Подгонка многоклассовых моделей для вспомогательных векторных машин или других классификаторов
Mdl = fitcecoc(Tbl,ResponseVarName)Tbl и метки классов в Tbl.ResponseVarName. fitcecoc использует модели K (K-1 )/2 двоичных векторных машин поддержки (SVM), используя конструкцию кодирования «один против одного», где K - количество уникальных меток класса (уровней ).Mdl является ClassificationECOC модель.
Mdl = fitcecoc(___,Name,Value)Name,Value парные аргументы, использующие любой из предыдущих синтаксисов.
Например, укажите различных двоичных учеников, другой дизайн кодирования или перекрестную проверку. Рекомендуется выполнять перекрестную проверку с использованием Kfold Name,Value парный аргумент. Результаты перекрестной проверки определяют, насколько хорошо обобщается модель.
[ также возвращает сведения об оптимизации гиперпараметров при указании Mdl,HyperparameterOptimizationResults] = fitcecoc(___,Name,Value)OptimizeHyperparameters аргумент пары имя-значение и использовать линейные или двоичные ученики ядра. Для других Learners, HyperparameterOptimizationResults имущество Mdl содержит результаты.
Обучение модели многоклассных выходных кодов с исправлением ошибок (ECOC) с использованием двоичных обучающихся вспомогательных векторных машин (SVM).
Загрузите набор данных радужки Фишера. Укажите данные предиктора X и данные ответа Y.
load fisheriris
X = meas;
Y = species;Обучайте мультиклассную модель ECOC с помощью опций по умолчанию.
Mdl = fitcecoc(X,Y)
Mdl =
ClassificationECOC
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3x1 cell}
CodingName: 'onevsone'
Properties, Methods
Mdl является ClassificationECOC модель. По умолчанию fitcecoc использует двоичных учеников SVM и схему кодирования «один против одного». Вы можете получить доступ Mdl с использованием точечной нотации.
Отображение имен классов и матрицы проектирования кодирования.
Mdl.ClassNames
ans = 3x1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
CodingMat = Mdl.CodingMatrix
CodingMat = 3×3
1 1 0
-1 0 1
0 -1 -1
Схема кодирования «один против одного» для трех классов дает трех двоичных учеников. Столбцы CodingMat соответствуют ученикам, а строки - классам. Порядок классов совпадает с порядком в Mdl.ClassNames. Например, CodingMat(:,1) является [1; –1; 0] и указывает, что программное обеспечение обучает первого двоичного ученика SVM, используя все наблюдения, классифицированные как 'setosa' и 'versicolor'. Поскольку 'setosa' соответствует 1, это положительный класс; 'versicolor' соответствует –1так что это отрицательный класс.
Доступ к каждому двоичному ученику можно получить с помощью индексации ячеек и точечной нотации.
Mdl.BinaryLearners{1} % The first binary learnerans =
CompactClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [-1 1]
ScoreTransform: 'none'
Beta: [4x1 double]
Bias: 1.4492
KernelParameters: [1x1 struct]
Properties, Methods
Вычислите ошибку классификации повторной выборки.
error = resubLoss(Mdl)
error = 0.0067
Ошибка классификации данных обучения невелика, но классификатор может быть переоборудованной моделью. Можно выполнить перекрестную проверку классификатора с помощью crossval и вычислить ошибку классификации перекрестной проверки.
Обучение модели ECOC, состоящей из нескольких бинарных линейных классификационных моделей.
Загрузите набор данных NLP.
load nlpdataX является разреженной матрицей данных предиктора, и Y является категориальным вектором меток класса. В данных имеется более двух классов.
Создайте шаблон модели линейной классификации по умолчанию.
t = templateLinear();
Сведения о настройке значений по умолчанию см. в разделе Аргументы пары «имя-значение» на templateLinear страница.
Обучение модели ECOC, состоящей из нескольких бинарных линейных классификационных моделей, которые могут идентифицировать продукт с учетом частотного распределения слов на веб-странице документации. Для ускорения обучения перенесите данные предиктора и укажите, что наблюдения соответствуют столбцам.
X = X'; rng(1); % For reproducibility Mdl = fitcecoc(X,Y,'Learners',t,'ObservationsIn','columns')
Mdl =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: [1x13 categorical]
ScoreTransform: 'none'
BinaryLearners: {78x1 cell}
CodingMatrix: [13x78 double]
Properties, Methods
Можно также обучить модель ECOC, состоящую из моделей линейной классификации по умолчанию, используя 'Learners','Linear'.
Чтобы сохранить память, fitcecoc возвращает обученные модели ECOC, состоящие из учащихся линейной классификации в CompactClassificationECOC объекты модели.
Перекрестная проверка классификатора ECOC с двоичными учениками SVM и оценка обобщенной ошибки классификации.
Загрузите набор данных радужки Фишера. Укажите данные предиктора X и данные ответа Y.
load fisheriris X = meas; Y = species; rng(1); % For reproducibility
Создайте шаблон SVM и стандартизируйте предикторы.
t = templateSVM('Standardize',true)t =
Fit template for classification SVM.
Alpha: [0x1 double]
BoxConstraint: []
CacheSize: []
CachingMethod: ''
ClipAlphas: []
DeltaGradientTolerance: []
Epsilon: []
GapTolerance: []
KKTTolerance: []
IterationLimit: []
KernelFunction: ''
KernelScale: []
KernelOffset: []
KernelPolynomialOrder: []
NumPrint: []
Nu: []
OutlierFraction: []
RemoveDuplicates: []
ShrinkagePeriod: []
Solver: ''
StandardizeData: 1
SaveSupportVectors: []
VerbosityLevel: []
Version: 2
Method: 'SVM'
Type: 'classification'
t является шаблоном SVM. Большинство свойств объекта шаблона пусты. При обучении классификатору ECOC программное обеспечение устанавливает соответствующие свойства для их значений по умолчанию.
Выполните обучение классификатора ECOC и укажите порядок классов.
Mdl = fitcecoc(X,Y,'Learners',t,... 'ClassNames',{'setosa','versicolor','virginica'});
Mdl является ClassificationECOC классификатор. Доступ к его свойствам можно получить с помощью точечной нотации.
Перекрестная проверка Mdl с использованием 10-кратной перекрестной проверки.
CVMdl = crossval(Mdl);
CVMdl является ClassificationPartitionedECOC перекрестно проверенный классификатор ECOC.
Оцените обобщенную ошибку классификации.
genError = kfoldLoss(CVMdl)
genError = 0.0400
Обобщённая ошибка классификации составляет 4%, что указывает на то, что классификатор ECOC достаточно хорошо обобщается.
Обучение классификатора ECOC с использованием двоичных учеников SVM. Сначала спрогнозируйте метки тренировочной выборки и апостериорные вероятности классов. Затем предсказать максимальную апостериорную вероятность класса в каждой точке сетки. Визуализация результатов.
Загрузите набор данных радужки Фишера. Укажите размеры лепестков в качестве предикторов и названия видов в качестве ответа.
load fisheriris X = meas(:,3:4); Y = species; rng(1); % For reproducibility
Создайте шаблон SVM. Стандартизируйте предикторы и укажите гауссово ядро.
t = templateSVM('Standardize',true,'KernelFunction','gaussian');
t является шаблоном SVM. Большинство его свойств пусты. Когда программное обеспечение обучает классификатор ECOC, оно устанавливает соответствующие свойства для их значений по умолчанию.
Обучение классификатора ECOC с использованием шаблона SVM. Преобразовать оценки классификации в апостериорные вероятности класса (которые возвращаются predict или resubPredict) с использованием 'FitPosterior' аргумент пары имя-значение. Укажите порядок классов с помощью 'ClassNames' аргумент пары имя-значение. Отображение диагностических сообщений во время обучения с помощью 'Verbose' аргумент пары имя-значение.
Mdl = fitcecoc(X,Y,'Learners',t,'FitPosterior',true,... 'ClassNames',{'setosa','versicolor','virginica'},... 'Verbose',2);
Training binary learner 1 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 2 Positive class indices: 1 Fitting posterior probabilities for learner 1 (SVM). Training binary learner 2 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 3 Positive class indices: 1 Fitting posterior probabilities for learner 2 (SVM). Training binary learner 3 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 3 Positive class indices: 2 Fitting posterior probabilities for learner 3 (SVM).
Mdl является ClassificationECOC модель. Один и тот же шаблон SVM применяется к каждому двоичному ученику, но можно настроить параметры для каждого двоичного ученика, передав вектор ячеек шаблонов.
Предсказать метки обучающей выборки и апостериорные вероятности класса. Отображать диагностические сообщения при вычислении меток и апостериорных вероятностей классов с помощью 'Verbose' аргумент пары имя-значение.
[label,~,~,Posterior] = resubPredict(Mdl,'Verbose',1);Predictions from all learners have been computed. Loss for all observations has been computed. Computing posterior probabilities...
Mdl.BinaryLoss
ans = 'quadratic'
Программное обеспечение назначает наблюдение классу, которое дает наименьшие средние двоичные потери. Поскольку все двоичные ученики вычисляют апостериорные вероятности, функция двоичных потерь quadratic.
Отображение случайного набора результатов.
idx = randsample(size(X,1),10,1); Mdl.ClassNames
ans = 3x1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
table(Y(idx),label(idx),Posterior(idx,:),... 'VariableNames',{'TrueLabel','PredLabel','Posterior'})
ans=10×3 table
TrueLabel PredLabel Posterior
______________ ______________ ______________________________________
{'virginica' } {'virginica' } 0.0039322 0.003987 0.99208
{'virginica' } {'virginica' } 0.017067 0.018263 0.96467
{'virginica' } {'virginica' } 0.014948 0.015856 0.9692
{'versicolor'} {'versicolor'} 2.2197e-14 0.87318 0.12682
{'setosa' } {'setosa' } 0.999 0.00025092 0.00074638
{'versicolor'} {'virginica' } 2.2195e-14 0.05943 0.94057
{'versicolor'} {'versicolor'} 2.2194e-14 0.97001 0.029985
{'setosa' } {'setosa' } 0.999 0.00024991 0.0007474
{'versicolor'} {'versicolor'} 0.0085642 0.98259 0.0088487
{'setosa' } {'setosa' } 0.999 0.00025013 0.00074717
Столбцы Posterior соответствуют порядку классов Mdl.ClassNames.
Определите сетку значений в наблюдаемом предикторном пространстве. Предсказать апостериорные вероятности для каждого случая в сетке.
xMax = max(X); xMin = min(X); x1Pts = linspace(xMin(1),xMax(1)); x2Pts = linspace(xMin(2),xMax(2)); [x1Grid,x2Grid] = meshgrid(x1Pts,x2Pts); [~,~,~,PosteriorRegion] = predict(Mdl,[x1Grid(:),x2Grid(:)]);
Для каждой координаты на сетке постройте график максимальной апостериорной вероятности класса среди всех классов.
contourf(x1Grid,x2Grid,... reshape(max(PosteriorRegion,[],2),size(x1Grid,1),size(x1Grid,2))); h = colorbar; h.YLabel.String = 'Maximum posterior'; h.YLabel.FontSize = 15; hold on gh = gscatter(X(:,1),X(:,2),Y,'krk','*xd',8); gh(2).LineWidth = 2; gh(3).LineWidth = 2; title('Iris Petal Measurements and Maximum Posterior') xlabel('Petal length (cm)') ylabel('Petal width (cm)') axis tight legend(gh,'Location','NorthWest') hold off

Обучение классификатора ECOC «один против всех» с помощью GentleBoost ансамбль деревьев решений с суррогатными расколами. Чтобы ускорить обучение, используйте числовые предикторы и параллельные вычисления. Binning допустим только тогда, когда fitcecoc использует учащегося дерева. После обучения оцените ошибку классификации, используя 10-кратную перекрестную проверку. Обратите внимание, что параллельные вычисления требуют Toolbox™ параллельных вычислений.
Загрузить данные образца
Загрузить и осмотреть arrhythmia набор данных.
load arrhythmia
[n,p] = size(X)n = 452
p = 279
isLabels = unique(Y); nLabels = numel(isLabels)
nLabels = 13
tabulate(categorical(Y))
Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
Набор данных содержит 279 предикторы и размер выборки 452 относительно невелик. Из 16 различных меток только 13 представлены в ответе (Y). Каждая метка описывает различные степени аритмии, и 54,20% наблюдений находятся в классе 1.
Классификатор ECOC по принципу «один против всех»
Создайте шаблон ансамбля. Необходимо указать как минимум три аргумента: метод, количество обучающихся и тип обучающегося. В этом примере укажите 'GentleBoost' для метода, 100 для количества учеников и шаблона дерева решений, в котором используются суррогатные разделения, поскольку отсутствуют наблюдения.
tTree = templateTree('surrogate','on'); tEnsemble = templateEnsemble('GentleBoost',100,tTree);
tEnsemble является объектом шаблона. Большинство его свойств пусты, но программа заполняет их значениями по умолчанию во время обучения.
Обучение классификатора ECOC «один против всех» с использованием ансамблей деревьев решений в качестве двоичных учеников. Для ускорения обучения используйте binning и параллельные вычисления.
Биннинг ('NumBins',50) - При наличии большого набора данных обучения можно ускорить обучение (потенциальное снижение точности) с помощью 'NumBins' аргумент пары имя-значение. Этот аргумент допустим только в том случае, если fitcecoc использует учащегося дерева. При указании 'NumBins' затем программное обеспечение помещает каждый числовой предиктор в заданное количество четких ячеек, а затем выращивает деревья на индексах ячеек вместо исходных данных. Вы можете попробовать 'NumBins',50 сначала, а затем измените 'NumBins' значение в зависимости от точности и скорости тренировки.
Параллельные вычисления ('Options',statset('UseParallel',true)) - С помощью лицензии Parallel Computing Toolbox можно ускорить вычисления, используя параллельные вычисления, которые отправляют каждого двоичного ученика работнику в пуле. Количество работников зависит от конфигурации системы. Когда вы используете деревья принятия решений для двоичных учеников, fitcecoc параллельное обучение с использованием стандартных блоков Intel ® Threading Building Blocks (TBB) для двухъядерных систем и выше. Поэтому указание 'UseParallel' не полезен на одном компьютере. Используйте этот параметр в кластере.
Дополнительно укажите, что предшествующие вероятности являются 1/K, где K = 13 - количество отдельных классов.
options = statset('UseParallel',true); Mdl = fitcecoc(X,Y,'Coding','onevsall','Learners',tEnsemble,... 'Prior','uniform','NumBins',50,'Options',options);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
Mdl является ClassificationECOC модель.
Перекрестная проверка
Перекрестная проверка классификатора ECOC с использованием 10-кратной перекрестной проверки.
CVMdl = crossval(Mdl,'Options',options);Warning: One or more folds do not contain points from all the groups.
CVMdl является ClassificationPartitionedECOC модель. Предупреждение указывает на то, что некоторые классы не представлены, в то время как программное обеспечение работает, по крайней мере, в один раз. Поэтому эти складки не могут предсказать метки для отсутствующих классов. Результаты гибки можно проверить с помощью индексации ячеек и точечной нотации. Например, для получения доступа к результатам первого сворачивания введите CVMdl.Trained{1}.
Используйте перекрестно проверенный классификатор ECOC для прогнозирования кратных меток проверки. Матрицу путаницы можно вычислить с помощью confusionchart. Переместите и измените размер диаграммы, изменив свойство внутренней позиции, чтобы проценты отображались в сводке строк.
oofLabel = kfoldPredict(CVMdl,'Options',options); ConfMat = confusionchart(Y,oofLabel,'RowSummary','total-normalized'); ConfMat.InnerPosition = [0.10 0.12 0.85 0.85];

Воспроизведение привязанных данных
Воспроизвести привязанные данные предиктора с помощью BinEdges свойство обучаемой модели и discretize функция.
X = Mdl.X; % Predictor data Xbinned = zeros(size(X)); edges = Mdl.BinEdges; % Find indices of binned predictors. idxNumeric = find(~cellfun(@isempty,edges)); if iscolumn(idxNumeric) idxNumeric = idxNumeric'; end for j = idxNumeric x = X(:,j); % Convert x to array if x is a table. if istable(x) x = table2array(x); end % Group x into bins by using the discretize function. xbinned = discretize(x,[-inf; edges{j}; inf]); Xbinned(:,j) = xbinned; end
Xbinned содержит индексы ячеек в диапазоне от 1 до числа ячеек для числовых предикторов. Xbinned значения 0 для категориальных предикторов. Если X содержит NaNs, затем соответствующее Xbinned значения NaNs.
Автоматическая оптимизация гиперпараметров с помощью fitcecoc.
Загрузить fisheriris набор данных.
load fisheriris
X = meas;
Y = species;Найдите гиперпараметры, которые минимизируют пятикратные потери при перекрестной проверке, используя автоматическую оптимизацию гиперпараметров. Для воспроизводимости задайте случайное начальное число и используйте 'expected-improvement-plus' функция приобретения.
rng default Mdl = fitcecoc(X,Y,'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName',... 'expected-improvement-plus'))
|====================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Coding | BoxConstraint| KernelScale | | | result | | runtime | (observed) | (estim.) | | | | |====================================================================================================================| | 1 | Best | 0.10667 | 1.4019 | 0.10667 | 0.10667 | onevsone | 5.6939 | 200.36 | | 2 | Best | 0.066667 | 4.3304 | 0.066667 | 0.068735 | onevsone | 94.849 | 0.0032549 | | 3 | Accept | 0.08 | 0.4065 | 0.066667 | 0.066837 | onevsall | 0.01378 | 0.076021 | | 4 | Accept | 0.08 | 0.33179 | 0.066667 | 0.066676 | onevsall | 889 | 38.798 | | 5 | Best | 0.04 | 0.422 | 0.04 | 0.040502 | onevsone | 0.021561 | 0.01569 | | 6 | Accept | 0.04 | 0.33279 | 0.04 | 0.039999 | onevsone | 0.48338 | 0.02941 | | 7 | Accept | 0.04 | 0.35478 | 0.04 | 0.039989 | onevsone | 305.45 | 0.18647 | | 8 | Best | 0.026667 | 0.31222 | 0.026667 | 0.026674 | onevsone | 0.0010168 | 0.10757 | | 9 | Accept | 0.086667 | 0.29807 | 0.026667 | 0.026669 | onevsone | 0.001007 | 0.3275 | | 10 | Accept | 0.046667 | 1.3637 | 0.026667 | 0.026673 | onevsone | 736.18 | 0.071026 | | 11 | Accept | 0.04 | 0.33235 | 0.026667 | 0.035679 | onevsone | 35.928 | 0.13079 | | 12 | Accept | 0.033333 | 0.27242 | 0.026667 | 0.030065 | onevsone | 0.0017593 | 0.11245 | | 13 | Accept | 0.026667 | 0.26702 | 0.026667 | 0.026544 | onevsone | 0.0011306 | 0.062222 | | 14 | Accept | 0.026667 | 0.24452 | 0.026667 | 0.026089 | onevsone | 0.0011124 | 0.079161 | | 15 | Accept | 0.026667 | 0.2858 | 0.026667 | 0.026184 | onevsone | 0.0014395 | 0.073096 | | 16 | Best | 0.02 | 0.32467 | 0.02 | 0.021144 | onevsone | 0.0010299 | 0.035054 | | 17 | Accept | 0.02 | 0.319 | 0.02 | 0.020431 | onevsone | 0.0010379 | 0.03138 | | 18 | Accept | 0.033333 | 0.27855 | 0.02 | 0.024292 | onevsone | 0.0011889 | 0.02915 | | 19 | Accept | 0.02 | 0.24725 | 0.02 | 0.022327 | onevsone | 0.0011336 | 0.042445 | | 20 | Best | 0.013333 | 0.30737 | 0.013333 | 0.020178 | onevsone | 0.0010854 | 0.048345 | |====================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Coding | BoxConstraint| KernelScale | | | result | | runtime | (observed) | (estim.) | | | | |====================================================================================================================| | 21 | Accept | 0.5 | 14.32 | 0.013333 | 0.020718 | onevsall | 689.42 | 0.001007 | | 22 | Accept | 0.33333 | 0.24297 | 0.013333 | 0.018299 | onevsall | 0.0011091 | 1.2155 | | 23 | Accept | 0.33333 | 0.25919 | 0.013333 | 0.017851 | onevsall | 529.11 | 372.18 | | 24 | Accept | 0.04 | 0.24993 | 0.013333 | 0.017879 | onevsone | 853.41 | 22.141 | | 25 | Accept | 0.046667 | 0.29265 | 0.013333 | 0.018114 | onevsone | 744.03 | 6.3339 | | 26 | Accept | 0.10667 | 0.28146 | 0.013333 | 0.018226 | onevsone | 0.0010775 | 999.54 | | 27 | Accept | 0.04 | 0.33384 | 0.013333 | 0.018557 | onevsone | 0.0020893 | 0.001005 | | 28 | Accept | 0.10667 | 0.2509 | 0.013333 | 0.019634 | onevsone | 0.0010666 | 12.404 | | 29 | Accept | 0.32 | 13.874 | 0.013333 | 0.018352 | onevsall | 951.6 | 0.027202 | | 30 | Accept | 0.04 | 0.26214 | 0.013333 | 0.018597 | onevsone | 936.87 | 1.7813 |

__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 68.6281 seconds
Total objective function evaluation time: 42.7994
Best observed feasible point:
Coding BoxConstraint KernelScale
________ _____________ ___________
onevsone 0.0010854 0.048345
Observed objective function value = 0.013333
Estimated objective function value = 0.018594
Function evaluation time = 0.30737
Best estimated feasible point (according to models):
Coding BoxConstraint KernelScale
________ _____________ ___________
onevsone 0.0011336 0.042445
Estimated objective function value = 0.018597
Estimated function evaluation time = 0.28751
Mdl =
ClassificationECOC
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3x1 cell}
CodingName: 'onevsone'
HyperparameterOptimizationResults: [1x1 BayesianOptimization]
Properties, Methods
Создайте две многоклассовые модели ECOC, обученные на высоких данных. Используйте линейные двоичные обучающиеся для одной из моделей и двоичные обучающиеся ядра для другой. Сравните ошибку классификации повторного замещения двух моделей.
Как правило, мультиклассовую классификацию высоких данных можно выполнить с помощью fitcecoc с линейными или бинарными учениками ядра. При использовании fitcecoc для обучения модели в массивах уровня нельзя использовать двоичных обучающихся SVM напрямую. Однако можно использовать линейные или бинарные модели классификации ядра, использующие SVM.
При выполнении вычислений в массивах TALL MATLAB ® использует либо параллельный пул (по умолчанию при наличии Toolbox™ Parallel Computing), либо локальный сеанс MATLAB. Если требуется выполнить пример с использованием локального сеанса MATLAB при наличии панели инструментов Parallel Computing Toolbox, можно изменить глобальную среду выполнения с помощью mapreducer функция.
Создайте хранилище данных, которое ссылается на папку, содержащую набор данных радужки Фишера. Определить 'NA' значения как отсутствующие данные, так что datastore заменяет их на NaN значения. Создайте высокие версии данных предиктора и ответа.
ds = datastore('fisheriris.csv','TreatAsMissing','NA'); t = tall(ds);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
X = [t.SepalLength t.SepalWidth t.PetalLength t.PetalWidth]; Y = t.Species;
Стандартизация данных предиктора.
Z = zscore(X);
Обучение мультиклассной модели ECOC, в которой используются высокие данные и линейные двоичные ученики. По умолчанию при передаче массивов tall в fitcecoc, программное обеспечение обучает линейных двоичных учеников, которые используют SVM. Поскольку данные ответа содержат только три уникальных класса, измените схему кодирования с «один против всех» (которая используется по умолчанию при использовании данных высокого уровня) на «один против одного» (которая используется по умолчанию при использовании данных в памяти).
Для воспроизводимости задайте начальные значения генераторов случайных чисел с помощью rng и tallrng. Результаты могут варьироваться в зависимости от количества работников и среды выполнения для массивов tall. Дополнительные сведения см. в разделе Управление местом запуска кода.
rng('default') tallrng('default') mdlLinear = fitcecoc(Z,Y,'Coding','onevsone')
Training binary learner 1 (Linear) out of 3. Training binary learner 2 (Linear) out of 3. Training binary learner 3 (Linear) out of 3.
mdlLinear =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingMatrix: [3×3 double]
Properties, Methods
mdlLinear является CompactClassificationECOC модель, состоящая из трех двоичных учеников.
Обучение мультиклассной модели ECOC, использующей высокие данные и двоичных учеников ядра. Сначала создайте templateKernel объект для задания свойств двоичных обучающихся ядра; в частности, увеличить число размеров расширения до .
tKernel = templateKernel('NumExpansionDimensions',2^16)tKernel =
Fit template for classification Kernel.
BetaTolerance: []
BlockSize: []
BoxConstraint: []
Epsilon: []
NumExpansionDimensions: 65536
GradientTolerance: []
HessianHistorySize: []
IterationLimit: []
KernelScale: []
Lambda: []
Learner: 'svm'
LossFunction: []
Stream: []
VerbosityLevel: []
Version: 1
Method: 'Kernel'
Type: 'classification'
По умолчанию двоичные ученики ядра используют SVM.
Пройти templateKernel объект в fitcecoc и изменить схему кодирования на «один против одного».
mdlKernel = fitcecoc(Z,Y,'Learners',tKernel,'Coding','onevsone')
Training binary learner 1 (Kernel) out of 3. Training binary learner 2 (Kernel) out of 3. Training binary learner 3 (Kernel) out of 3.
mdlKernel =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingMatrix: [3×3 double]
Properties, Methods
mdlKernel также является CompactClassificationECOC модель, состоящая из трех двоичных учеников.
Сравните ошибку классификации повторного замещения двух моделей.
errorLinear = gather(loss(mdlLinear,Z,Y))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.4 sec Evaluation completed in 1.6 sec
errorLinear = 0.0333
errorKernel = gather(loss(mdlKernel,Z,Y))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 15 sec Evaluation completed in 16 sec
errorKernel = 0.0067
mdlKernel ошибочно классифицирует меньший процент данных обучения, чем mdlLinear.
fitcecoc поддерживает разреженные матрицы только для тренировочных моделей линейной классификации. Для всех остальных моделей вместо этого введите полную матрицу данных предиктора.
Схема кодирования является матрицей, где элементы направляют, какие классы обучаются каждым двоичным учеником, то есть как проблема мультикласса сводится к ряду двоичных проблем.
Каждая строка схемы кодирования соответствует определенному классу, и каждый столбец соответствует двоичному ученику. В схеме троичного кодирования для определенного столбца (или двоичного ученика):
Строка, содержащая 1, позволяет двоичному ученику сгруппировать все наблюдения в соответствующем классе в положительный класс.
Строка, содержащая -1, позволяет двоичному ученику сгруппировать все наблюдения в соответствующем классе в отрицательный класс.
Строка, содержащая 0, предписывает двоичному ученику игнорировать все наблюдения в соответствующем классе.
Оптимальны матрицы проектирования кодирования с большими, минимальными, попарными расстояниями строк на основе измерения Хэмминга. Для получения подробной информации о попарном расстоянии строки см. Матрицы проектирования случайного кодирования и [4].
В этой таблице описаны популярные схемы кодирования.
| Проект кодирования | Описание | Число обучающихся | Минимальное попарное расстояние между рядами |
|---|---|---|---|
| один против всех (OVA) | Для каждого двоичного ученика один класс является положительным, а остальные - отрицательными. Эта конструкция исчерпывает все комбинации положительных назначений классов. | K | 2 |
| один против одного (OVO) | Для каждого двоичного ученика один класс является положительным, другой отрицательным, а остальные игнорируются. Эта конструкция исчерпывает все комбинации назначений пар классов. | К (К - 1 )/2 | 1 |
| двоичный файл завершен | Эта конструкция разбивает классы на все бинарные комбинации и не игнорирует никакие классы. То есть все назначения классов | 2K – 1 – 1 | 2K – 2 |
| троичное завершение | Эта конструкция разбивает классы на все троичные комбинации. То есть все назначения классов | (3K – 2K + 1 + 1)/2 | 3K – 2 |
| порядковый | Для первого двоичного ученика первый класс отрицательный, а остальные положительные. Для второго двоичного ученика первые два класса отрицательные, а остальные положительные и так далее. | К - 1 | 1 |
| плотные случайные | Для каждого двоичного ученика программное обеспечение случайным образом распределяет классы в положительные или отрицательные классы, по крайней мере один из каждого типа. Дополнительные сведения см. в разделе Матрицы проектирования произвольного кодирования. | Случайный, но приблизительно 10 log2K | Переменная |
| разреженные случайные | Для каждого двоичного ученика программа случайным образом назначает классы как положительные или отрицательные с вероятностью 0,25 для каждого и игнорирует классы с вероятностью 0,5. Дополнительные сведения см. в разделе Матрицы проектирования произвольного кодирования. | Случайный, но примерно 15 log2K | Переменная |
Этот график сравнивает количество двоичных учеников для схем кодирования с увеличением К.
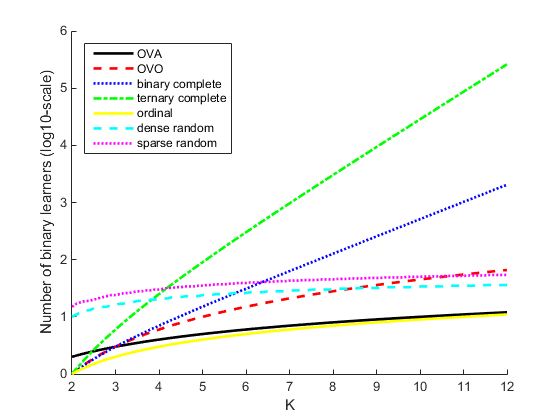
Число двоичных учеников растет с количеством классов. Для проблемы со многими классами, binarycomplete и ternarycomplete конструкции кодирования неэффективны. Однако:
Если K ≤ 4, то используйте ternarycomplete проект кодирования, а не sparserandom.
Если K ≤ 5, то используйте binarycomplete проект кодирования, а не denserandom.
Можно просмотреть матрицу проектирования кодирования обученного классификатора ECOC путем ввода Mdl.CodingMatrix в окне команд.
Вы должны сформировать матрицу кодирования, используя глубокое знание приложения и принимая во внимание вычислительные ограничения. Если у вас достаточно вычислительной мощности и времени, попробуйте несколько матриц кодирования и выберите одну с наилучшей производительностью (например, проверьте матрицы путаницы для каждой модели с помощью confusionchart).
Перекрестная проверка «оставить один» (Leaveout) неэффективно для наборов данных с множеством наблюдений. Вместо этого используйте k-кратную перекрестную проверку (KFold).
После обучения модели можно создать код C/C + +, который предсказывает метки для новых данных. Для создания кода C/C + + требуется Coder™ MATLAB. Дополнительные сведения см. в разделе Введение в создание кода .
[1] Allwein, E., R. Schapire и Y. Singer. «Сокращение мультиклассов до двоичных: унифицирующий подход к classifiers маржи». Журнал исследований машинного обучения. Том 1, 2000, стр. 113-141.
[2] Фюрнкранц, Йоханнес, «Круговая классификация». Дж. Мач. Рес., т. 2, 2002, стр. 721-747.
[3] Эскалера, С., О. Пужоль и П. Радева. «Процесс декодирования в выходных кодах с тройной коррекцией ошибок». Транзакции IEEE по анализу шаблонов и машинному интеллекту. Том 32, выпуск 7, 2010, стр. 120-134.
[4] Эскалера, С., О. Пужоль и П. Радева. «Разделяемость троичных кодов для разреженных конструкций выходных кодов с исправлением ошибок». Запись шаблона. Лет., том 30, выпуск 3, 2009, стр. 285-297.
ClassificationECOC | ClassificationPartitionedECOC | ClassificationPartitionedKernelECOC | ClassificationPartitionedLinearECOC | CompactClassificationECOC | designecoc | loss | predict | statset
