Прогнозные отклики байесовской модели линейной регрессии
yF = forecast(Mdl,XF)numPeriods прогнозируемые ответы из байесовской модели линейной регрессии
Mdl учитывая данные предиктора в XF, матрица с numPeriods строк.
Чтобы оценить прогноз, forecast использует среднее значение numPeriods-мерное апостериорное прогностическое распределение.
Если Mdl является совместной предыдущей моделью (возвращается bayeslm), то forecast использует только совместное предыдущее распределение и инновационное распределение для формирования прогностического распределения.
Если Mdl является задней моделью (возвращается estimate), то forecast использует апостериорное прогностическое распределение.
NaNs в данных указывают отсутствующие значения, которые forecast удаляет, используя удаление по списку.
yF = forecast(Mdl,XF,X,y)X и соответствующие данные ответа y.
Если Mdl является совместной предшествующей моделью, то forecast создает апостериорное прогностическое распределение путем обновления предшествующей модели информацией о параметрах, которые она получает из данных.
Если Mdl является задней моделью, то forecast обновляет апостериоры информацией о параметрах, которые они получают из дополнительных данных. Полная вероятность данных состоит из дополнительных данных. X и yи данные, которые были созданы Mdl.
yF = forecast(___,Name,Value)
Рассмотрим модель множественной линейной регрессии, которая предсказывает реальный валовой национальный продукт США (GNPR) с использованием линейной комбинации индекса промышленного производства (IPI), общая занятость (E) и реальная заработная плата (WR).
β3WRt + αt.
Для всех - это ряд независимых гауссовых возмущений со средним значением 0 и дисперсией .
Предположим, что эти предыдущие распределения:
λ 2В M является вектором средства 4 на 1, V является масштабированной матрицей положительной определенной ковариации 4 на 4.
B А В - форма и масштаб, соответственно, обратного гамма-распределения.
Эти допущения и правдоподобие данных подразумевают нормально-обратно-гамма-сопряженную модель.
Создайте нормально-обратно-гамма-сопряженную предыдущую модель для параметров линейной регрессии. Укажите количество предикторов p и имена переменных.
p = 3; VarNames = ["IPI" "E" "WR"]; PriorMdl = bayeslm(p,'ModelType','conjugate','VarNames',VarNames);
Mdl является conjugateblm Объект байесовской модели линейной регрессии, представляющий предварительное распределение коэффициентов регрессии и дисперсии возмущений.
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для данных предиктора и ответа. Удерживайте последние 10 периодов данных из оценки, чтобы использовать их для прогнозирования реального ВНП.
load Data_NelsonPlosser fhs = 10; % Forecast horizon size X = DataTable{1:(end - fhs),PriorMdl.VarNames(2:end)}; y = DataTable{1:(end - fhs),'GNPR'}; XF = DataTable{(end - fhs + 1):end,PriorMdl.VarNames(2:end)}; % Future predictor data yFT = DataTable{(end - fhs + 1):end,'GNPR'}; % True future responses
Оцените краевые задние распределения. Выключите отображение оценки.
PosteriorMdl = estimate(PriorMdl,X,y,'Display',false);PosteriorMdl является conjugateblm объект модели, который содержит апостериорные распределения и .
Прогнозные ответы с использованием апостериорного прогностического распределения и будущих данных предиктора XF. Постройте график истинных значений ответа и прогнозируемых значений.
yF = forecast(PosteriorMdl,XF); figure; plot(dates,DataTable.GNPR); hold on plot(dates((end - fhs + 1):end),yF) h = gca; p = patch([dates(end - fhs + 1) dates(end) dates(end) dates(end - fhs + 1)],... h.YLim([1,1,2,2]),[0.8 0.8 0.8]); uistack(p,'bottom'); legend('Forecast Horizon','True GNPR','Forecasted GNPR','Location','NW') title('Real Gross National Product: 1909 - 1970'); ylabel('rGNP'); xlabel('Year'); hold off

yF является вектором 10 на 1 будущих значений реального GNP, соответствующего будущим данным предиктора.
Оценка прогнозируемой среднеквадратичной ошибки (RMSE).
frmse = sqrt(mean((yF - yFT).^2))
frmse = 25.5397
RMSE прогноза является относительным показателем точности прогноза. В частности, можно оценить несколько моделей с использованием различных допущений. Модель с самым низким прогнозом RMSE является лучшей из сравниваемых моделей.
Рассмотрим регрессионную модель в ответах прогноза с использованием апостериорного прогностического распределения.
Создайте предыдущую модель normal-inverse-gamma semaconjugate для параметров линейной регрессии. Укажите количество предикторов p и названия коэффициентов регрессии.
p = 3; PriorMdl = bayeslm(p,'ModelType','semiconjugate','VarNames',["IPI" "E" "WR"]);
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для последовательности ответа и предиктора.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,'GNPR'};
Удерживайте последние 10 периодов данных из оценки, чтобы использовать их для прогнозирования реального ВНП. Выключите отображение оценки.
fhs = 10; % Forecast horizon size X = DataTable{1:(end - fhs),PriorMdl.VarNames(2:end)}; y = DataTable{1:(end - fhs),'GNPR'}; XF = DataTable{(end - fhs + 1):end,PriorMdl.VarNames(2:end)}; % Future predictor data yFT = DataTable{(end - fhs + 1):end,'GNPR'}; % True future responses
Прогнозные ответы с использованием апостериорного прогностического распределения и будущих данных предиктора XF. Укажите наблюдения в образце X и y (наблюдения, из которых MATLAB ® составляет задний).
yF = forecast(PriorMdl,XF,X,y)
yF = 10×1
491.5404
518.1725
539.0625
566.7594
597.7005
633.4666
644.7270
672.7937
693.5321
678.2268
Рассмотрим регрессионную модель в ответах прогноза с использованием апостериорного прогностического распределения.
Предположим, что эти предыдущие распределения для = 0,..., 3:
σVk2Z2, где и Z2 - независимые, стандартные нормальные случайные величины. Поэтому коэффициенты имеют гауссово распределение смеси. Предположим, что все коэффициенты условно независимы, априори, но они зависят от дисперсии возмущений.
B А В - форма и масштаб, соответственно, обратного гамма-распределения.
γk∈{0,1}and он представляет переменную режима включения со случайной переменной с дискретным равномерным распределением.
Выполнить выбор переменной стохастического поиска (SSVS):
Создайте модель байесовской регрессии для SSVS с сопряжением до правдоподобия данных. Используйте настройки по умолчанию.
Удерживайте последние 10 периодов данных из оценки.
Оцените краевые задние распределения.
p = 3; PriorMdl = bayeslm(p,'ModelType','mixconjugate','VarNames',["IPI" "E" "WR"]); load Data_NelsonPlosser fhs = 10; % Forecast horizon size X = DataTable{1:(end - fhs),PriorMdl.VarNames(2:end)}; y = DataTable{1:(end - fhs),'GNPR'}; XF = DataTable{(end - fhs + 1):end,PriorMdl.VarNames(2:end)}; % Future predictor data yFT = DataTable{(end - fhs + 1):end,'GNPR'}; % True future responses rng(1); % For reproducibility PosteriorMdl = estimate(PriorMdl,X,y,'Display',false);
Ответы прогноза с использованием апостериорного прогностического распределения и будущих данных предиктора XF. Постройте график истинных значений ответа и прогнозируемых значений.
yF = forecast(PosteriorMdl,XF); figure; plot(dates,DataTable.GNPR); hold on plot(dates((end - fhs + 1):end),yF) h = gca; hp = patch([dates(end - fhs + 1) dates(end) dates(end) dates(end - fhs + 1)],... h.YLim([1,1,2,2]),[0.8 0.8 0.8]); uistack(hp,'bottom'); legend('Forecast Horizon','True GNPR','Forecasted GNPR','Location','NW') title('Real Gross National Product: 1909 - 1970'); ylabel('rGNP'); xlabel('Year'); hold off

yF является вектором 10 на 1 будущих значений реального GNP, соответствующего будущим данным предиктора.
Оценка прогнозируемой среднеквадратичной ошибки (RMSE).
frmse = sqrt(mean((yF - yFT).^2))
frmse = 18.8470
RMSE прогноза является относительным показателем точности прогноза. В частности, можно оценить несколько моделей с использованием различных допущений. Модель с самым низким прогнозом RMSE является лучшей из сравниваемых моделей.
При выполнении байесовской регрессии с помощью SSVS рекомендуется настраивать гиперпараметры. Один из способов сделать это - оценить прогнозный RMSE по сетке значений гиперпараметров и выбрать значение, которое минимизирует прогнозный RMSE.
Рассмотрим регрессионную модель в ответах прогноза с использованием апостериорного прогностического распределения.
Создайте предыдущую модель normal-inverse-gamma semaconjugate для параметров линейной регрессии. Укажите количество предикторов p и названия коэффициентов регрессии.
p = 3; PriorMdl = bayeslm(p,'ModelType','semiconjugate','VarNames',["IPI" "E" "WR"]);
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для последовательности ответа и предиктора.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,'GNPR'};
Удерживайте последние 10 периодов данных из оценки, чтобы использовать их для прогнозирования реального ВНП. Выключите отображение оценки.
fhs = 10; % Forecast horizon size X = DataTable{1:(end - fhs),PriorMdl.VarNames(2:end)}; y = DataTable{1:(end - fhs),'GNPR'}; XF = DataTable{(end - fhs + 1):end,PriorMdl.VarNames(2:end)}; % Future predictor data yFT = DataTable{(end - fhs + 1):end,'GNPR'}; % True future responses
Ответы прогноза при помощи условного следующего прогнозирующего распределения беты, данной и использование будущих данных предсказателя XF. Укажите наблюдения в образце X и y (наблюдения, из которых MATLAB ® составляет задний). Постройте график истинных значений ответа и прогнозируемых значений.
yF = forecast(PriorMdl,XF,X,y,'Sigma2',2); figure; plot(dates,DataTable.GNPR); hold on plot(dates((end - fhs + 1):end),yF) h = gca; hp = patch([dates(end - fhs + 1) dates(end) dates(end) dates(end - fhs + 1)],... h.YLim([1,1,2,2]),[0.8 0.8 0.8])
hp =
Patch with properties:
FaceColor: [0.8000 0.8000 0.8000]
FaceAlpha: 1
EdgeColor: [0 0 0]
LineStyle: '-'
Faces: [1 2 3 4]
Vertices: [4x2 double]
Show all properties
uistack(hp,'bottom'); legend('Forecast Horizon','True GNPR','Forecasted GNPR','Location','NW') title('Real Gross National Product: 1909 - 1970'); ylabel('rGNP'); xlabel('Year'); hold off

Рассмотрим регрессионную модель в ответах прогноза с использованием апостериорного прогностического распределения.
Создайте предыдущую модель normal-inverse-gamma semaconjugate для параметров линейной регрессии. Укажите количество предикторов p и названия коэффициентов регрессии.
p = 3; PriorMdl = bayeslm(p,'ModelType','semiconjugate','VarNames',["IPI" "E" "WR"]);
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для последовательности ответа и предиктора.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,'GNPR'};
Удерживайте последние 10 периодов данных из оценки, чтобы использовать их для прогнозирования реального ВНП. Выключите отображение оценки.
fhs = 10; % Forecast horizon size X = DataTable{1:(end - fhs),PriorMdl.VarNames(2:end)}; y = DataTable{1:(end - fhs),'GNPR'}; XF = DataTable{(end - fhs + 1):end,PriorMdl.VarNames(2:end)}; % Future predictor data yFT = DataTable{(end - fhs + 1):end,'GNPR'}; % True future responses
Ответы прогноза и их ковариационная матрица с использованием заднего прогностического распределения и будущих данных предиктора XF. Укажите наблюдения в образце X и y (наблюдения, из которых MATLAB ® составляет задний).
[yF,YFCov] = forecast(PriorMdl,XF,X,y);
Поскольку прогностическое апостериорное распределение не является аналитическим, разумным приближением к набору из 95% достоверных интервалов является
),
для всех в горизонте прогноза. Оценка 95% достоверных интервалов для прогнозов по этой формуле.
n = sum(all(~isnan([X y]'))); cil = yF - norminv(0.975)*sqrt(diag(YFCov)); ciu = yF + norminv(0.975)*sqrt(diag(YFCov));
Постройте график данных, прогнозов и интервалов прогноза.
figure; plot(dates(end-30:end),DataTable.GNPR(end-30:end)); hold on h = gca; plot(dates((end - fhs + 1):end),yF) plot(dates((end - fhs + 1):end),[cil ciu],'k--') hp = patch([dates(end - fhs + 1) dates(end) dates(end) dates(end - fhs + 1)],... h.YLim([1,1,2,2]),[0.8 0.8 0.8]); uistack(hp,'bottom'); legend('Forecast horizon','True GNPR','Forecasted GNPR',... 'Credible interval','Location','NW') title('Real Gross National Product: 1909 - 1970'); ylabel('rGNP'); xlabel('Year'); hold off

Если Mdl является empiricalblm объект модели, то вы не можете указать Beta или Sigma2. Нельзя прогнозировать из условных предиктивных распределений с помощью эмпирического предыдущего распределения.
Моделирование Монте-Карло подвержено изменению. Если forecast использует моделирование Монте-Карло, тогда оценки и выводы могут различаться при вызове forecast многократно при, казалось бы, эквивалентных условиях. Чтобы воспроизвести результаты оценки, установите начальное число случайного числа с помощью rng перед вызовом forecast.
Если forecast выдает ошибку при оценке апостериорного распределения с использованием пользовательской предыдущей модели, затем попробуйте скорректировать начальные значения параметров с помощью BetaStart или Sigma2Startили попробуйте изменить объявленную функцию log previous, а затем восстановить модель. Ошибка может указывать на то, что журнал предыдущего распространения –Inf при заданных исходных значениях.
Для прогнозируемых ответов от условного апостериорного прогностического распределения аналитически труднореализуемых моделей, за исключением эмпирических моделей, передайте свой предыдущий объект модели и данные выборки оценки в forecast. Затем укажите Beta аргумент пары «имя-значение» для прогнозирования из условного заднебокового значения Sigma2 аргумент пары «имя-значение» для прогнозирования из условной задней части β.
Каждый раз, когда forecast должен оценить апостериорное распределение (например, когда Mdl представляет собой предыдущее распределение, и вы поставляете X и y) и задняя является аналитически отслеживаемой, forecast оценивает решения закрытой формы для оценщиков Байеса. В противном случае forecast прибегает к моделированию Монте-Карло для прогнозирования с использованием заднего прогностического распределения. Дополнительные сведения см. в разделе Апостериорная оценка и вывод.
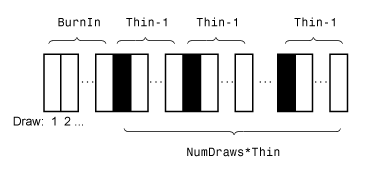
На этом рисунке показано, как forecast уменьшает выборку Монте-Карло, используя значения NumDraws, Thin, и BurnIn. Прямоугольники представляют последовательные розыгрыши из распределения. forecast удаляет белые прямоугольники из образца Монте-Карло. Остающееся NumDraws черные прямоугольники составляют образец Монте-Карло.
conjugateblm | customblm | diffuseblm | empiricalblm | lassoblm | mixconjugateblm | mixsemiconjugateblm | semiconjugateblm