Цель контролируемого, машинного обучения состоит в том, чтобы создать модель, которая делает предсказания на основе доказательства в присутствии неопределенности. Когда адаптивные алгоритмы идентифицируют шаблоны в данных, компьютер "извлекает уроки" из наблюдений. Когда отсоединено большему количеству наблюдений, компьютер улучшает свою прогнозирующую производительность.
А именно, алгоритм контролируемого обучения берет известный набор входных данных и имеющихся откликов к данным (выход) и trains модель, чтобы сгенерировать разумные предсказания для ответа на новые данные.
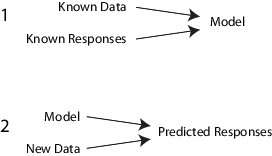
Например, предположите, что вы хотите предсказать, будет ли у кого-то сердечный приступ в течение года. У вас есть набор данных по предыдущим пациентам, включая возраст, вес, высоту, артериальное давление, и т.д. Вы знаете, были ли у предыдущих пациентов сердечные приступы в течение года после их измерений. Так, проблема комбинирует все существующие данные в модель, которая может предсказать, будет ли у нового человека сердечный приступ в течение года.
Можно думать о целом наборе входных данных как неоднородная матрица. Строки матрицы называются observations, examples или instances, и каждый содержит набор измерений для предмета (пациенты в примере). Столбцы матрицы называются predictors, attributes или features, и каждый - переменные, представляющие измерение, взятое каждый предмет (возраст, вес, высота, и т.д. в примере). Можно думать о данных об ответе как о вектор-столбце, где каждая строка содержит выход соответствующего наблюдения во входных данных (был ли у пациента сердечный приступ). К fit или train контролируемая модель изучения, выберите соответствующий алгоритм, и затем передайте вход и данные об ответе к нему.
Контролируемое изучение разделяет в две широких категории: классификация и регрессия.
В classification цель состоит в том, чтобы присвоить класс (или label) от конечного множества классов к наблюдению. Таким образом, ответы являются категориальными переменными. Приложения включают спам-фильтры, системы рекомендации рекламы, и изображение и распознавание речи. Предсказание, будет ли у пациента сердечный приступ в течение года, является проблемой классификации, и возможными классами является true и false. Алгоритмы классификации обычно применяются к номинальным значениям отклика. Однако некоторые алгоритмы могут вместить порядковые классы (см. fitcecoc).
В regression цель состоит в том, чтобы предсказать непрерывное измерение для наблюдения. Таким образом, переменные ответов являются вещественными числами. Приложения включают курсы акций прогнозирования, потребление энергии или заболеваемость.
Statistics and Machine Learning Toolbox™, контролируемый, изучая функциональности, включает оптимизированную, объектную среду. Можно эффективно обучить множество алгоритмов, моделей комбайнов в ансамбль, оценить эффективность модели, перекрестный подтвердить и предсказать ответы для новых данных.
В то время как существует много алгоритмов Statistics and Machine Learning Toolbox для контролируемого изучения, большая часть использования тот же основной рабочий процесс для получения модели предиктора. (Подробная инструкция относительно шагов для ансамбля, учащегося, находится в Среде для Приобретения знаний Ансамблем.) Шаги для контролируемого изучения:
Все контролируемые методы изучения запускаются с матрицы входных данных, обычно называемого X здесь. Каждая строка X представляет одно наблюдение. Каждый столбец X представляет одну переменную или предиктор. Представляйте недостающие записи NaN значения в X. Алгоритмы контролируемого обучения Statistics and Machine Learning Toolbox могут обработать NaN значения, или путем игнорирования их или путем игнорирования любой строки с NaN значение.
Можно использовать различные типы данных для данных об ответе Y. Каждый элемент в Y представляет ответ на соответствующую строку X. Наблюдения с пропавшими без вести Y данные проигнорированы.
Для регрессии, Y должен быть числовой вектор с тем же числом элементов как количество строк X.
Для классификации, Y может быть любой из этих типов данных. Эта таблица также содержит метод включения недостающих записей.
| Тип данных | Пропавшие без вести записи |
|---|---|
| Числовой вектор | NaN |
| Категориальный вектор | <undefined> |
| Массив символов | Строка пробелов |
| Массив строк | <missing> или "" |
| Массив ячеек из символьных векторов | '' |
| Логический вектор | (Не может представлять), |
Существуют компромиссы между несколькими характеристиками алгоритмов, такими как:
Скорость обучения
Использование памяти
Прогнозирующая точность на новых данных
Прозрачность или interpretability, означая, как легко можно изучить причины алгоритм, делают свои предсказания
Детали алгоритмов появляются в Характеристиках Алгоритмов Классификации. Больше детали об алгоритмах ансамбля находится в, Выбирают Applicable Ensemble Aggregation Method.
Подходящая функция, которую вы используете, зависит от алгоритма, который вы выбираете.
| Алгоритм | Подбор кривой функции |
|---|---|
| Деревья классификации | fitctree |
| Деревья регрессии | fitrtree |
| Дискриминантный анализ (классификация) | fitcdiscr |
| k- соседи (классификация) | fitcknn |
| Наивный байесов (классификация) | fitcnb |
| Машины опорных векторов (SVM) для классификации | fitcsvm |
| SVM для регрессии | fitrsvm |
| Модели мультикласса для SVM или других классификаторов | fitcecoc |
| Ансамбли классификации | fitcensemble |
| Ансамбли регрессии | fitrensemble |
| Классификация или ансамбли дерева регрессии (e.g., случайные леса [1]) параллельно | TreeBagger |
Для сравнения этих алгоритмов смотрите Характеристики Алгоритмов Классификации.
Эти три основных метода исследовать точность получившейся подобранной модели:
Исследуйте ошибку перезамены. Для примеров см.:
Исследуйте ошибку перекрестной проверки. Для примеров см.:
Исследуйте ошибку из сумки на сложенные в мешок деревья решений. Для примеров см.:
После проверки модели вы можете хотеть изменить его для лучшей точности, лучшей скорости, или использовать меньше памяти.
Измените подгоняемые параметры, чтобы попытаться получить более точную модель. Для примеров см.:
Измените подгоняемые параметры, чтобы попытаться получить меньшую модель. Это иногда дает модель с большей точностью. Для примеров см.:
Попробуйте различный алгоритм. Для применимого выбора см.:
Когда удовлетворенный моделью некоторых типов, можно обрезать его с помощью соответствующего compact функция (compact для деревьев классификации, compact для деревьев регрессии, compact для дискриминантного анализа, compact для Байесового наивного, compact для SVM, compact для моделей ECOC, compact для ансамблей классификации и compact для ансамблей регрессии). compact удаляет обучающие данные и другие свойства, не требуемые для предсказания, например, сокращая информацию для деревьев решений, из модели, чтобы уменьшать потребление памяти. Поскольку k, модели классификации NN требуют, чтобы все обучающие данные предсказали метки, вы не можете уменьшать размер ClassificationKNN модель.
Чтобы предсказать классификацию или ответ регрессии для большинства подобранных моделей, используйте predict метод:
Ypredicted = predict(obj,Xnew)
obj подобранная модель или подбирала компактную модель.
Xnew новые входные данные.
Ypredicted предсказанный ответ, или классификация или регрессия.
Эта таблица показывает типичные характеристики различных алгоритмов контролируемого обучения. Характеристики в каком-то конкретном случае могут варьироваться от перечисленных единиц. Используйте таблицу в качестве руководства для вашего начального выбора алгоритмов. Выберите компромисс, который вы хотите в скорости, использовании памяти, гибкости и interpretability.
Совет
Попробуйте дерево решений или дискриминант сначала, потому что эти классификаторы быстры и легки интерпретировать. Если модели не являются достаточно точным предсказанием ответа, попробуйте другие классификаторы более высокой гибкостью.
Чтобы управлять гибкостью, смотрите детали для каждого типа классификатора. Чтобы постараться не сверхсоответствовать, ищите модель более низкой гибкости, которая обеспечивает достаточную точность.
| Классификатор | Поддержка мультикласса | Категориальная поддержка предиктора | Скорость предсказания | Использование памяти | Interpretability |
|---|---|---|---|---|---|
Деревья решений — fitctree | Да | Да | Быстро | Маленький | Легкий |
Дискриминантный анализ — fitcdiscr | Да | Нет | Быстро | Маленький для линейного, большого для квадратичного | Легкий |
SVM — fitcsvm | Нет. Объедините несколько бинарное использование классификаторов SVM fitcecoc. | Да | Носитель для линейного. Медленный для других. | Носитель для линейного. Все другие: носитель для мультикласса, большого для двоичного файла. | Легкий для линейного SVM. Трудный для всех других типов ядра. |
Наивный байесов — fitcnb | Да | Да | Носитель для простых распределений. Медленный для распределений ядра или высоко-размерных данных | Маленький для простых распределений. Носитель для распределений ядра или высоко-размерных данных | Легкий |
NearestNeighbor fitcknn | Да | Да | Медленный для кубического. Носитель для других. | Носитель | Трудно |
Ансамбли — fitcensemble и fitrensemble | Да | Да | Быстро к носителю в зависимости от выбора алгоритма | Низко к высоко в зависимости от выбора алгоритма. | Трудно |
Результаты в этой таблице основаны на анализе многих наборов данных. Наборы данных в исследовании имеют до 7 000 наблюдений, 80 предикторов и 50 классов. Этот список задает условия в таблице.
Скорость:
Быстро — 0,01 секунды
Носитель — 1 секунда
Медленный — 100 секунд
Память
Маленький — 1 МБ
Носитель — 4 МБ
Большой — 100 МБ
Примечание
Таблица предоставляет общее руководство. Ваши результаты зависят от ваших данных и скорости вашей машины.
Эта таблица описывает поддержку типов данных предикторов для каждого классификатора.
| Классификатор | Все числовые предикторы | Все категориальные предикторы | Некоторые категориальные, некоторые числовые |
|---|---|---|---|
| Деревья решений | Да | Да | Да |
| Дискриминантный анализ | Да | Нет | Нет |
| SVM | Да | Да | Да |
| Наивный байесов | Да | Да | Да |
| NearestNeighbor | Евклидово расстояние только | Расстояние Хемминга только | Нет |
| Ансамбли | Да | Да, кроме ансамблей подпространства классификаторов дискриминантного анализа | Да, кроме ансамблей подпространства |
[1] Бреимен, L. Случайные Леса. Машинное обучение 45, 2001, стр 5–32.
