcecoc(Tbl,formula)Mdl = fitcecoc(Tbl,Y)Mdl = fitcecoc(X,Y)Mdl = fitcecoc(___,Name,Value)[Mdl,HyperparameterOptimizationResults]
= fitcecoc(___,Name,Value)Mdl = fitcecoc(Tbl,ResponseVarName)Tbl и меток класса в Tbl.ResponseVarName. fitcecoc использует K (K – 1)/2 бинарные модели машины вектора поддержки (SVM) с помощью одного по сравнению с одного кодирующего проекта, где K является количеством уникальных (уровней) меток класса. Mdl является моделью ClassificationECOC.
Mdl = fitcecoc(___,Name,Value)Name,Value, с помощью любого из предыдущих синтаксисов.
Например, задайте различных бинарных учеников, различный проект кодирования, или перекрестный подтверждать. Это - хорошая практика, чтобы перекрестный подтвердить использование аргумента пары Name,Value Kfold. Результаты перекрестной проверки определяют, как хорошо модель делает вывод.
[ также возвращает детали гипероптимизации параметров управления, когда вы задаете аргумент пары "имя-значение" Mdl,HyperparameterOptimizationResults]
= fitcecoc(___,Name,Value)OptimizeHyperparameters и используете линейный или двоичные ученики ядра. Для другого Learners свойство HyperparameterOptimizationResults Mdl содержит результаты.
Обучите модель выходных кодов с коррекцией ошибок (ECOC) мультикласса использование двоичных учеников машины вектора поддержки (SVM).
Загрузите ирисовый набор данных Фишера. Задайте данные о предикторе X и данные об ответе Y.
load fisheriris
X = meas;
Y = species;Обучите мультикласс модель ECOC с помощью опций по умолчанию.
Mdl = fitcecoc(X,Y)
Mdl =
ClassificationECOC
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3x1 cell}
CodingName: 'onevsone'
Properties, Methods
Mdl является моделью ClassificationECOC. По умолчанию fitcecoc использует бинарных учеников SVM и один по сравнению с один кодирующий проект. Можно получить доступ к свойствам Mdl с помощью записи через точку.
Отобразите имена классов и матрицу проекта кодирования.
Mdl.ClassNames
ans = 3x1 cell array
{'setosa' }
{'versicolor'}
{'virginica' }
CodingMat = Mdl.CodingMatrix
CodingMat = 3×3
1 1 0
-1 0 1
0 -1 -1
Один по сравнению с один кодирующий проект для трех классов приводит к трем бинарным ученикам. Столбцы CodingMat соответствуют ученикам, и строки соответствуют классам. Порядок класса совпадает с порядком в Mdl.ClassNames. Например, CodingMat(:,1) является [1; –1; 0] и указывает, что программное обеспечение обучает первого бинарного ученика SVM, использующего все наблюдения, классифицированные как 'setosa' и 'versicolor'. Поскольку 'setosa' соответствует 1, это - положительный класс; 'versicolor' соответствует –1, таким образом, это - отрицательный класс.
Можно получить доступ к каждой бинарной индексации ячейки использования ученика и записи через точку.
Mdl.BinaryLearners{1} % The first binary learnerans =
classreg.learning.classif.CompactClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [-1 1]
ScoreTransform: 'none'
Beta: [4x1 double]
Bias: 1.4505
KernelParameters: [1x1 struct]
Properties, Methods
Вычислите ошибку классификации перезамены.
error = resubLoss(Mdl)
error = 0.0067
Ошибка классификации на данных тренировки является небольшой, но классификатор может быть сверхподобранной моделью. Можно перекрестный подтвердить классификатор с помощью crossval и вычислить ошибку классификации перекрестных проверок вместо этого.
Обучите модель ECOC, состоявшую из нескольких двоичного файла, линейных моделей классификации.
Загрузите набор данных NLP.
load nlpdataX является разреженной матрицей данных о предикторе, и Y является категориальным вектором меток класса. В данных существует больше чем два класса.
Создайте линейный образцовый классификацией шаблон по умолчанию.
t = templateLinear();
Чтобы настроить значения по умолчанию, см. Аргументы в виде пар имя-значение на странице templateLinear.
Обучите модель ECOC, состоявшую из нескольких двоичного файла, линейные модели классификации, которые могут идентифицировать продукт, учитывая плотность распределения слов на веб-странице документации. В течение более быстрого учебного времени транспонируйте данные о предикторе и укажите, что наблюдения соответствуют столбцам.
X = X'; rng(1); % For reproducibility Mdl = fitcecoc(X,Y,'Learners',t,'ObservationsIn','columns')
Mdl =
classreg.learning.classif.CompactClassificationECOC
ResponseName: 'Y'
ClassNames: [1x13 categorical]
ScoreTransform: 'none'
BinaryLearners: {78x1 cell}
CodingMatrix: [13x78 double]
Properties, Methods
Также можно обучить модель ECOC, состоявшую из линейных моделей классификации по умолчанию с помощью 'Learners','Linear'.
Чтобы сохранить память, fitcecoc возвращает обученные модели ECOC, состоявшие из линейных учеников классификации в объектах модели CompactClassificationECOC.
Перекрестный подтвердите классификатор ECOC с бинарными учениками SVM и оцените обобщенную ошибку классификации.
Загрузите ирисовый набор данных Фишера. Задайте данные о предикторе X и данные об ответе Y.
load fisheriris X = meas; Y = species; rng(1); % For reproducibility
Создайте шаблон SVM и стандартизируйте предикторы.
t = templateSVM('Standardize',true)t =
Fit template for classification SVM.
Alpha: [0x1 double]
BoxConstraint: []
CacheSize: []
CachingMethod: ''
ClipAlphas: []
DeltaGradientTolerance: []
Epsilon: []
GapTolerance: []
KKTTolerance: []
IterationLimit: []
KernelFunction: ''
KernelScale: []
KernelOffset: []
KernelPolynomialOrder: []
NumPrint: []
Nu: []
OutlierFraction: []
RemoveDuplicates: []
ShrinkagePeriod: []
Solver: ''
StandardizeData: 1
SaveSupportVectors: []
VerbosityLevel: []
Version: 2
Method: 'SVM'
Type: 'classification'
t является шаблоном SVM. Большинство свойств объекта шаблона пусто. Когда обучение классификатор ECOC, программное обеспечение устанавливает применимые свойства на их значения по умолчанию.
Обучите классификатор ECOC и задайте порядок класса.
Mdl = fitcecoc(X,Y,'Learners',t,... 'ClassNames',{'setosa','versicolor','virginica'});
Mdl является классификатором ClassificationECOC. Можно получить доступ к его свойствам с помощью записи через точку.
Перекрестный подтвердите Mdl с помощью 10-кратной перекрестной проверки.
CVMdl = crossval(Mdl);
CVMdl является ClassificationPartitionedECOC перекрестный подтвержденный классификатор ECOC.
Оцените обобщенную ошибку классификации.
genError = kfoldLoss(CVMdl)
genError = 0.0400
Обобщенная ошибка классификации составляет 4%, который указывает, что классификатор ECOC делает вывод довольно хорошо.
Обучите классификатор ECOC с помощью двоичных учеников SVM. Сначала предскажите учебно-демонстрационные метки и апостериорные вероятности класса. Затем предскажите максимальную апостериорную вероятность класса в каждой точке в сетке. Визуализируйте результаты.
Загрузите ирисовый набор данных Фишера. Задайте лепестковые размерности как предикторы и имена разновидностей как ответ.
load fisheriris X = meas(:,3:4); Y = species; rng(1); % For reproducibility
Создайте шаблон SVM. Стандартизируйте предикторы и задайте Гауссово ядро.
t = templateSVM('Standardize',true,'KernelFunction','gaussian');
t является шаблоном SVM. Большинство его свойств пусто. Когда программное обеспечение обучает классификатор ECOC, оно устанавливает применимые свойства на их значения по умолчанию.
Обучите классификатор ECOC с помощью шаблона SVM. Преобразуйте очки классификации, чтобы классифицировать апостериорные вероятности (которые возвращены predict или resubPredict), использование аргумента пары "имя-значение" 'FitPosterior'. Задайте порядок класса с помощью аргумента пары "имя-значение" 'ClassNames'. Отобразите диагностические сообщения во время обучения при помощи аргумента пары "имя-значение" 'Verbose'.
Mdl = fitcecoc(X,Y,'Learners',t,'FitPosterior',true,... 'ClassNames',{'setosa','versicolor','virginica'},... 'Verbose',2);
Training binary learner 1 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 2 Positive class indices: 1 Fitting posterior probabilities for learner 1 (SVM). Training binary learner 2 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 3 Positive class indices: 1 Fitting posterior probabilities for learner 2 (SVM). Training binary learner 3 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 3 Positive class indices: 2 Fitting posterior probabilities for learner 3 (SVM).
Mdl является моделью ClassificationECOC. Тот же шаблон SVM применяется к каждому бинарному ученику, но можно настроить опции для каждого бинарного ученика путем передачи в векторе ячейки шаблонов.
Предскажите учебно-демонстрационные метки и апостериорные вероятности класса. Отобразите диагностические сообщения во время вычисления меток и апостериорных вероятностей класса при помощи аргумента пары "имя-значение" 'Verbose'.
[label,~,~,Posterior] = resubPredict(Mdl,'Verbose',1);Predictions from all learners have been computed. Loss for all observations has been computed. Computing posterior probabilities...
Mdl.BinaryLoss
ans = 'quadratic'
Программное обеспечение присваивает наблюдение классу, который приводит к самой маленькой средней бинарной потере. Поскольку все бинарные ученики вычисляют апостериорные вероятности, бинарной функцией потерь является quadratic.
Отобразите случайный набор результатов.
idx = randsample(size(X,1),10,1); Mdl.ClassNames
ans = 3x1 cell array
{'setosa' }
{'versicolor'}
{'virginica' }
table(Y(idx),label(idx),Posterior(idx,:),... 'VariableNames',{'TrueLabel','PredLabel','Posterior'})
ans=10×3 table
TrueLabel PredLabel Posterior
____________ ____________ ______________________________________
'virginica' 'virginica' 0.0039321 0.0039869 0.99208
'virginica' 'virginica' 0.017067 0.018263 0.96467
'virginica' 'virginica' 0.014948 0.015856 0.9692
'versicolor' 'versicolor' 2.2197e-14 0.87317 0.12683
'setosa' 'setosa' 0.999 0.00025091 0.00074639
'versicolor' 'virginica' 2.2195e-14 0.059429 0.94057
'versicolor' 'versicolor' 2.2194e-14 0.97001 0.029986
'setosa' 'setosa' 0.999 0.0002499 0.00074741
'versicolor' 'versicolor' 0.0085646 0.98259 0.008849
'setosa' 'setosa' 0.999 0.00025013 0.00074718
Столбцы Posterior соответствуют порядку класса Mdl.ClassNames.
Задайте сетку значений на наблюдаемом пробеле предиктора. Предскажите апостериорные вероятности для каждого экземпляра в сетке.
xMax = max(X); xMin = min(X); x1Pts = linspace(xMin(1),xMax(1)); x2Pts = linspace(xMin(2),xMax(2)); [x1Grid,x2Grid] = meshgrid(x1Pts,x2Pts); [~,~,~,PosteriorRegion] = predict(Mdl,[x1Grid(:),x2Grid(:)]);
Для каждой координаты на сетке постройте максимальную апостериорную вероятность класса среди всех классов.
contourf(x1Grid,x2Grid,... reshape(max(PosteriorRegion,[],2),size(x1Grid,1),size(x1Grid,2))); h = colorbar; h.YLabel.String = 'Maximum posterior'; h.YLabel.FontSize = 15; hold on gh = gscatter(X(:,1),X(:,2),Y,'krk','*xd',8); gh(2).LineWidth = 2; gh(3).LineWidth = 2; title('Iris Petal Measurements and Maximum Posterior') xlabel('Petal length (cm)') ylabel('Petal width (cm)') axis tight legend(gh,'Location','NorthWest') hold off

Обучите one-all ECOC классификатор с помощью ансамбля GentleBoost деревьев решений с суррогатными разделениями. Ускорять обучение, интервал числовые предикторы и использовать параллельные вычисления. Раскладывание допустимо только, когда fitcecoc использует древовидного ученика. После обучения оцените ошибку классификации 10-кратная перекрестная проверка. Обратите внимание на то, что параллельные вычисления требуют Parallel Computing Toolbox™.
Загрузка демонстрационных данных
Загрузите и осмотрите набор данных arrhythmia.
load arrhythmia
[n,p] = size(X)n = 452
p = 279
isLabels = unique(Y); nLabels = numel(isLabels)
nLabels = 13
tabulate(categorical(Y))
Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
Набор данных содержит предикторы 279, и объем выборки 452 является относительно маленьким. Из 16 отличных меток только 13 представлены в ответе (Y). Каждая метка описывает различные степени аритмии, и 54,20% наблюдений находится в классе 1.
Обучите One-All ECOC классификатор
Создайте шаблон ансамбля. Необходимо задать по крайней мере три аргумента: метод, много учеников и тип ученика. В данном примере задайте 'GentleBoost' для метода, 100 для количества учеников и шаблон дерева решений, который использует суррогатные разделения, потому что там пропускают наблюдения.
tTree = templateTree('surrogate','on'); tEnsemble = templateEnsemble('GentleBoost',100,tTree);
tEnsemble является объектом шаблона. Большинство его свойств пусто, но программное обеспечение заполняет их с их значениями по умолчанию во время обучения.
Обучите one-all ECOC классификатор с помощью ансамблей деревьев решений как бинарные ученики. Чтобы ускорить обучение, используйте раскладывание и параллельные вычисления.
Раскладывание ('NumBins',50) — Когда у вас есть большой обучающий набор данных, можно ускорить обучение (потенциальное уменьшение в точности) при помощи аргумента пары "имя-значение" 'NumBins'. Этот аргумент допустим только, когда fitcecoc использует древовидного ученика. Если вы задаете значение 'NumBins', то интервалы программного обеспечения каждый числовой предиктор в конкретное количество равновероятных интервалов, и затем выращивает деревья на индексах интервала вместо исходных данных. Можно попробовать 'NumBins',50 сначала, и затем изменить значение 'NumBins' в зависимости от точности и учебной скорости.
Параллельные вычисления ('Options',statset('UseParallel',true)) — С лицензией Parallel Computing Toolbox, можно ускорить вычисление при помощи параллельных вычислений, которые отправляют каждого бинарного ученика рабочему в пуле. Количество рабочих зависит от вашей конфигурации системы. Когда вы используете деревья решений для бинарных учеников, fitcecoc параллелизирует обучение с помощью Intel® Threading Building Blocks (TBB) для двухъядерных систем и выше. Поэтому определение опции 'UseParallel' не полезно на одиночном компьютере. Используйте эту опцию на кластере.
Кроме того, укажите, что априорные вероятности являются 1/K, где K = 13 является количеством отличных классов.
options = statset('UseParallel',true); Mdl = fitcecoc(X,Y,'Coding','onevsall','Learners',tEnsemble,... 'Prior','uniform','NumBins',50,'Options',options);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
Mdl является моделью ClassificationECOC.
Перекрестная проверка
Перекрестный подтвердите классификатор ECOC с помощью 10-кратной перекрестной проверки.
CVMdl = crossval(Mdl,'Options',options);Warning: One or more folds do not contain points from all the groups.
CVMdl является моделью ClassificationPartitionedECOC. Предупреждение указывает, что некоторые классы не представлены, в то время как программное обеспечение обучает по крайней мере один сгиб. Поэтому те сгибы не могут предсказать метки для недостающих классов. Можно осмотреть результаты индексации ячейки использования сгиба и записи через точку. Например, получите доступ к результатам первого сгиба путем ввода CVMdl.Trained{1}.
Используйте перекрестный подтвержденный классификатор ECOC, чтобы предсказать метки сгиба валидации. Можно вычислить матрицу беспорядка при помощи confusionchart. Переместите и измените размер графика путем изменения внутреннего свойства положения гарантировать, что проценты появляются в сводных данных строки.
oofLabel = kfoldPredict(CVMdl,'Options',options); ConfMat = confusionchart(Y,oofLabel,'RowSummary','total-normalized'); ConfMat.InnerPosition = [0.10 0.12 0.85 0.85];

Воспроизведите сгруппированные данные
Воспроизведите сгруппированные данные о предикторе при помощи свойства BinEdges обученной модели и функции discretize.
X = Mdl.X; % Predictor data Xbinned = zeros(size(X)); edges = Mdl.BinEdges; % Find indices of binned predictors. idxNumeric = find(~cellfun(@isempty,edges)); if iscolumn(idxNumeric) idxNumeric = idxNumeric'; end for j = idxNumeric x = X(:,j); % Convert x to array if x is a table. if istable(x) x = table2array(x); end % Group x into bins by using the discretize function. xbinned = discretize(x,[-inf; edges{j}; inf]); Xbinned(:,j) = xbinned; end
Xbinned содержит индексы интервала, в пределах от 1 к количеству интервалов, для числовых предикторов. значениями Xbinned является 0 для категориальных предикторов. Если X содержит NaN s, то соответствующими значениями Xbinned является NaN s.
Оптимизируйте гиперпараметры автоматически с помощью fitcecoc.
Загрузите набор данных fisheriris.
load fisheriris
X = meas;
Y = species;Найдите гиперпараметры, которые минимизируют пятикратную потерю перекрестной проверки при помощи автоматической гипероптимизации параметров управления. Для воспроизводимости, набор случайный seed и использование функция приобретения 'expected-improvement-plus'.
rng default Mdl = fitcecoc(X,Y,'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName',... 'expected-improvement-plus'))

|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Coding | BoxConstraint| KernelScale |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 1 | Best | 0.10667 | 0.87676 | 0.10667 | 0.10667 | onevsone | 5.6939 | 200.36 |
| 2 | Best | 0.08 | 7.2344 | 0.08 | 0.081379 | onevsone | 94.849 | 0.0032549 |
| 3 | Accept | 0.08 | 0.65166 | 0.08 | 0.08003 | onevsall | 0.01378 | 0.076021 |
| 4 | Accept | 0.08 | 0.5166 | 0.08 | 0.080001 | onevsall | 889 | 38.798 |
| 5 | Best | 0.073333 | 0.5641 | 0.073333 | 0.073337 | onevsall | 17.142 | 1.7174 |
| 6 | Accept | 0.38 | 27.439 | 0.073333 | 0.073338 | onevsall | 0.88995 | 0.0010029 |
| 7 | Best | 0.046667 | 0.38402 | 0.046667 | 0.046688 | onevsall | 4.246 | 0.3356 |
| 8 | Best | 0.033333 | 0.32073 | 0.033333 | 0.033341 | onevsone | 0.22406 | 0.37399 |
| 9 | Best | 0.026667 | 0.32614 | 0.026667 | 0.026678 | onevsone | 14.237 | 3.5166 |
| 10 | Accept | 0.33333 | 0.40016 | 0.026667 | 0.026676 | onevsall | 0.0064689 | 999.31 |
| 11 | Accept | 0.04 | 0.44305 | 0.026667 | 0.0268 | onevsone | 982.5 | 0.51146 |
| 12 | Accept | 0.046667 | 0.3099 | 0.026667 | 0.026694 | onevsone | 0.018266 | 0.047347 |
| 13 | Accept | 0.10667 | 0.30053 | 0.026667 | 0.029124 | onevsone | 0.0010243 | 13.372 |
| 14 | Accept | 0.04 | 0.50414 | 0.026667 | 0.032336 | onevsone | 156.11 | 1.7366 |
| 15 | Accept | 0.046667 | 0.4236 | 0.026667 | 0.0327 | onevsone | 986.23 | 10.731 |
| 16 | Accept | 0.046667 | 1.915 | 0.026667 | 0.032045 | onevsone | 371.63 | 0.056453 |
| 17 | Accept | 0.04 | 0.3684 | 0.026667 | 0.033569 | onevsone | 0.0010311 | 0.0010175 |
| 18 | Accept | 0.046667 | 0.30775 | 0.026667 | 0.034256 | onevsone | 0.0011574 | 0.16436 |
| 19 | Accept | 0.06 | 13.292 | 0.026667 | 0.032699 | onevsall | 968.86 | 0.2494 |
| 20 | Accept | 0.04 | 0.37321 | 0.026667 | 0.031457 | onevsone | 985.47 | 2.8942 |
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Coding | BoxConstraint| KernelScale |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 21 | Accept | 0.04 | 0.44367 | 0.026667 | 0.03134 | onevsone | 0.001037 | 0.0044045 |
| 22 | Best | 0.02 | 0.41334 | 0.02 | 0.023771 | onevsone | 1.9507 | 1.3991 |
| 23 | Best | 0.013333 | 0.49252 | 0.013333 | 0.018605 | onevsone | 0.84926 | 1.3538 |
| 24 | Accept | 0.026667 | 0.36232 | 0.013333 | 0.021089 | onevsone | 0.2101 | 1.5222 |
| 25 | Accept | 0.026667 | 0.49534 | 0.013333 | 0.022321 | onevsone | 1.7108 | 1.2127 |
| 26 | Accept | 0.10667 | 0.4172 | 0.013333 | 0.022359 | onevsone | 0.0010149 | 986.98 |
| 27 | Accept | 0.33333 | 0.35196 | 0.013333 | 0.021789 | onevsall | 0.0010002 | 21.18 |
| 28 | Accept | 0.013333 | 0.30528 | 0.013333 | 0.019873 | onevsone | 1.5298 | 1.6373 |
| 29 | Accept | 0.02 | 0.30133 | 0.013333 | 0.019708 | onevsone | 1.2119 | 1.9178 |
| 30 | Accept | 0.33333 | 0.30865 | 0.013333 | 0.019544 | onevsall | 940.08 | 979.72 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 103.7335 seconds.
Total objective function evaluation time: 60.8427
Best observed feasible point:
Coding BoxConstraint KernelScale
________ _____________ ___________
onevsone 0.84926 1.3538
Observed objective function value = 0.013333
Estimated objective function value = 0.019544
Function evaluation time = 0.49252
Best estimated feasible point (according to models):
Coding BoxConstraint KernelScale
________ _____________ ___________
onevsone 1.5298 1.6373
Estimated objective function value = 0.019544
Estimated function evaluation time = 0.382
Mdl =
ClassificationECOC
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3x1 cell}
CodingName: 'onevsone'
HyperparameterOptimizationResults: [1x1 BayesianOptimization]
Properties, Methods
Создайте два мультикласса модели ECOC, обученные на высоких данных. Используйте линейных бинарных учеников для одной из моделей и двоичных учеников ядра для другого. Сравните ошибку классификации перезамены этих двух моделей.
В целом можно выполнить классификацию мультиклассов высоких данных при помощи fitcecoc с линейным или двоичными учениками ядра. Когда вы используете fitcecoc, чтобы обучить модель на длинных массивах, вы не можете использовать бинарных учеников SVM непосредственно. Однако можно использовать или линейный или модели классификации двоичных файлов ядра то использование SVMs.
Создайте datastore, который ссылается на папку, содержащую ирисовый набор данных Фишера. Задайте значения 'NA' как недостающие данные так, чтобы datastore заменил их на значения NaN. Создайте высокие версии данных об ответе и предиктора.
ds = datastore('fisheriris.csv','TreatAsMissing','NA'); t = tall(ds);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
X = [t.SepalLength t.SepalWidth t.PetalLength t.PetalWidth]; Y = t.Species;
Стандартизируйте данные о предикторе.
Z = zscore(X);
Обучите мультикласс модель ECOC, которая использует высокие данные и линейных бинарных учеников. По умолчанию, когда вы передаете длинные массивы fitcecoc, программное обеспечение обучает линейных бинарных учеников то использование SVMs. Поскольку данные об ответе содержат только три уникальных класса, измените схему кодирования от one-all (который является значением по умолчанию, когда вы используете высокие данные) для один по сравнению с одним (который, значение по умолчанию, когда вы используете данные в оперативной памяти).
Для воспроизводимости, набор seed генераторов случайных чисел с помощью rng и tallrng. Результаты могут отличаться в зависимости от количества рабочих и среды выполнения для длинных массивов. Для получения дополнительной информации смотрите Управление Где Ваши Выполнения Кода (MATLAB).
rng('default') tallrng('default') mdlLinear = fitcecoc(Z,Y,'Coding','onevsone')
Training binary learner 1 (Linear) out of 3. Training binary learner 2 (Linear) out of 3. Training binary learner 3 (Linear) out of 3.
mdlLinear =
classreg.learning.classif.CompactClassificationECOC
ResponseName: 'Y'
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingMatrix: [3×3 double]
Properties, Methods
mdlLinear является моделью CompactClassificationECOC, состоявшей из трех бинарных учеников.
Обучите мультикласс модель ECOC, которая использует высокие данные и двоичных учеников ядра. Во-первых, создайте объект templateKernel задать свойства двоичных учеников ядра; в частности, увеличьте число размерностей расширения к .
tKernel = templateKernel('NumExpansionDimensions',2^16)tKernel =
Fit template for classification Kernel.
BetaTolerance: []
BlockSize: []
BoxConstraint: []
Epsilon: []
NumExpansionDimensions: 65536
GradientTolerance: []
HessianHistorySize: []
IterationLimit: []
KernelScale: []
Lambda: []
Learner: 'svm'
LossFunction: []
Stream: []
VerbosityLevel: []
Version: 1
Method: 'Kernel'
Type: 'classification'
По умолчанию двоичные ученики ядра используют SVMs.
Передайте объект templateKernel fitcecoc и измените схему кодирования на один по сравнению с одним.
mdlKernel = fitcecoc(Z,Y,'Learners',tKernel,'Coding','onevsone')
Training binary learner 1 (Kernel) out of 3. Training binary learner 2 (Kernel) out of 3. Training binary learner 3 (Kernel) out of 3.
mdlKernel =
classreg.learning.classif.CompactClassificationECOC
ResponseName: 'Y'
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingMatrix: [3×3 double]
Properties, Methods
mdlKernel является также моделью CompactClassificationECOC, состоявшей из трех бинарных учеников.
Сравните ошибку классификации перезамены этих двух моделей.
errorLinear = gather(loss(mdlLinear,Z,Y))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.8 sec Evaluation completed in 1.9 sec
errorLinear = 0.0333
errorKernel = gather(loss(mdlKernel,Z,Y))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 18 sec Evaluation completed in 18 sec
errorKernel = 0.0067
mdlKernel неправильно классифицирует меньший процент данных тренировки, чем mdlLinear.
Для линейного обучения или модели классификации ядер, fitcecoc не поддерживает таблицы. Таким образом, если Learners является 'linear' или 'kernel', содержит линейный шаблон ученика модели классификации (см. templateLinear), или содержит шаблон ученика модели классификации ядер (см. templateKernel), то вы не можете предоставить Tbl, ResponseVarName или formula. Предоставьте матрицу данных о предикторе (X) и массив ответов (Y) вместо этого.
fitcecoc поддерживает разреженные матрицы для учебных линейных моделей классификации только. Для всех других моделей предоставьте полную матрицу данных о предикторе вместо этого.
coding design является матрицей, где элементы, прямые, какие классы обучены каждым бинарным учеником, то есть, как проблема мультикласса уменьшается до серии бинарных проблем.
Каждая строка проекта кодирования соответствует отличному классу, и каждый столбец соответствует бинарному ученику. В троичном проекте кодирования, для конкретного столбца (или бинарный ученик):
Строка, содержащая 1, направляет бинарного ученика, чтобы сгруппировать все наблюдения в соответствующем классе в положительный класс.
Строка, содержащая –1, направляет бинарного ученика, чтобы сгруппировать все наблюдения в соответствующем классе в отрицательный класс.
Строка, содержащая 0, направляет бинарного ученика, чтобы проигнорировать все наблюдения в соответствующем классе.
Кодирующие матрицы проекта с большими, минимальными, попарными расстояниями строки на основе меры Хэмминга оптимальны. Для получения дополнительной информации на попарном расстоянии строки, см. Случайные Матрицы Проекта Кодирования и [4].
Эта таблица описывает популярные проекты кодирования.
| Кодирование проекта | Описание | Количество учеников | Минимальное попарное расстояние строки |
|---|---|---|---|
| one-all (OVA) | Для каждого бинарного ученика один класс положителен, и остальные отрицательны. Этот проект исчерпывает все комбинации положительных присвоений класса. | K | 2 |
| один по сравнению с одним (OVO) | Для каждого бинарного ученика один класс положителен, другой отрицателен, и остальные проигнорированы. Этот проект исчерпывает все комбинации присвоений пары класса. | K (K – 1)/2 | 1 |
| завершенный двоичный файл | Этот проект делит классы во все бинарные комбинации и не игнорирует классов. Таким образом, всеми присвоениями класса является | 2K – 1 – 1 | 2K – 2 |
| троичный завершенный | Этот проект делит классы во все троичные комбинации. Таким образом, всеми присвоениями класса является | (3K – 2K + 1 + 1)/2 | 3K – 2 |
| порядковый | Для первого бинарного ученика первый класс отрицателен, и остальные положительны. Для второго бинарного ученика первые два класса отрицательны, и остальные положительны и так далее. | K 1 | 1 |
| плотный случайный | Для каждого бинарного ученика программное обеспечение случайным образом присваивает классы в положительные или отрицательные классы с по крайней мере одним из каждого типа. Для получения дополнительной информации см. Случайные Матрицы Проекта Кодирования. | Случайный, но приблизительно 10 log2K | Переменная |
| разреженный случайный | Для каждого бинарного ученика программное обеспечение случайным образом присваивает классы как положительные или отрицательные с вероятностью 0.25 для каждого, и игнорирует классы с вероятностью 0.5. Для получения дополнительной информации см. Случайные Матрицы Проекта Кодирования. | Случайный, но приблизительно 15 log2K | Переменная |
Этот график сравнивает количество бинарных учеников для проектов кодирования с увеличением K.
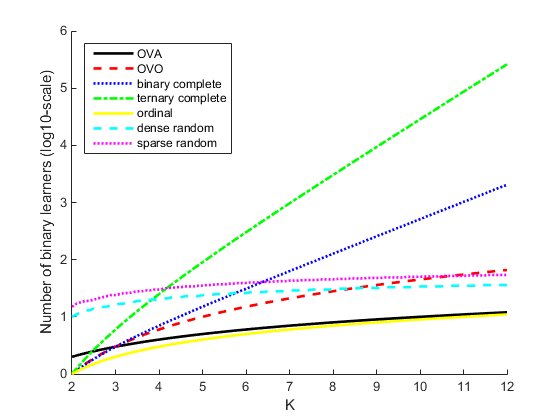
Количество бинарных учеников растет с количеством классов. Для проблемы со многими классами binarycomplete и проекты кодирования ternarycomplete не эффективны. Однако:
Если K ≤ 4, то используйте проект кодирования ternarycomplete, а не sparserandom.
Если K ≤ 5, то используйте проект кодирования binarycomplete, а не denserandom.
Можно отобразить матрицу проекта кодирования обученного классификатора ECOC путем ввода Mdl.CodingMatrix в Командное окно.
Необходимо сформировать матрицу кодирования, использующую глубокие знания приложения и учитывающую вычислительные ограничения. Если вы имеете достаточную вычислительную власть и время, то попробуйте несколько матриц кодирования и выберите ту с лучшей производительностью (например, проверяйте матрицы беспорядка на каждую модель с помощью confusionchart).
Перекрестная проверка "Отпуск один" (Leaveout) неэффективна для наборов данных со многими наблюдениями. Вместо этого используйте k - перекрестная проверка сгиба (KFold).
После обучения модель можно сгенерировать код C/C++, который предсказывает метки для новых данных. Генерация кода C/C++ требует MATLAB Coder™. Для получения дополнительной информации смотрите Введение в Генерацию кода.
[1] Allwein, E., Р. Шапайр и И. Зингер. “Уменьшая мультикласс до двоичного файла: подход объединения для поля classifiers”. Журнал Исследования Машинного обучения. Издание 1, 2000, стр 113–141.
[2] Fürnkranz, Иоганнес, “Круговая Классификация”. Дж. Мах. Учиться. Res., Издание 2, 2002, стр 721–747.
[3] Escalera, S., О. Пуджол и П. Радева. “На процессе декодирования в троичных выходных кодах с коррекцией ошибок”. Транзакции IEEE согласно Анализу Шаблона и Искусственному интеллекту. Издание 32, Выпуск 7, 2010, стр 120–134.
[4] Escalera, S., О. Пуджол и П. Радева. “Отделимость троичных кодов для разреженных проектов выходных кодов с коррекцией ошибок”. Перевинтик шаблона. Латыш., Издание 30, Выпуск 3, 2009, стр 285–297.
ClassificationECOC | ClassificationPartitionedECOC | ClassificationPartitionedKernelECOC | ClassificationPartitionedLinearECOC | CompactClassificationECOC | designecoc | loss | predict | statset
