stats::covarianceКовариация выборок данных
Блокноты MuPAD® будут демонтированы в будущем релизе. Используйте live скрипты MATLAB® вместо этого.
Live скрипты MATLAB поддерживают большую часть функциональности MuPAD, хотя существуют некоторые различия. Для получения дополнительной информации смотрите, Преобразуют Notebook MuPAD в Live скрипты MATLAB.
stats::covariance([x1, x2, …],[y1, y2, …], <Sample | Population>) stats::covariance([[x1, y1], [x2, y2], …], <Sample | Population>) stats::covariance(s, <c1, c2>, <Sample | Population>) stats::covariance(s, <[c1, c2]>, <Sample | Population>) stats::covariance(s1, <c1>,s2, <c2>, <Sample | Population>)
stats::covariance([x1, x2, …, xn], [y1, y2, …, yn]) возвращает ковариацию
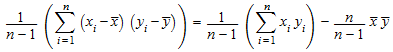 ,
,
где![]() и
и![]() средние арифметические данных x i и y i, соответственно.
средние арифметические данных x i и y i, соответственно.
stats::covariance([x1, x2, …, xn], [y1, y2, …, yn], Population) возвращается
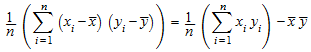 .
.
Если входные данные являются числами с плавающей запятой, суммы, задающие ковариацию, вычисляются численно устойчивым способом. Если результат с плавающей точкой желаем, рекомендуется убедиться, что все входные данные являются плаваниями.
Для точных входных данных возвращены точные символьные выражения.
Индексы столбца c1C2 являются дополнительными, если данные даны stats::sample объекты содержа только два столбца данных нестроки. Если данные обеспечиваются двумя выборками s1S2 , индексы столбца являются дополнительными для выборок, содержащих только один столбец данных нестроки.
Внешние статистические данные, сохраненные в ASCII-файле, могут быть импортированы в сеанс MuPAD® через import::readdata. В частности, смотрите Пример 1 из соответствующей страницы справки.
Мы вычисляем ковариацию выборок, переданных как списки:
X := [2, 33/7, 21/9, PI]: Y := [3, 5, 1, 7]: stats::covariance(X, Y)
![]()
В качестве альтернативы данные могут быть переданы как список пар данных:
stats::covariance([[2, 3], [33/7, 5], [21/9, 1], [PI, 7]])
![]()
Если все данные являются числами с плавающей запятой, результатом является плавание:
stats::covariance(float(X), float(Y))
![]()
delete X, Y:
Мы создаем выборку типа stats::sample:
s := stats::sample([[1.0, 2.4, 3.0],
[7.0, 4.8, 4.0],
[3.3, 3.0, 5.0]])1.0 2.4 3.0 7.0 4.8 4.0 3.3 3.0 5.0
Мы вычисляем ковариацию первого столбца и третьего столбца несколькими эквивалентными способами:
stats::covariance(s, 1, 3), stats::covariance(s, [1, 3]), stats::covariance(s, 1, s, 3)
![]()
delete s:
Ковариация символьных данных возвращена как символьное выражение:
stats::covariance([x1, x2], [y1, y2])
![]()
expand(%)
![]()
|
Статистические данные: арифметические выражения. Количество данных x i должно совпасть с количеством данных y i. |
|
Выборки статистики типа:: выборка |
|
Индексы столбца: положительные целые числа. Столбец |
|
Данные рассматриваются как “выборка”, не как полное население. Это значение по умолчанию. |
|
Данные рассматриваются как целое население, не как выборка. |
