статистика::Линейная регрессия (метод наименьших квадратов)
Блокноты MuPAD® будут демонтированы в будущем релизе. Используйте live скрипты MATLAB® вместо этого.
Live скрипты MATLAB поддерживают большую часть функциональности MuPAD, хотя существуют некоторые различия. Для получения дополнительной информации смотрите, Преобразовывают Notebook MuPAD в Live скрипты MATLAB.
stats::linReg([x1, x2, …],[y1, y2, …], <[w1, w2, …]>, <CovarianceMatrix>) stats::linReg([[x1, y1, <w1>], [x2, y2, <w2>], …], <CovarianceMatrix>) stats::linReg(s, <cx, cy, <cw>>, <CovarianceMatrix>) stats::linReg(s, <[cx, cy, <cw>]>, <CovarianceMatrix>)
stats::linReg([x1, x2, …], [y1, y2, …], [w1, w2, …]) вычисляет оценочные функции методом наименьших квадратов a, b линейного отношения y i = a + b xi между парами данных (x i, y i) путем минимизации
![]() .
.
Линейное отношение y i = a + b xi + e i между парами данных (x i, y i) принят.
Индексы столбца cx, cy является дополнительным, если данные даны объектом stats::sample, содержащим только два столбца нестроки. Cf. Пример 2.
Многомерная линейная регрессия и нелинейная регрессия обеспечиваются stats::reg.
Внешние статистические данные, сохраненные в ASCII-файле, могут быть импортированы в сеанс MuPAD® через import::readdata. В частности, смотрите Пример 1 из соответствующей страницы справки.
Мы вычисляем средства оценки наименьшего квадрата четырех пар значений, данных в двух списках. Обратите внимание на то, что существует линейное отношение y = 1 + 2 x между записями списков. Минимизированное квадратичное отклонение является 0 указаниями на совершенную подгонку:
stats::linReg([0, 1, 2, 3], [1, 3, 5, 7])
![]()
Также данные могут быть заданы списком пар:
stats::linReg([[1, 1.0], [2, 1.2], [3, 1.3], [4, 1.5]])
![]()
Мы принимаем, что переменной y в предыдущем примере является Poissonian, т.е. что измерениям (y i) = (1.0, 1.2, 1.3, 1.5) дало ошибки стандартное отклонение![]() . Мы обеспечиваем соответствующие веса
. Мы обеспечиваем соответствующие веса![]() и оцениваем доверительные интервалы для оценочных функций методом наименьших квадратов при помощи опции
и оцениваем доверительные интервалы для оценочных функций методом наименьших квадратов при помощи опции CovarianceMatrix:
stats::linReg([[1, 1.0, 1/1.0], [2, 1.2, 1/1.2],
[3, 1.3, 1/1.3], [4, 1.5, 1/1.5]], CovarianceMatrix)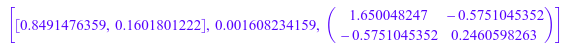
Квадратные корни из диагональных элементов ковариационной матрицы обеспечивают стандартные отклонения для предполагаемых параметров:
sqrt(%[3][1,1]), sqrt(%[3][2,2])
![]()
Таким образом мы получаем оценки![]()
![]() .
.
Мы создаем выборку, состоящую из одного столбца строки и двух столбцов нестроки:
stats::sample([["1", 0, 0], ["2", 10, 15], ["3", 20, 30]])
"1" 0 0 "2" 10 15 "3" 20 30
Средства оценки наименьшего квадрата вычисляются с помощью столбцов данных 2 и 3. В этом примере существует только два столбца нестроки, таким образом, индексы столбца не должны быть заданы:
stats::linReg(%)
![]()
Мы создаем выборку, состоящую из трех столбцов данных:
stats::sample([[1, 0, 0], [2, 10, 15], [3, 20, 30]])
1 0 0 2 10 15 3 20 30
Мы вычисляем средства оценки наименьшего квадрата для пар данных, данных первым и вторым столбцом:
stats::linReg(%, 1, 2)
![]()
Мы создаем выборку трех столбцов, содержащих символьные данные:
stats::sample([[x, y, 0], [2, 4, 15], [3, 20, 30]])
x y 0 2 4 15 3 20 30
Мы вычисляем символьные средства оценки наименьшего квадрата для пар данных, данных первым и вторым столбцом. Здесь мы задаем эти столбцы списком индексов столбца:
map(stats::linReg(%, [1, 2], CovarianceMatrix), normal)

Мы создаем данные (x i, y i) с рандомизированным отношением y i = a + b xi:
DIGITS := 5: r := stats::normalRandom(0, 5): X := [i $ i = 0..100]: Y := [12 + 17*x + r() $ x in X]:
Конструкцией отклонения σ (y i) 2 для данных y i в списке Y равняется 5. Мы используем веса![]() для всех данных:
для всех данных:
W := [1/5 $ i = 0..100]: [ab, chisquared, C]:= stats::linReg(X, Y, W, CovarianceMatrix)

Стандартные отклонения средств оценки a, b является квадратными корнями из диагональных элементов C:
sqrt(float(C[1,1])), sqrt(float(C[2,2]))
![]()
Таким образом оценка для a![]() , оценка для b
, оценка для b![]() .
.
delete r, X, Y, W, ab, chisquared, C:
|
Статистические данные: арифметические выражения |
|
Статистические данные: арифметические выражения |
|
Веса: арифметические выражения. Если никакие веса не обеспечиваются, w 1 =, w 2 = … = 1 используется. |
|
Выборка доменного типа |
|
Целые числа, представляющие индексы столбца демонстрационного |
|
Изменяет возвращаемое значение от
Из средств оценки a, b. При использовании этой опции предоставляется информация о доверительных интервалах для оценочных функций методом наименьших квадратов. В частности, возвращаемое значение включает ковариационную матрицу
Из типа
С
Ковариационной матрицей оценочных функций методом наименьших квадратов дают
|
Без опции CovarianceMatrix список возвращен [[a, b], chisquared]. Арифметические выражения a и b являются средствами оценки смещение и наклон линейного отношения. Арифметическое выражение chisquared является квадратичным отклонением
![]() ,
,
где a, b является оптимизированными средствами оценки.
С опцией CovarianceMatrix список возвращен [[a, b], chisquared, C]. Матричный C является ковариационной матрицей оптимизированных средств оценки a и b.
FAIL возвращен, если средства оценки a и b не существуют.
П.Р. Бевингтон и Д.К. Робинсон, “Снижение объема данных и анализ ошибок для физики”, McGraw-Hill, Нью-Йорк, 1992.


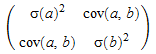
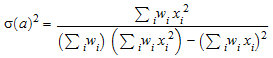 ,
,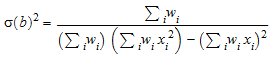 ,
, .
.