Обучите детектор объекта ACF
detector = trainACFObjectDetector(trainingData)detector = trainACFObjectDetector(trainingData,Name,Value)detector = trainACFObjectDetector(trainingData)trainingData, и автоматически собирает отрицательные экземпляры из изображений во время обучения. Чтобы создать наземную таблицу истинности, используйте приложение Video Labeler или Image Labeler.
detector = trainACFObjectDetector(trainingData,Name,Value)detector с дополнительными опциями, заданными одним или несколькими аргументами пары Name,Value.
Используйте trainACFObjectDetector с учебными изображениями, чтобы создать детектор объекта ACF, который может обнаружить знаки Стоп. Протестируйте детектор с отдельным изображением.
Загрузите данные тренировки.
load('stopSignsAndCars.mat')Выберите наземную истину для знаков Стоп. Они основываются, истина является набором известных местоположений знаков Стоп в изображениях.
stopSigns = stopSignsAndCars(:,1:2);
Добавьте полный путь в файлы изображений.
stopSigns.imageFilename = fullfile(toolboxdir('vision'),... 'visiondata',stopSigns.imageFilename);
Обучите детектор ACF. Можно выключить учебный прогресс, выведенный путем определения 'Verbose',false как пары Name,Value.
acfDetector = trainACFObjectDetector(stopSigns,'NegativeSamplesFactor',2);ACF Object Detector Training The training will take 4 stages. The model size is 34x31. Sample positive examples(~100% Completed) Compute approximation coefficients...Completed. Compute aggregated channel features...Completed. -------------------------------------------- Stage 1: Sample negative examples(~100% Completed) Compute aggregated channel features...Completed. Train classifier with 42 positive examples and 84 negative examples...Completed. The trained classifier has 19 weak learners. -------------------------------------------- Stage 2: Sample negative examples(~100% Completed) Found 84 new negative examples for training. Compute aggregated channel features...Completed. Train classifier with 42 positive examples and 84 negative examples...Completed. The trained classifier has 20 weak learners. -------------------------------------------- Stage 3: Sample negative examples(~100% Completed) Found 84 new negative examples for training. Compute aggregated channel features...Completed. Train classifier with 42 positive examples and 84 negative examples...Completed. The trained classifier has 54 weak learners. -------------------------------------------- Stage 4: Sample negative examples(~100% Completed) Found 84 new negative examples for training. Compute aggregated channel features...Completed. Train classifier with 42 positive examples and 84 negative examples...Completed. The trained classifier has 61 weak learners. -------------------------------------------- ACF object detector training is completed. Elapsed time is 18.7169 seconds.
Протестируйте детектор ACF на тестовом изображении.
img = imread('stopSignTest.jpg');
[bboxes,scores] = detect(acfDetector,img);Отобразите результаты обнаружения и вставьте ограничительные рамки для объектов в изображение.
for i = 1:length(scores) annotation = sprintf('Confidence = %.1f',scores(i)); img = insertObjectAnnotation(img,'rectangle',bboxes(i,:),annotation); end figure imshow(img)

trainingData — Маркированные наземные изображения истиныМаркированные наземные изображения истины, заданные как таблица с двумя столбцами. Первый столбец должен содержать пути и имена файлов к полутоновому или истинному цвету (RGB) изображения. Несмотря на то, что, основанные на ACF детекторы работают лучше всего с изображениями истинного цвета. Второй столбец содержит M-by-4 матрицы, которые содержат местоположения ограничительных рамок, связанных с соответствующим изображением. Местоположения находятся в формате, [x, y, width, height]. Второй столбец представляет положительный экземпляр класса отдельного объекта, такого как автомобиль, собака, цветок или знак Стоп. Отрицательные экземпляры автоматически собраны из изображений во время учебного процесса.
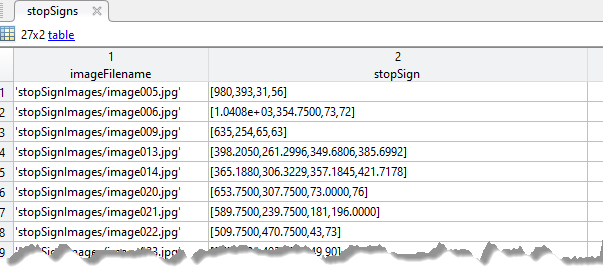
Каждая ограничительная рамка должна быть в формате [x, y, width, height]. Формат задает местоположение верхнего левого угла и размер объекта в соответствующем изображении. Табличная переменная (столбец) имя задает имя класса объекта. Чтобы создать наземную таблицу истинности, используйте приложение Image Labeler.
Укажите необязательные аргументы в виде пар ""имя, значение"", разделенных запятыми. Имя (Name) — это имя аргумента, а значение (Value) — соответствующее значение. Name должен появиться в кавычках. Вы можете задать несколько аргументов в виде пар имен и значений в любом порядке, например: Name1, Value1, ..., NameN, ValueN.
'ObjectTrainingSize', [100 100]