Звук с растягиванием во времени
Считывание звукового сигнала. Прослушайте звуковой сигнал и постройте его график с течением времени.
[audioIn,fs] = audioread("Counting-16-44p1-mono-15secs.wav"); t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on

sound(audioIn,fs)
Использовать stretchAudio для применения коэффициента ускорения 1,5. Прослушайте модифицированный аудиосигнал и постройте его график с течением времени. Частота дискретизации остается прежней, но длительность сигнала уменьшилась.
audioOut = stretchAudio(audioIn,1.5); t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, Speedup Factor = 1.5') axis tight grid on

sound(audioOut,fs)
Замедление исходного звукового сигнала на 0,75 коэффициента. Прослушайте модифицированный аудиосигнал и постройте его график с течением времени. Частота дискретизации остается такой же, как и у исходного звука, но длительность сигнала увеличилась.
audioOut = stretchAudio(audioIn,0.75); t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, Speedup Factor = 0.75') axis tight grid on

sound(audioOut,fs)
stretchAudio поддерживает TSM для аудио в частотной области при использовании метода вокодера по умолчанию. Применение TSM к звуку частотной области позволяет повторно использовать вычисления STFT для нескольких факторов TSM.
Считывание звукового сигнала. Прослушайте звуковой сигнал и постройте его график с течением времени.
[audioIn,fs] = audioread('FemaleSpeech-16-8-mono-3secs.wav'); sound(audioIn,fs) t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on

Преобразование звукового сигнала в частотную область.
win = sqrt(hann(256,'periodic')); ovrlp = 192; S = stft(audioIn,'Window',win,'OverlapLength',ovrlp,'Centered',false);
Ускорение звукового сигнала в 1,4 раза. Укажите длину окна и перекрытия, используемые для создания представления частотной области.
alpha = 1.4; audioOut = stretchAudio(S,alpha,'Window',win,'OverlapLength',ovrlp); sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, TSM Factor = 1.4') axis tight grid on

Замедлить звуковой сигнал в 0,8 раза. Укажите длину окна и перекрытия, используемые для создания представления частотной области.
alpha = 0.8; audioOut = stretchAudio(S,alpha,'Window',win,'OverlapLength',ovrlp); sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, TSM Factor = 0.8') axis tight grid on

Метод TSM по умолчанию (вокодер) позволяет дополнительно применить фазовую блокировку для повышения точности исходного звука.
Считывание звукового сигнала. Прослушайте звуковой сигнал и постройте его график с течением времени.
[audioIn,fs] = audioread("SpeechDFT-16-8-mono-5secs.wav"); sound(audioIn,fs) t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on

Фазовая блокировка добавляет нетривиальную вычислительную нагрузку к TSM и не всегда требуется. По умолчанию фазовая блокировка отключена. Примените коэффициент ускорения 1.8 к входному звуковому сигналу. Прослушайте звуковой сигнал и постройте его график с течением времени.
alpha = 1.8; tic audioOut = stretchAudio(audioIn,alpha); processingTimeWithoutPhaseLocking = toc
processingTimeWithoutPhaseLocking = 0.0798
sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, alpha = 1.8, LockPhase = false') axis tight grid on

Примените тот же коэффициент ускорения 1.8 к входному звуковому сигналу, на этот раз разрешив фазовую блокировку. Прослушайте звуковой сигнал и постройте его график с течением времени.
tic
audioOut = stretchAudio(audioIn,alpha,"LockPhase",true);
processingTimeWithPhaseLocking = tocprocessingTimeWithPhaseLocking = 0.1154
sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, alpha = 1.8, LockPhase = true') axis tight grid on

Метод TSM (WSOLA) позволяет задать максимальное количество выборок для поиска наилучшего выравнивания сигнала. По умолчанию дельта WSOLA - это количество выборок в окне анализа минус количество выборок, перекрывающихся между соседними окнами анализа. Увеличение дельты WSOLA увеличивает вычислительную нагрузку, но также может повысить точность.
Считывание звукового сигнала. Прослушайте первые 10 секунд звукового сигнала.
[audioIn,fs] = audioread('RockGuitar-16-96-stereo-72secs.flac');
sound(audioIn(1:10*fs,:),fs)Примените коэффициент TSM 0,75 к входному аудиосигналу с помощью метода WSOLA. Прослушайте первые 10 секунд результирующего звукового сигнала.
alpha = 0.75; tic audioOut = stretchAudio(audioIn,alpha,"Method","wsola"); processingTimeWithDefaultWSOLADelta = toc
processingTimeWithDefaultWSOLADelta = 19.4403
sound(audioOut(1:10*fs,:),fs)
Примените коэффициент TSM 0,75 к входному звуковому сигналу, на этот раз увеличив дельту WSOLA до 1024. Прослушайте первые 10 секунд результирующего звукового сигнала.
tic audioOut = stretchAudio(audioIn,alpha,"Method","wsola","WSOLADelta",1024); processingTimeWithIncreasedWSOLADelta = toc
processingTimeWithIncreasedWSOLADelta = 25.5306
sound(audioOut(1:10*fs,:),fs)
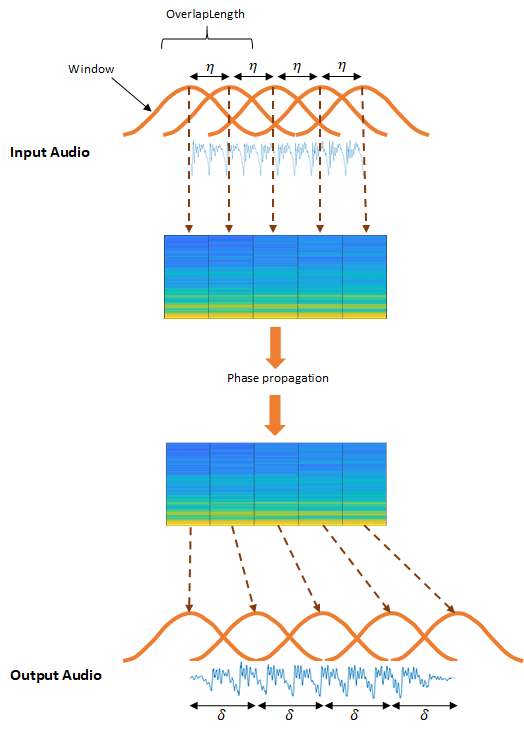
Алгоритм фазового вокодера является частотно-доменным подходом к TSM [1][2]. Основными этапами алгоритма фазового вокодера являются:
Алгоритм окрывает сигнал временной области с интервалом, где η = numel(. Затем окна преобразуются в частотную область.Window) - OverlapLength
Для сохранения горизонтальной (по времени) фазовой когерентности алгоритм рассматривает каждый элемент в качестве независимой синусоиды, фаза которой вычисляется путем накопления оценок ее мгновенной частоты.
Для сохранения вертикальной (по всему индивидуальному спектру) фазовой когерентности алгоритм блокирует фазовое продвижение групп бункеров до фазового продвижения локальных пиков. Этот шаг применяется только в том случае, если LockPhase имеет значение true.
Алгоритм возвращает модифицированную спектрограмму во временную область, с окнами, разнесёнными через интервалы δ, где δ ≈ start/α. α - коэффициент ускорения, определяемый alpha входной аргумент.
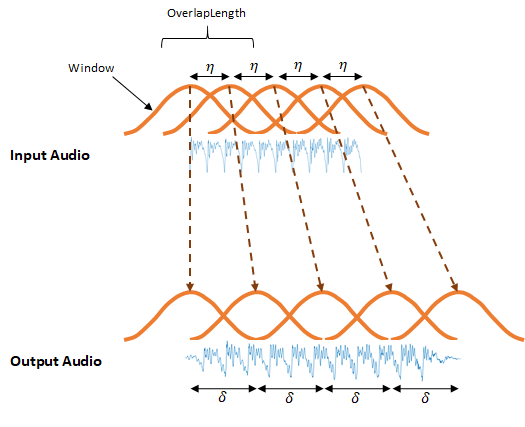
Алгоритм WSOLA является временным подходом к [1][2] TSM. WSOLA является расширением алгоритма наложения и добавления (OLA). В алгоритме OLA сигнал временной области окошивается с интервалом start, где η = numel(. Для построения модифицированного во временном масштабе выходного звука окна разнесены на интервал δ, где δ ≈ start/α. α - коэффициент TSM, определяемый Window) - OverlapLengthalpha входной аргумент.
Алгоритм OLA хорошо справляется с воссозданием спектров величин, но может вводить фазовые переходы между окнами. Алгоритм WSOLA пытается сгладить фазовые переходы путем поиска WSOLADelta отсчеты вокруг интервала startдля окна, которое минимизирует фазовые переходы. Алгоритм ищет лучшее окно итеративно, так что каждое последовательное окно выбирается относительно ранее выбранного окна.
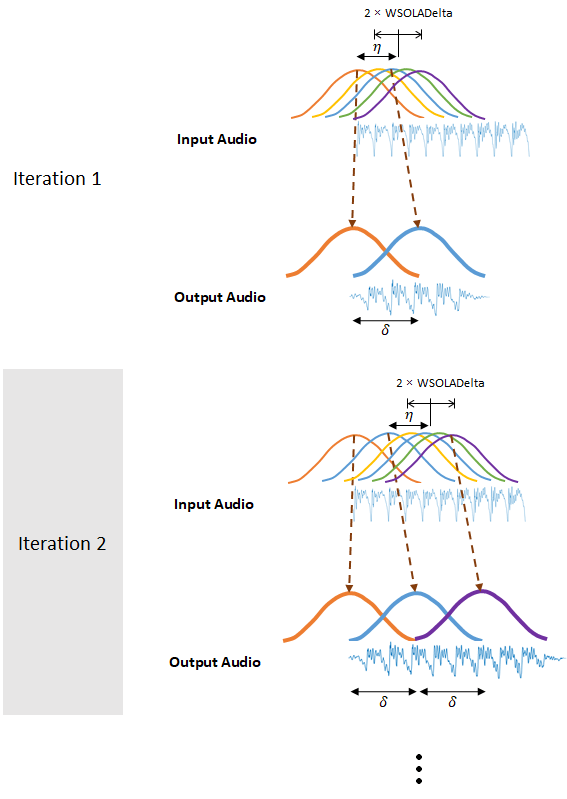
Если WSOLADelta имеет значение 0, то алгоритм сводится к OLA.
[1] Дриджер, Джонатан и Майнард Мюллер. «Обзор изменения музыкальных сигналов в масштабе времени». Прикладные науки. Том 6, выпуск 2, 2016.
[2] Дриджер, Джонатан. «Алгоритмы модификации во времени для музыкальных аудиосигналов», магистерская диссертация, Саарский университет, Саарбрюккен, Германия, 2011.
audioDataAugmenter | audioTimeScaler | reverberator | shiftPitch
