stats::frequencyСоответствуйте числовым данным в частоты количества и классы
Блокноты MuPAD® будут демонтированы в будущем релизе. Используйте live скрипты MATLAB® вместо этого.
Live скрипты MATLAB поддерживают большую часть функциональности MuPAD, хотя существуют некоторые различия. Для получения дополнительной информации смотрите, Преобразуют Notebook MuPAD в Live скрипты MATLAB.
stats::frequency(data, <ClassesClosed = Left | Right>) stats::frequency(data,n, <ClassesClosed = Left | Right>) stats::frequency(data,[n], <ClassesClosed = Left | Right>) stats::frequency(data,[a1 .. b1, a2 .. b2, …], <ClassesClosed = Left | Right>) stats::frequency(data,[[a1, b1], [a2, b2], …], <ClassesClosed = Left | Right>) stats::frequency(data,Classes = n, <ClassesClosed = Left | Right>) stats::frequency(data,Classes = [n], <ClassesClosed = Left | Right>) stats::frequency(data,Classes = [a1 .. b1, a2 .. b2, …], <ClassesClosed = Left | Right>) stats::frequency(data,Classes = [[a1, b1], [a2, b2], …], <ClassesClosed = Left | Right>) stats::frequency(data,Cells = n, <CellsClosed = Left | Right>) stats::frequency(data,Cells = [n], <CellsClosed = Left | Right>) stats::frequency(data,Cells = [a1 .. b1, a2 .. b2, …], <CellsClosed = Left | Right>) stats::frequency(data,Cells = [[a1, b1], [a2, b2], …], <CellsClosed = Left | Right>)
stats::frequency(data, [[a1, b1], [a2, b2], …]) соответствует числовым данным в различные классы, данные полуоткрытыми интервалами![]() . Это рассчитывает, сколько элементов данных попадает в каждый класс.
. Это рассчитывает, сколько элементов данных попадает в каждый класс.
Все элементы данных должны быть действительными численными значениями. Точные численные значения, такие как π,![]() и т.д. позволены, если они могут быть преобразованы в действительные числа с плавающей запятой через
и т.д. позволены, если они могут быть преобразованы в действительные числа с плавающей запятой через float. Ошибка повышена, если символьные данные найдены, что это не может быть преобразовано в действительные числа с плавающей точкой.
Обратите внимание на то, что stats::frequency быстро, если все элементы данных являются целыми числами, рациональными числами или числами с плавающей точкой. Точные численные значения, такие как π,![]() и т.д. обрабатываются, но оказывают значимое влияние на КПД
и т.д. обрабатываются, но оказывают значимое влияние на КПД stats::frequency.
Данные, данные массивом, таблица и т.д. внутренне обработана как список, содержащий все операнды контейнера данных. В частности, все строки и столбцы массивов, матриц и stats::sample объекты учтены. stats::sample объект не должен содержать вводы текста.
Для спецификации классов, stats::frequency принимает или одно положительное целое число (или, эквивалентно, список одного положительного целого числа) или список классов, данных как области значений или списки двух элементов.
Один целочисленный n в спецификации Classes= n или Classes= [n] интерпретирован, когда “подразделяют диапазон от min (data) к max (data) в классы n равного размера”. Левая граница первого класса установлена в - ∞.
Классы могут быть заданы непосредственно как в Classes = [[a1, b1], [a2, b2], …] или Classes=[a_1..b_1, a_2..b_2, dots].
С настройкой по умолчанию ClassesClosed = Right, i-th класс является полуоткрытым интервалом![]() , т.е. данной величиной, x соответствуют в i-th класс, если a i <x ≤ b i удовлетворяют.
, т.е. данной величиной, x соответствуют в i-th класс, если a i <x ≤ b i удовлетворяют.
С ClassesClosed = Left, i-th класс является полуоткрытым интервалом![]() , т.е. данной величиной, x соответствуют в i-th класс, если a i ≤ x <b i удовлетворяют.
, т.е. данной величиной, x соответствуют в i-th класс, если a i ≤ x <b i удовлетворяют.
Контуры класса должны быть числовыми действительными значениями, удовлетворяющими a 1 ≤ b 1 ≤ a 2 ≤ b 2 ≤ a 3 ≤ …. В большинстве приложений, b 1 = a 2, b 2 = a 3 и т.д. является соответствующим.
Точные значения, такие как π,![]() и т.д. приняты и обработаны.
и т.д. приняты и обработаны.
Классы не должны покрывать целую область значений данных. Данные проигнорированы, если они не попадают в один из заданных классов.
При предоставлении классов непосредственно, крайняя левая граница может быть - ∞, и самой правой границей может быть infinity.
Мы разделяем следующие данные в 10 классов равного размера (значение по умолчанию). Первый класс покрывает значения от - ∞ к 2:
data := [0, 1, 2, PI, 4, 5, 6, 7, 7.1, 20]: T := stats::frequency(data)

Мы разделяем информацию о классах в 3 отдельных таблицы:
TheClasses = map(T, op, 1)

TheFrequencies = map(T, op, 2)

TheValues = map(T, op, 3)

Классы заданы явным образом:
classes:= [[0, 5], [5, 10], [10, 20]]: stats::frequency(data, classes)

Обратите внимание на то, что значению 0 не соответствуют ни в один из классов (первый класс представляет полуоткрытый интервал![]() )! Для того, чтобы включать все значения, мы используем
)! Для того, чтобы включать все значения, мы используем![]() в качестве контуров класса:
в качестве контуров класса:
classes:= [[-infinity, 5], [5, 10], [10, infinity]]: stats::frequency(data, classes)

delete data, T, classes:
Мы демонстрируем различие между опциями ClassesClosed = Left и ClassesClosed = Right. В первом случае значению 1 соответствуют во второй класс:
stats::frequency([0, 1, 2], Classes = [-infinity..1, 1..infinity],
ClassesClosed = Left)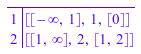
С ClassesClosed = Right, значению 1 соответствуют в первый класс:
stats::frequency([0, 1, 2], Classes = [-infinity..1, 1..infinity],
ClassesClosed = Right)
Настройкой по умолчанию является ClassesClosed = Right:
stats::frequency([0, 1, 2], Classes = [-infinity..1, 1..infinity])

Мы создаем выборку 1 000 нормально распределенных точек данных:
X := stats::normalRandom(0, 10): data := [X() $ i = 1..1000]:
Этим данным соответствуют в 5 различных классов равной ширины:
T := stats::frequency(data, 5):
Мы определяем количество значений данных в каждом классе:
for i from 1 to 5 do
print(Class = T[i][1], NumberOfElements = T[i][2]);
end_for:![]()
![]()
![]()
![]()
![]()
Мы определяем выбросы выборки данных путем сбора значений, меньших, чем - 9 и значений, больше, чем 10:
classes := [[-infinity, -9], [10, infinity]]: T := stats::frequency(data, classes);

delete X, data, T, i, classes:
|
Статистические данные: список, набор, таблица, массив, матрица или объект типа |
|
Количество классов (ячейки): положительное целое число. Если не заданный, n = 10 используется. |
|
Контуры класса: действительное удовлетворение численных значений
Также |
таблица возвращена с целочисленными индексами от 1 до количества классов. i-th запись таблицы T = stats::frequency(data, ...) список T[i] = [[a i, b i], n i, [v 1, v 2, …]], где [a i, b i] является i-th класс, n i, является количеством данных, падающих в этом классе, и [v 1, v 2, …] является отсортированным списком всех данных в этом классе (т.е. a i <v j ≤ b j для всего j от 1 до n i).
